 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeResolving Out-of-Vocabulary Words with Bilingual Embeddings in Machine Translation
Aug 05, 2016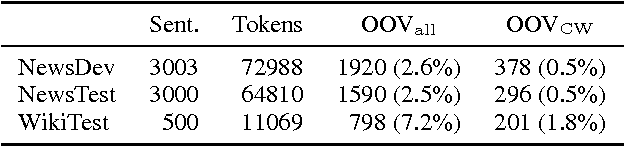
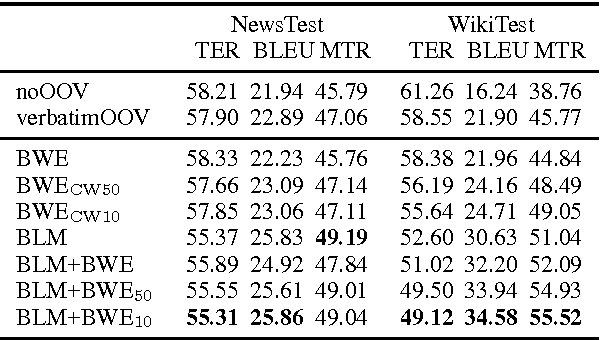

Out-of-vocabulary words account for a large proportion of errors in machine translation systems, especially when the system is used on a different domain than the one where it was trained. In order to alleviate the problem, we propose to use a log-bilinear softmax-based model for vocabulary expansion, such that given an out-of-vocabulary source word, the model generates a probabilistic list of possible translations in the target language. Our model uses only word embeddings trained on significantly large unlabelled monolingual corpora and trains over a fairly small, word-to-word bilingual dictionary. We input this probabilistic list into a standard phrase-based statistical machine translation system and obtain consistent improvements in translation quality on the English-Spanish language pair. Especially, we get an improvement of 3.9 BLEU points when tested over an out-of-domain test set.
Mapping Unseen Words to Task-Trained Embedding Spaces
Jun 23, 2016



We consider the supervised training setting in which we learn task-specific word embeddings. We assume that we start with initial embeddings learned from unlabelled data and update them to learn task-specific embeddings for words in the supervised training data. However, for new words in the test set, we must use either their initial embeddings or a single unknown embedding, which often leads to errors. We address this by learning a neural network to map from initial embeddings to the task-specific embedding space, via a multi-loss objective function. The technique is general, but here we demonstrate its use for improved dependency parsing (especially for sentences with out-of-vocabulary words), as well as for downstream improvements on sentiment analysis.
Structured Prediction with Output Embeddings for Semantic Image Annotation
Sep 07, 2015



We address the task of annotating images with semantic tuples. Solving this problem requires an algorithm which is able to deal with hundreds of classes for each argument of the tuple. In such contexts, data sparsity becomes a key challenge, as there will be a large number of classes for which only a few examples are available. We propose handling this by incorporating feature representations of both the inputs (images) and outputs (argument classes) into a factorized log-linear model, and exploiting the flexibility of scoring functions based on bilinear forms. Experiments show that integrating feature representations of the outputs in the structured prediction model leads to better overall predictions. We also conclude that the best output representation is specific for each type of argument.
Tailoring Word Embeddings for Bilexical Predictions: An Experimental Comparison
Apr 10, 2015


We investigate the problem of inducing word embeddings that are tailored for a particular bilexical relation. Our learning algorithm takes an existing lexical vector space and compresses it such that the resulting word embeddings are good predictors for a target bilexical relation. In experiments we show that task-specific embeddings can benefit both the quality and efficiency in lexical prediction tasks.