 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeResolving Out-of-Vocabulary Words with Bilingual Embeddings in Machine Translation
Paper and Code
Aug 05, 2016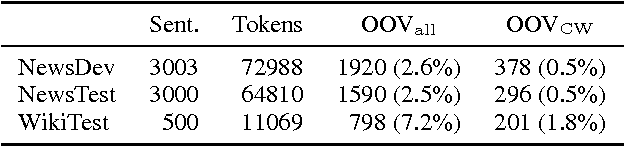
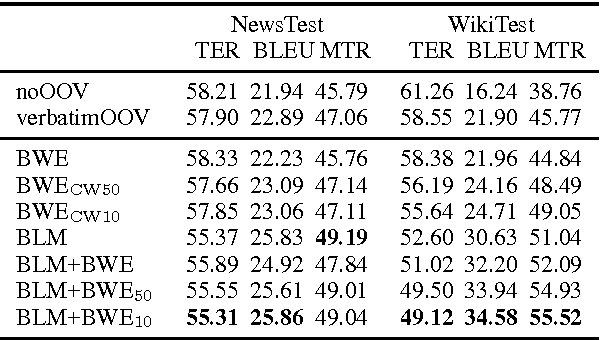

Out-of-vocabulary words account for a large proportion of errors in machine translation systems, especially when the system is used on a different domain than the one where it was trained. In order to alleviate the problem, we propose to use a log-bilinear softmax-based model for vocabulary expansion, such that given an out-of-vocabulary source word, the model generates a probabilistic list of possible translations in the target language. Our model uses only word embeddings trained on significantly large unlabelled monolingual corpora and trains over a fairly small, word-to-word bilingual dictionary. We input this probabilistic list into a standard phrase-based statistical machine translation system and obtain consistent improvements in translation quality on the English-Spanish language pair. Especially, we get an improvement of 3.9 BLEU points when tested over an out-of-domain test set.