 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMeasuring Alignment Bias in Neural Seq2Seq Semantic Parsers
Paper and Code
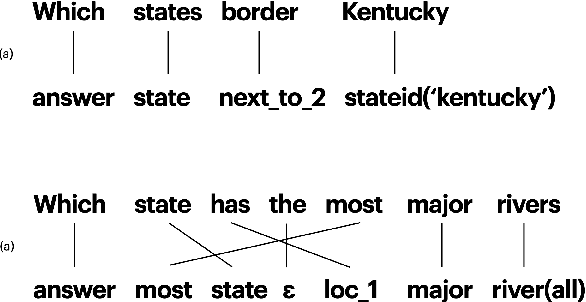
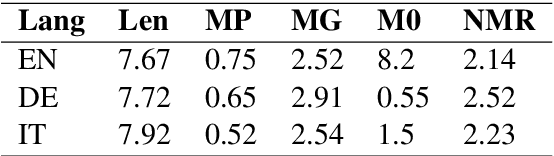
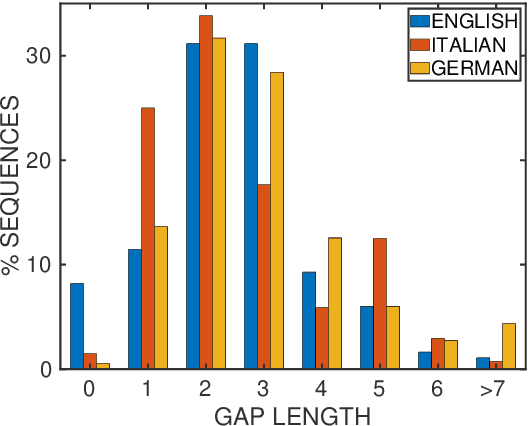
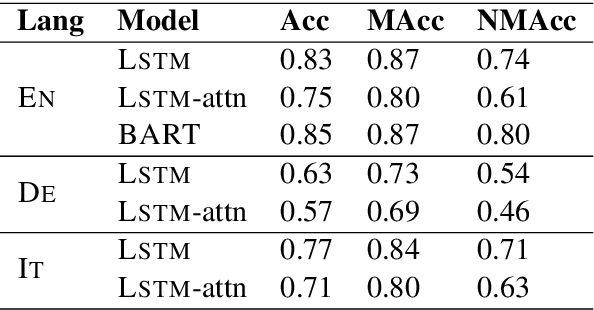
Prior to deep learning the semantic parsing community has been interested in understanding and modeling the range of possible word alignments between natural language sentences and their corresponding meaning representations. Sequence-to-sequence models changed the research landscape suggesting that we no longer need to worry about alignments since they can be learned automatically by means of an attention mechanism. More recently, researchers have started to question such premise. In this work we investigate whether seq2seq models can handle both simple and complex alignments. To answer this question we augment the popular Geo semantic parsing dataset with alignment annotations and create Geo-Aligned. We then study the performance of standard seq2seq models on the examples that can be aligned monotonically versus examples that require more complex alignments. Our empirical study shows that performance is significantly better over monotonic alignments.