Get our free extension to see links to code for papers anywhere online!Free add-on: code for papers everywhere!Free add-on: See code for papers anywhere!
 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLocal Loss Optimization in Operator Models: A New Insight into Spectral Learning
Paper and Code
Jun 27, 2012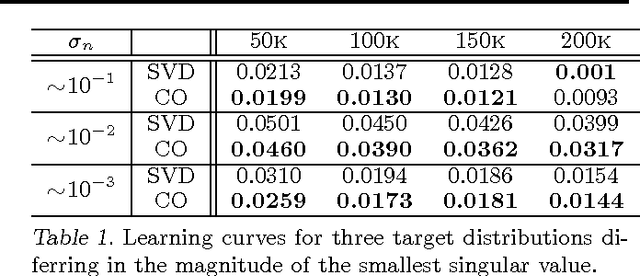
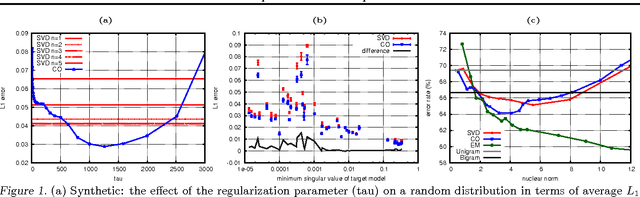
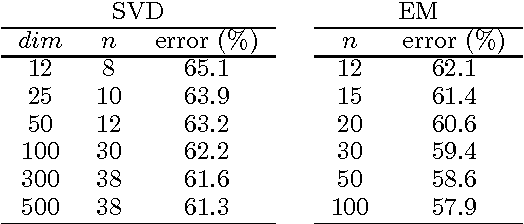
This paper re-visits the spectral method for learning latent variable models defined in terms of observable operators. We give a new perspective on the method, showing that operators can be recovered by minimizing a loss defined on a finite subset of the domain. A non-convex optimization similar to the spectral method is derived. We also propose a regularized convex relaxation of this optimization. We show that in practice the availabilty of a continuous regularization parameter (in contrast with the discrete number of states in the original method) allows a better trade-off between accuracy and model complexity. We also prove that in general, a randomized strategy for choosing the local loss will succeed with high probability.
* Appears in Proceedings of the 29th International Conference on
Machine Learning (ICML 2012)
View paper on