Get our free extension to see links to code for papers anywhere online!Free add-on: code for papers everywhere!Free add-on: See code for papers anywhere!
 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeBoosting Trees for Anti-Spam Email Filtering
Paper and Code
Sep 13, 2001
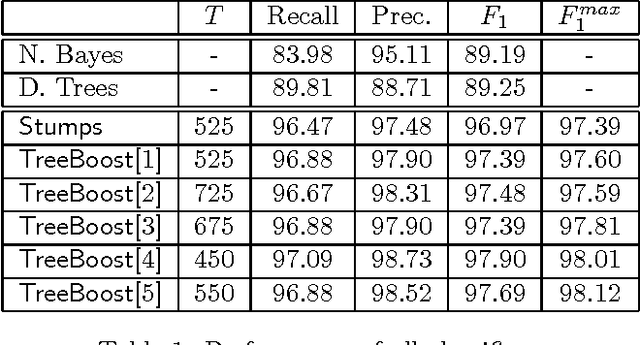
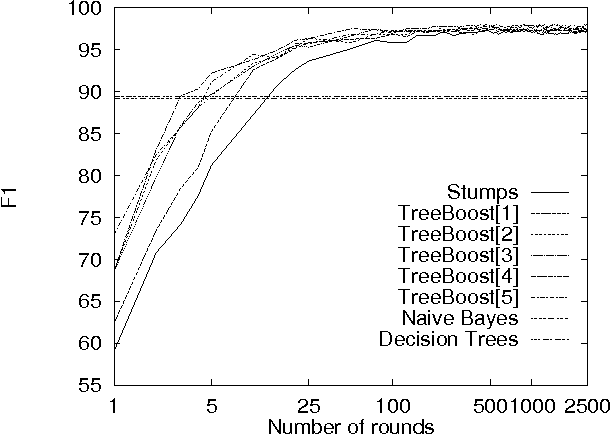
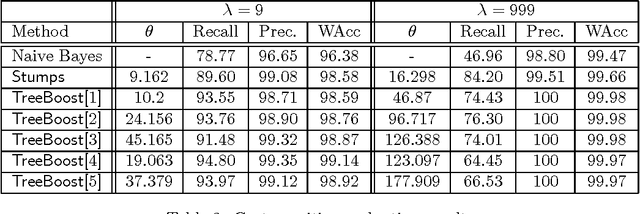
This paper describes a set of comparative experiments for the problem of automatically filtering unwanted electronic mail messages. Several variants of the AdaBoost algorithm with confidence-rated predictions [Schapire & Singer, 99] have been applied, which differ in the complexity of the base learners considered. Two main conclusions can be drawn from our experiments: a) The boosting-based methods clearly outperform the baseline learning algorithms (Naive Bayes and Induction of Decision Trees) on the PU1 corpus, achieving very high levels of the F1 measure; b) Increasing the complexity of the base learners allows to obtain better ``high-precision'' classifiers, which is a very important issue when misclassification costs are considered.
* Proceedings of RANLP-2001, pp. 58-64, Bulgaria, 2001 * 7 pages, 13 figures
View paper on