 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeIdioms, Probing and Dangerous Things: Towards Structural Probing for Idiomaticity in Vector Space
Apr 27, 2023The goal of this paper is to learn more about how idiomatic information is structurally encoded in embeddings, using a structural probing method. We repurpose an existing English verbal multi-word expression (MWE) dataset to suit the probing framework and perform a comparative probing study of static (GloVe) and contextual (BERT) embeddings. Our experiments indicate that both encode some idiomatic information to varying degrees, but yield conflicting evidence as to whether idiomaticity is encoded in the vector norm, leaving this an open question. We also identify some limitations of the used dataset and highlight important directions for future work in improving its suitability for a probing analysis.
Queer In AI: A Case Study in Community-Led Participatory AI
Apr 10, 2023We present Queer in AI as a case study for community-led participatory design in AI. We examine how participatory design and intersectional tenets started and shaped this community's programs over the years. We discuss different challenges that emerged in the process, look at ways this organization has fallen short of operationalizing participatory and intersectional principles, and then assess the organization's impact. Queer in AI provides important lessons and insights for practitioners and theorists of participatory methods broadly through its rejection of hierarchy in favor of decentralization, success at building aid and programs by and for the queer community, and effort to change actors and institutions outside of the queer community. Finally, we theorize how communities like Queer in AI contribute to the participatory design in AI more broadly by fostering cultures of participation in AI, welcoming and empowering marginalized participants, critiquing poor or exploitative participatory practices, and bringing participation to institutions outside of individual research projects. Queer in AI's work serves as a case study of grassroots activism and participatory methods within AI, demonstrating the potential of community-led participatory methods and intersectional praxis, while also providing challenges, case studies, and nuanced insights to researchers developing and using participatory methods.
Probing Taxonomic and Thematic Embeddings for Taxonomic Information
Jan 25, 2023Modelling taxonomic and thematic relatedness is important for building AI with comprehensive natural language understanding. The goal of this paper is to learn more about how taxonomic information is structurally encoded in embeddings. To do this, we design a new hypernym-hyponym probing task and perform a comparative probing study of taxonomic and thematic SGNS and GloVe embeddings. Our experiments indicate that both types of embeddings encode some taxonomic information, but the amount, as well as the geometric properties of the encodings, are independently related to both the encoder architecture, as well as the embedding training data. Specifically, we find that only taxonomic embeddings carry taxonomic information in their norm, which is determined by the underlying distribution in the data.
Is it worth it? Budget-related evaluation metrics for model selection
Jul 18, 2018
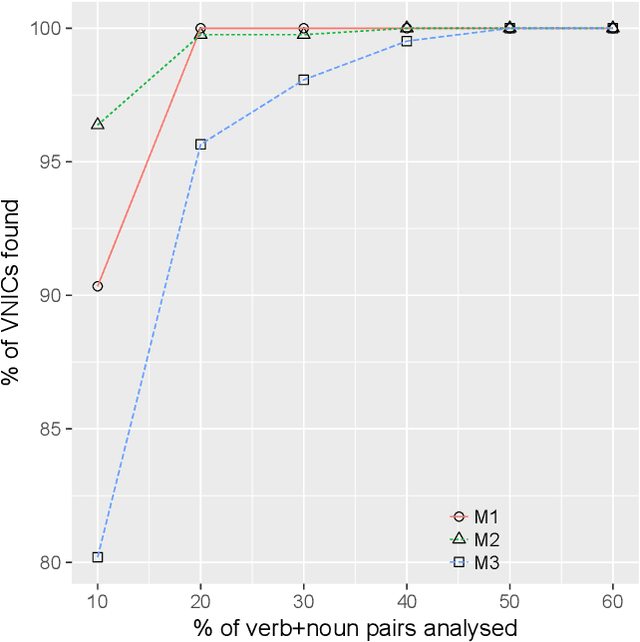
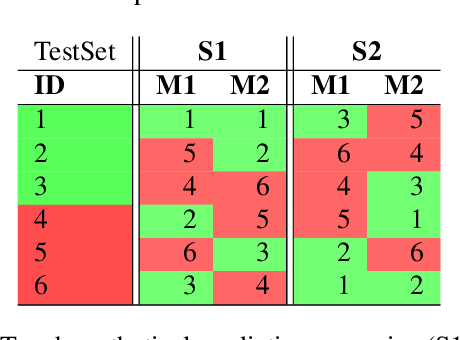

Creating a linguistic resource is often done by using a machine learning model that filters the content that goes through to a human annotator, before going into the final resource. However, budgets are often limited, and the amount of available data exceeds the amount of affordable annotation. In order to optimize the benefit from the invested human work, we argue that deciding on which model one should employ depends not only on generalized evaluation metrics such as F-score, but also on the gain metric. Because the model with the highest F-score may not necessarily have the best sequencing of predicted classes, this may lead to wasting funds on annotating false positives, yielding zero improvement of the linguistic resource. We exemplify our point with a case study, using real data from a task of building a verb-noun idiom dictionary. We show that, given the choice of three systems with varying F-scores, the system with the highest F-score does not yield the highest profits. In other words, in our case the cost-benefit trade off is more favorable for a system with a lower F-score.
Examining a hate speech corpus for hate speech detection and popularity prediction
May 12, 2018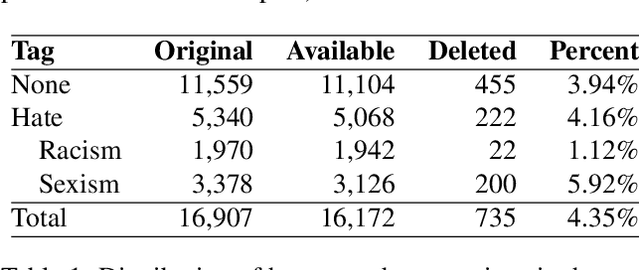
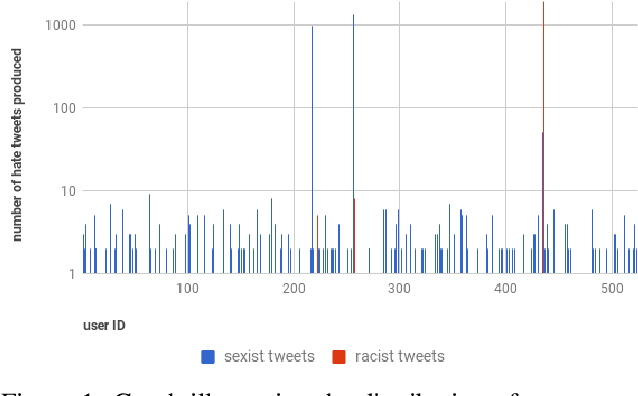
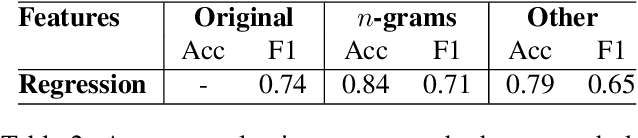
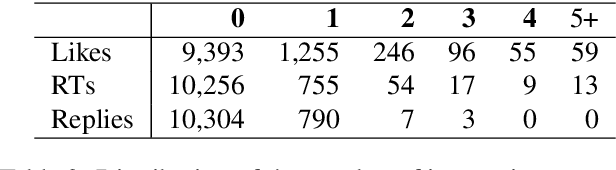
As research on hate speech becomes more and more relevant every day, most of it is still focused on hate speech detection. By attempting to replicate a hate speech detection experiment performed on an existing Twitter corpus annotated for hate speech, we highlight some issues that arise from doing research in the field of hate speech, which is essentially still in its infancy. We take a critical look at the training corpus in order to understand its biases, while also using it to venture beyond hate speech detection and investigate whether it can be used to shed light on other facets of research, such as popularity of hate tweets.
* 8 pages, 1 figure, 10 tables, published in proceedings of 4REAL2018: Workshop on Replicability and Reproducibility of Research Results in Science and Technology of Language
Quantitative Fine-Grained Human Evaluation of Machine Translation Systems: a Case Study on English to Croatian
Feb 02, 2018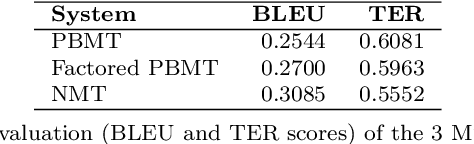
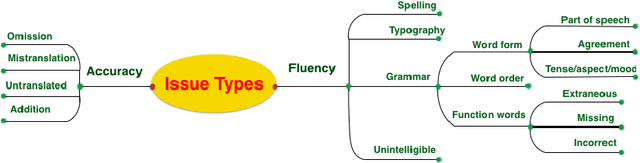
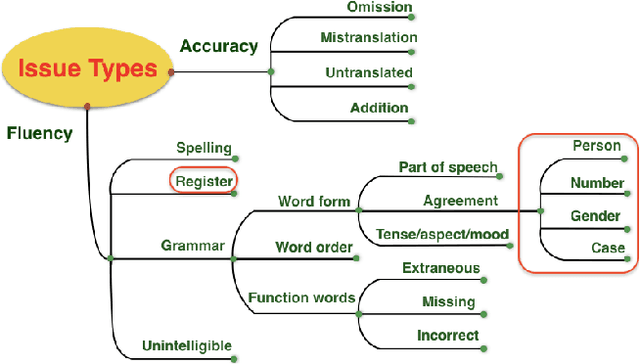
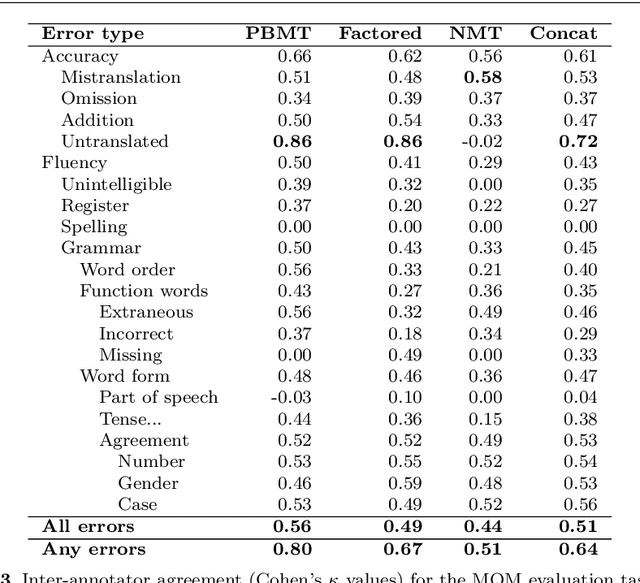
This paper presents a quantitative fine-grained manual evaluation approach to comparing the performance of different machine translation (MT) systems. We build upon the well-established Multidimensional Quality Metrics (MQM) error taxonomy and implement a novel method that assesses whether the differences in performance for MQM error types between different MT systems are statistically significant. We conduct a case study for English-to-Croatian, a language direction that involves translating into a morphologically rich language, for which we compare three MT systems belonging to different paradigms: pure phrase-based, factored phrase-based and neural. First, we design an MQM-compliant error taxonomy tailored to the relevant linguistic phenomena of Slavic languages, which made the annotation process feasible and accurate. Errors in MT outputs were then annotated by two annotators following this taxonomy. Subsequently, we carried out a statistical analysis which showed that the best-performing system (neural) reduces the errors produced by the worst system (pure phrase-based) by more than half (54\%). Moreover, we conducted an additional analysis of agreement errors in which we distinguished between short (phrase-level) and long distance (sentence-level) errors. We discovered that phrase-based MT approaches are of limited use for long distance agreement phenomena, for which neural MT was found to be especially effective.
* 22 pages, 2 figures, 9 tables, 1 equation. This is a post-peer-review, pre-copyedit version of an article published in Machine Translation Journal. The final authenticated version will be available online at the journal page. arXiv admin note: substantial text overlap with arXiv:1706.04389
Fine-grained human evaluation of neural versus phrase-based machine translation
Jun 14, 2017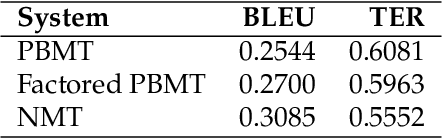
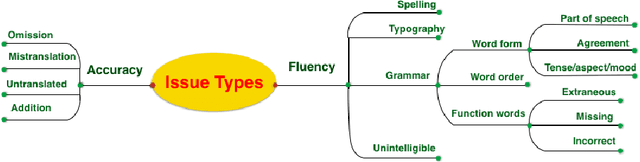
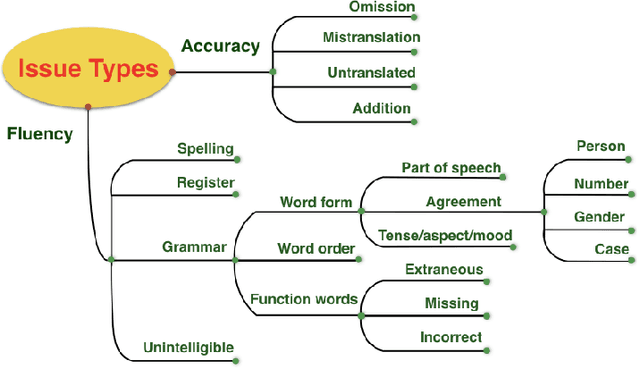
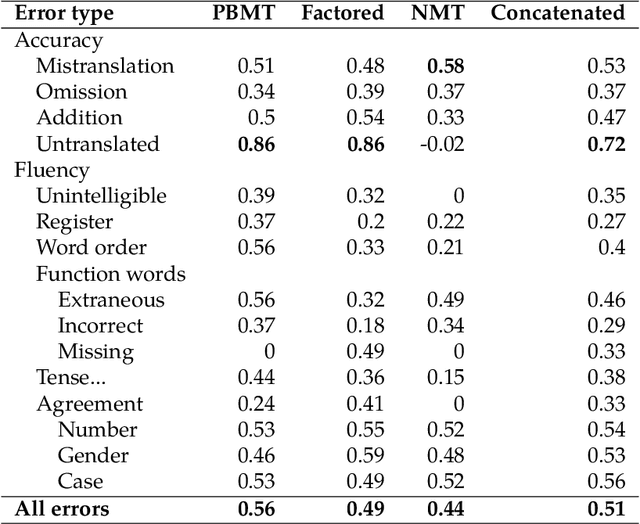
We compare three approaches to statistical machine translation (pure phrase-based, factored phrase-based and neural) by performing a fine-grained manual evaluation via error annotation of the systems' outputs. The error types in our annotation are compliant with the multidimensional quality metrics (MQM), and the annotation is performed by two annotators. Inter-annotator agreement is high for such a task, and results show that the best performing system (neural) reduces the errors produced by the worst system (phrase-based) by 54%.
* 12 pages, 2 figures, The Prague Bulletin of Mathematical Linguistics