 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCurated Datasets and Neural Models for Machine Translation of Informal Registers between Mayan and Spanish Vernaculars
Apr 11, 2024
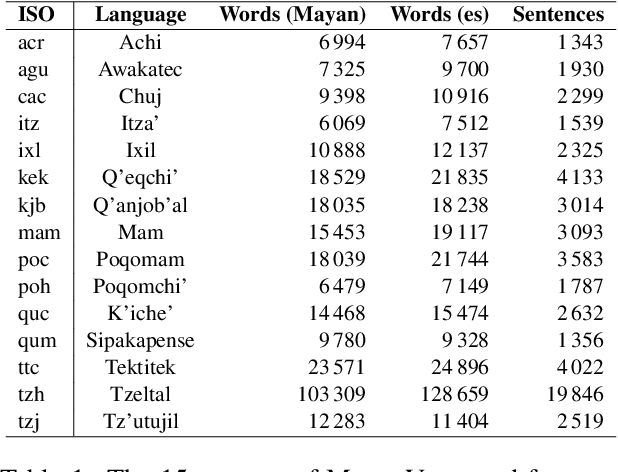

The Mayan languages comprise a language family with an ancient history, millions of speakers, and immense cultural value, that, nevertheless, remains severely underrepresented in terms of resources and global exposure. In this paper we develop, curate, and publicly release a set of corpora in several Mayan languages spoken in Guatemala and Southern Mexico, which we call MayanV. The datasets are parallel with Spanish, the dominant language of the region, and are taken from official native sources focused on representing informal, day-to-day, and non-domain-specific language. As such, and according to our dialectometric analysis, they differ in register from most other available resources. Additionally, we present neural machine translation models, trained on as many resources and Mayan languages as possible, and evaluated exclusively on our datasets. We observe lexical divergences between the dialects of Spanish in our resources and the more widespread written standard of Spanish, and that resources other than the ones we present do not seem to improve translation performance, indicating that many such resources may not accurately capture common, real-life language usage. The MayanV dataset is available at https://github.com/transducens/mayanv.
Non-Fluent Synthetic Target-Language Data Improve Neural Machine Translation
Jan 29, 2024When the amount of parallel sentences available to train a neural machine translation is scarce, a common practice is to generate new synthetic training samples from them. A number of approaches have been proposed to produce synthetic parallel sentences that are similar to those in the parallel data available. These approaches work under the assumption that non-fluent target-side synthetic training samples can be harmful and may deteriorate translation performance. Even so, in this paper we demonstrate that synthetic training samples with non-fluent target sentences can improve translation performance if they are used in a multilingual machine translation framework as if they were sentences in another language. We conducted experiments on ten low-resource and four high-resource translation tasks and found out that this simple approach consistently improves translation performance as compared to state-of-the-art methods for generating synthetic training samples similar to those found in corpora. Furthermore, this improvement is independent of the size of the original training corpus, the resulting systems are much more robust against domain shift and produce less hallucinations.
* arXiv admin note: text overlap with arXiv:2109.03645
Identifying Student Profiles Within Online Judge Systems Using Explainable Artificial Intelligence
Jan 29, 2024



Online Judge (OJ) systems are typically considered within programming-related courses as they yield fast and objective assessments of the code developed by the students. Such an evaluation generally provides a single decision based on a rubric, most commonly whether the submission successfully accomplished the assignment. Nevertheless, since in an educational context such information may be deemed insufficient, it would be beneficial for both the student and the instructor to receive additional feedback about the overall development of the task. This work aims to tackle this limitation by considering the further exploitation of the information gathered by the OJ and automatically inferring feedback for both the student and the instructor. More precisely, we consider the use of learning-based schemes -- particularly, multi-instance learning (MIL) and classical machine learning formulations -- to model student behavior. Besides, explainable artificial intelligence (XAI) is contemplated to provide human-understandable feedback. The proposal has been evaluated considering a case of study comprising 2500 submissions from roughly 90 different students from a programming-related course in a computer science degree. The results obtained validate the proposal: The model is capable of significantly predicting the user outcome (either passing or failing the assignment) solely based on the behavioral pattern inferred by the submissions provided to the OJ. Moreover, the proposal is able to identify prone-to-fail student groups and profiles as well as other relevant information, which eventually serves as feedback to both the student and the instructor.
Understanding the effects of word-level linguistic annotations in under-resourced neural machine translation
Jan 29, 2024


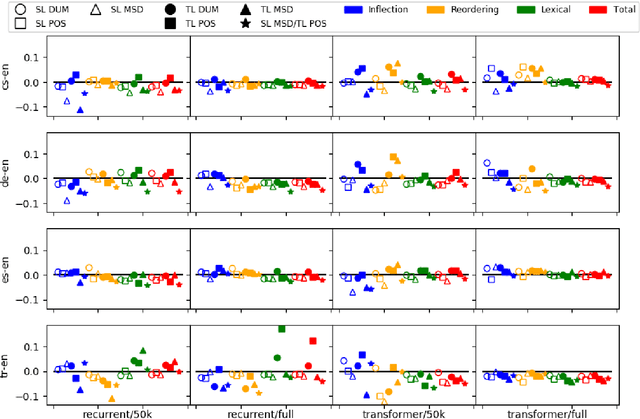
This paper studies the effects of word-level linguistic annotations in under-resourced neural machine translation, for which there is incomplete evidence in the literature. The study covers eight language pairs, different training corpus sizes, two architectures, and three types of annotation: dummy tags (with no linguistic information at all), part-of-speech tags, and morpho-syntactic description tags, which consist of part of speech and morphological features. These linguistic annotations are interleaved in the input or output streams as a single tag placed before each word. In order to measure the performance under each scenario, we use automatic evaluation metrics and perform automatic error classification. Our experiments show that, in general, source-language annotations are helpful and morpho-syntactic descriptions outperform part of speech for some language pairs. On the contrary, when words are annotated in the target language, part-of-speech tags systematically outperform morpho-syntactic description tags in terms of automatic evaluation metrics, even though the use of morpho-syntactic description tags improves the grammaticality of the output. We provide a detailed analysis of the reasons behind this result.
Cross-lingual neural fuzzy matching for exploiting target-language monolingual corpora in computer-aided translation
Jan 16, 2024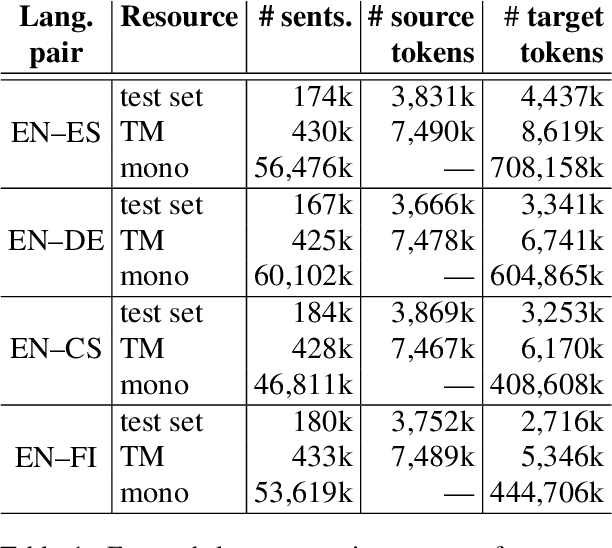

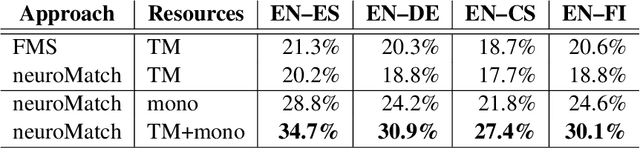
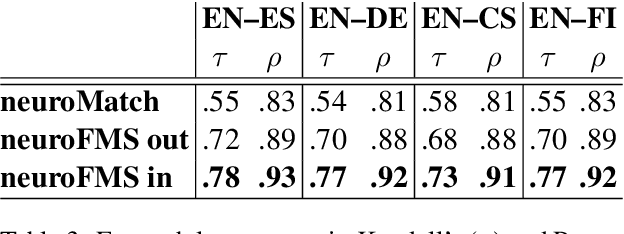
Computer-aided translation (CAT) tools based on translation memories (MT) play a prominent role in the translation workflow of professional translators. However, the reduced availability of in-domain TMs, as compared to in-domain monolingual corpora, limits its adoption for a number of translation tasks. In this paper, we introduce a novel neural approach aimed at overcoming this limitation by exploiting not only TMs, but also in-domain target-language (TL) monolingual corpora, and still enabling a similar functionality to that offered by conventional TM-based CAT tools. Our approach relies on cross-lingual sentence embeddings to retrieve translation proposals from TL monolingual corpora, and on a neural model to estimate their post-editing effort. The paper presents an automatic evaluation of these techniques on four language pairs that shows that our approach can successfully exploit monolingual texts in a TM-based CAT environment, increasing the amount of useful translation proposals, and that our neural model for estimating the post-editing effort enables the combination of translation proposals obtained from monolingual corpora and from TMs in the usual way. A human evaluation performed on a single language pair confirms the results of the automatic evaluation and seems to indicate that the translation proposals retrieved with our approach are more useful than what the automatic evaluation shows.
Rethinking Data Augmentation for Low-Resource Neural Machine Translation: A Multi-Task Learning Approach
Sep 08, 2021
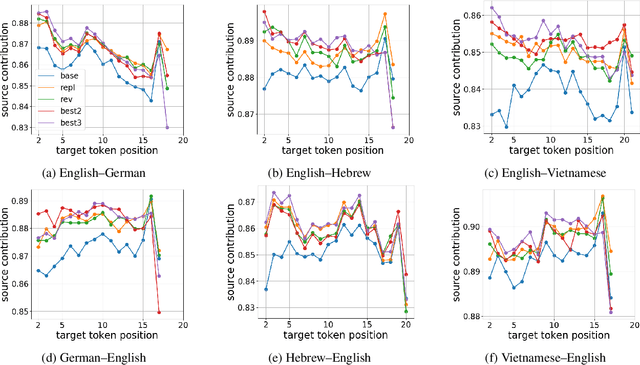
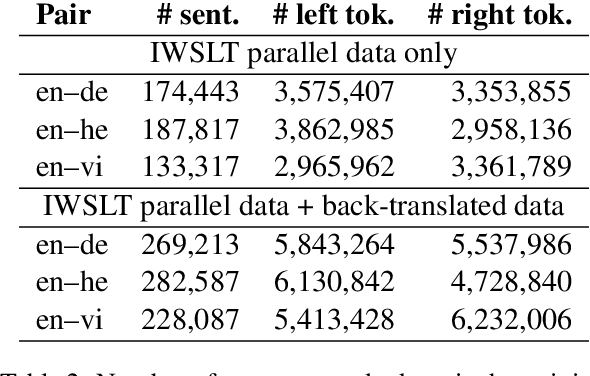
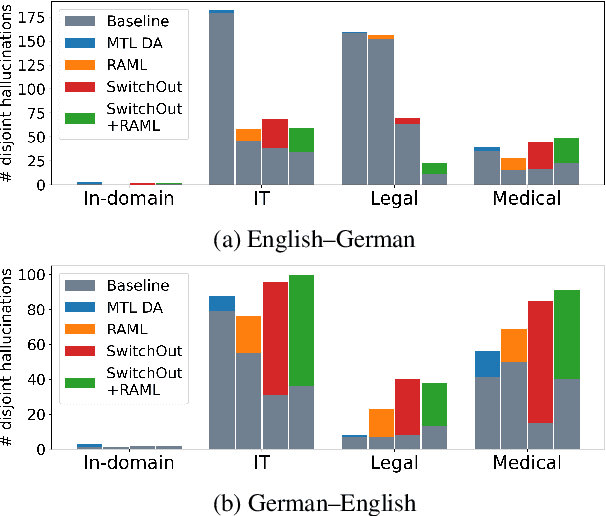
In the context of neural machine translation, data augmentation (DA) techniques may be used for generating additional training samples when the available parallel data are scarce. Many DA approaches aim at expanding the support of the empirical data distribution by generating new sentence pairs that contain infrequent words, thus making it closer to the true data distribution of parallel sentences. In this paper, we propose to follow a completely different approach and present a multi-task DA approach in which we generate new sentence pairs with transformations, such as reversing the order of the target sentence, which produce unfluent target sentences. During training, these augmented sentences are used as auxiliary tasks in a multi-task framework with the aim of providing new contexts where the target prefix is not informative enough to predict the next word. This strengthens the encoder and forces the decoder to pay more attention to the source representations of the encoder. Experiments carried out on six low-resource translation tasks show consistent improvements over the baseline and over DA methods aiming at extending the support of the empirical data distribution. The systems trained with our approach rely more on the source tokens, are more robust against domain shift and suffer less hallucinations.
Quantitative Fine-Grained Human Evaluation of Machine Translation Systems: a Case Study on English to Croatian
Feb 02, 2018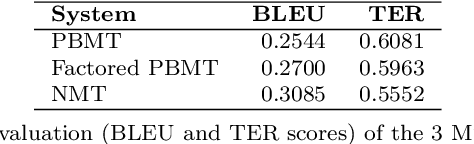
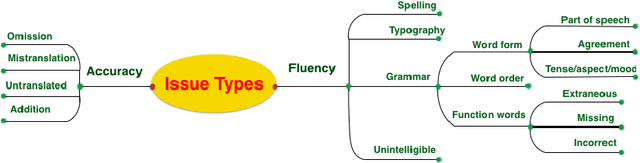
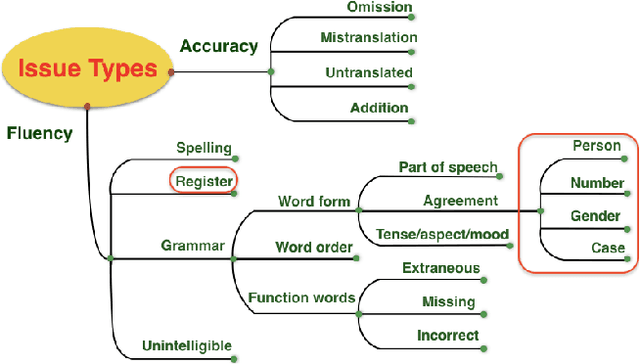
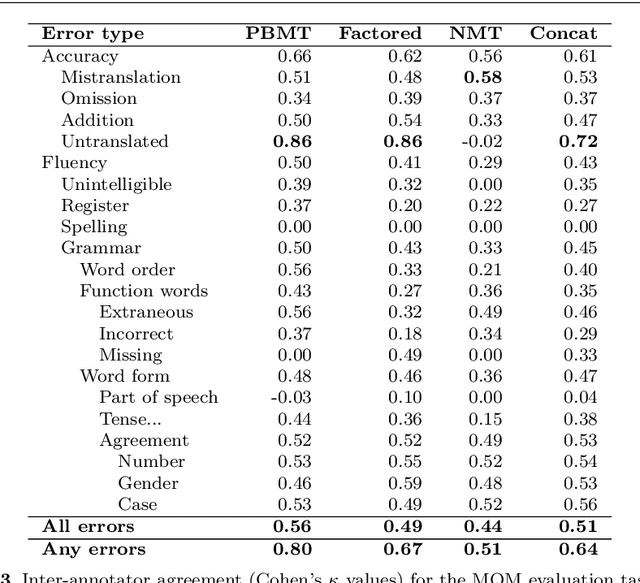
This paper presents a quantitative fine-grained manual evaluation approach to comparing the performance of different machine translation (MT) systems. We build upon the well-established Multidimensional Quality Metrics (MQM) error taxonomy and implement a novel method that assesses whether the differences in performance for MQM error types between different MT systems are statistically significant. We conduct a case study for English-to-Croatian, a language direction that involves translating into a morphologically rich language, for which we compare three MT systems belonging to different paradigms: pure phrase-based, factored phrase-based and neural. First, we design an MQM-compliant error taxonomy tailored to the relevant linguistic phenomena of Slavic languages, which made the annotation process feasible and accurate. Errors in MT outputs were then annotated by two annotators following this taxonomy. Subsequently, we carried out a statistical analysis which showed that the best-performing system (neural) reduces the errors produced by the worst system (pure phrase-based) by more than half (54\%). Moreover, we conducted an additional analysis of agreement errors in which we distinguished between short (phrase-level) and long distance (sentence-level) errors. We discovered that phrase-based MT approaches are of limited use for long distance agreement phenomena, for which neural MT was found to be especially effective.
* 22 pages, 2 figures, 9 tables, 1 equation. This is a post-peer-review, pre-copyedit version of an article published in Machine Translation Journal. The final authenticated version will be available online at the journal page. arXiv admin note: substantial text overlap with arXiv:1706.04389
Fine-grained human evaluation of neural versus phrase-based machine translation
Jun 14, 2017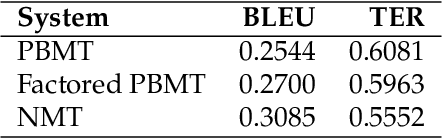
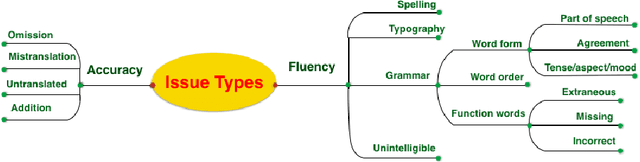
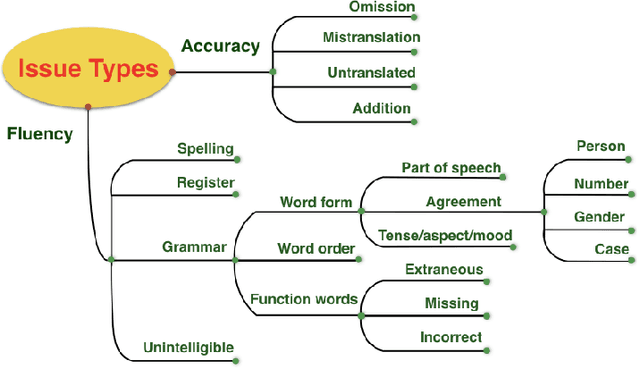
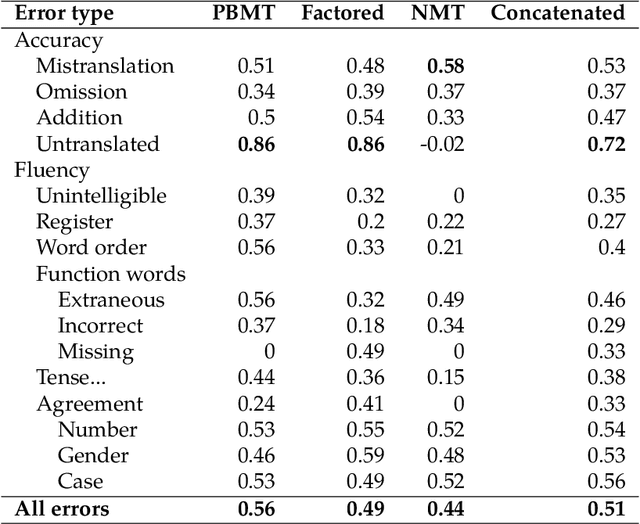
We compare three approaches to statistical machine translation (pure phrase-based, factored phrase-based and neural) by performing a fine-grained manual evaluation via error annotation of the systems' outputs. The error types in our annotation are compliant with the multidimensional quality metrics (MQM), and the annotation is performed by two annotators. Inter-annotator agreement is high for such a task, and results show that the best performing system (neural) reduces the errors produced by the worst system (phrase-based) by 54%.
* 12 pages, 2 figures, The Prague Bulletin of Mathematical Linguistics
A Multifaceted Evaluation of Neural versus Phrase-Based Machine Translation for 9 Language Directions
Jan 11, 2017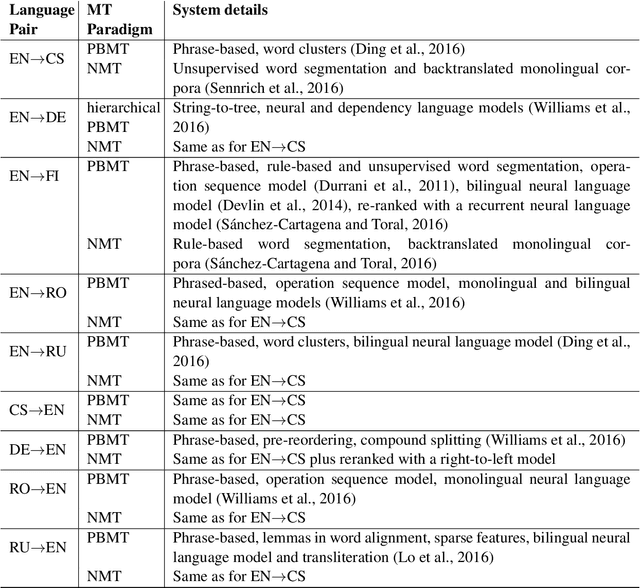
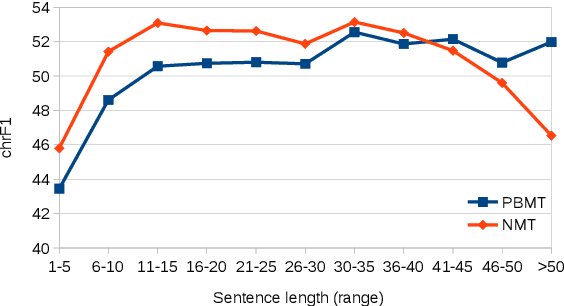
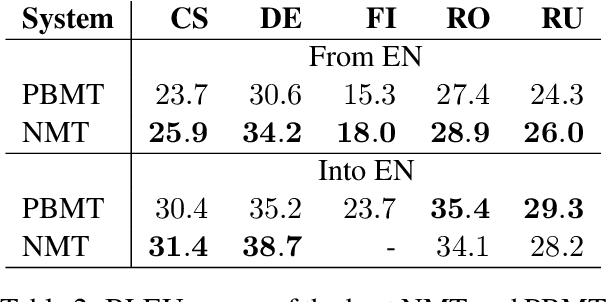
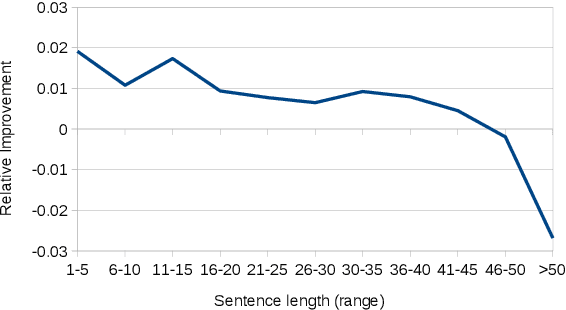
We aim to shed light on the strengths and weaknesses of the newly introduced neural machine translation paradigm. To that end, we conduct a multifaceted evaluation in which we compare outputs produced by state-of-the-art neural machine translation and phrase-based machine translation systems for 9 language directions across a number of dimensions. Specifically, we measure the similarity of the outputs, their fluency and amount of reordering, the effect of sentence length and performance across different error categories. We find out that translations produced by neural machine translation systems are considerably different, more fluent and more accurate in terms of word order compared to those produced by phrase-based systems. Neural machine translation systems are also more accurate at producing inflected forms, but they perform poorly when translating very long sentences.