 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCurated Datasets and Neural Models for Machine Translation of Informal Registers between Mayan and Spanish Vernaculars
Paper and Code

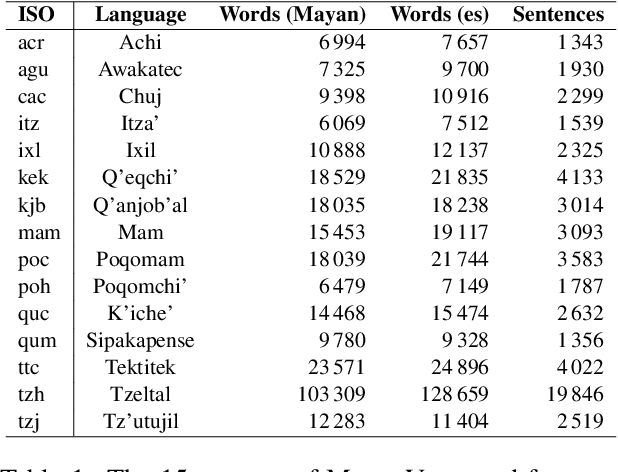
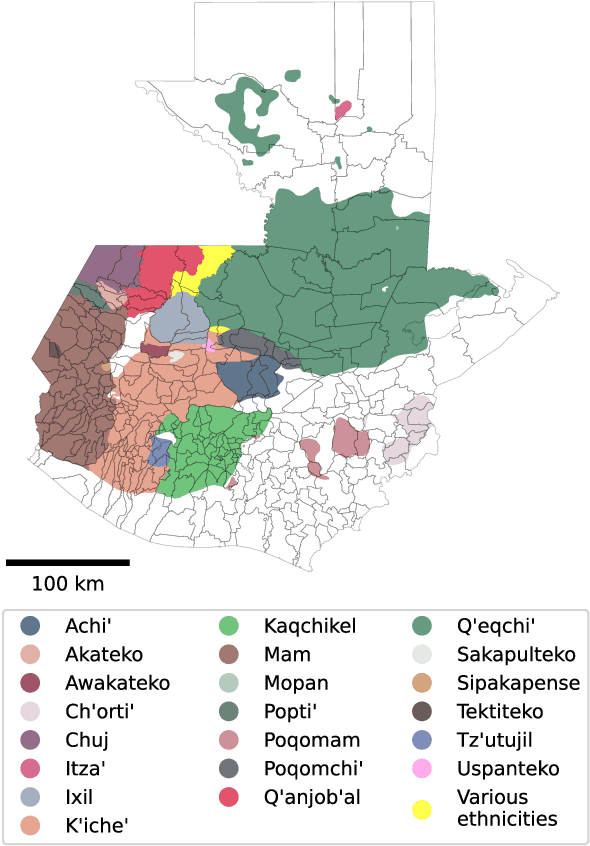

The Mayan languages comprise a language family with an ancient history, millions of speakers, and immense cultural value, that, nevertheless, remains severely underrepresented in terms of resources and global exposure. In this paper we develop, curate, and publicly release a set of corpora in several Mayan languages spoken in Guatemala and Southern Mexico, which we call MayanV. The datasets are parallel with Spanish, the dominant language of the region, and are taken from official native sources focused on representing informal, day-to-day, and non-domain-specific language. As such, and according to our dialectometric analysis, they differ in register from most other available resources. Additionally, we present neural machine translation models, trained on as many resources and Mayan languages as possible, and evaluated exclusively on our datasets. We observe lexical divergences between the dialects of Spanish in our resources and the more widespread written standard of Spanish, and that resources other than the ones we present do not seem to improve translation performance, indicating that many such resources may not accurately capture common, real-life language usage. The MayanV dataset is available at https://github.com/transducens/mayanv.