 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSmart Bilingual Focused Crawling of Parallel Documents
May 23, 2024
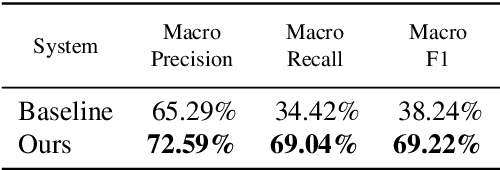

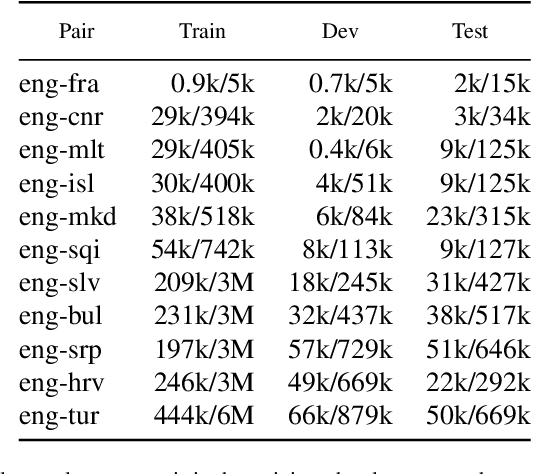
Crawling parallel texts $\unicode{x2014}$texts that are mutual translations$\unicode{x2014}$ from the Internet is usually done following a brute-force approach: documents are massively downloaded in an unguided process, and only a fraction of them end up leading to actual parallel content. In this work we propose a smart crawling method that guides the crawl towards finding parallel content more rapidly. Our approach builds on two different models: one that infers the language of a document from its URL, and another that infers whether a pair of URLs link to parallel documents. We evaluate both models in isolation and their integration into a crawling tool. The results demonstrate the individual effectiveness of both models and highlight that their combination enables the early discovery of parallel content during crawling, leading to a reduction in the amount of downloaded documents deemed useless, and yielding a greater quantity of parallel documents compared to conventional crawling approaches.
Curated Datasets and Neural Models for Machine Translation of Informal Registers between Mayan and Spanish Vernaculars
Apr 11, 2024
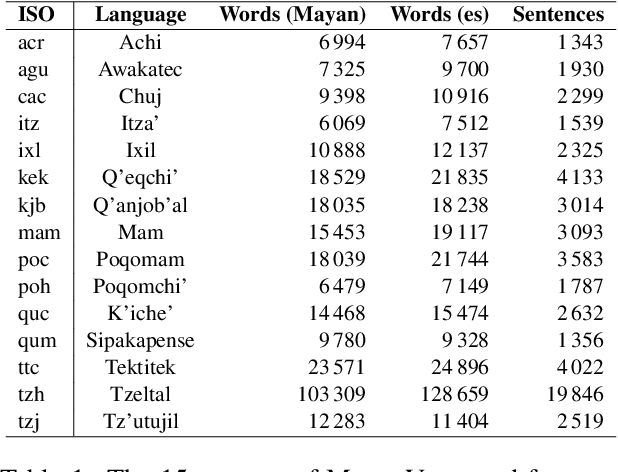
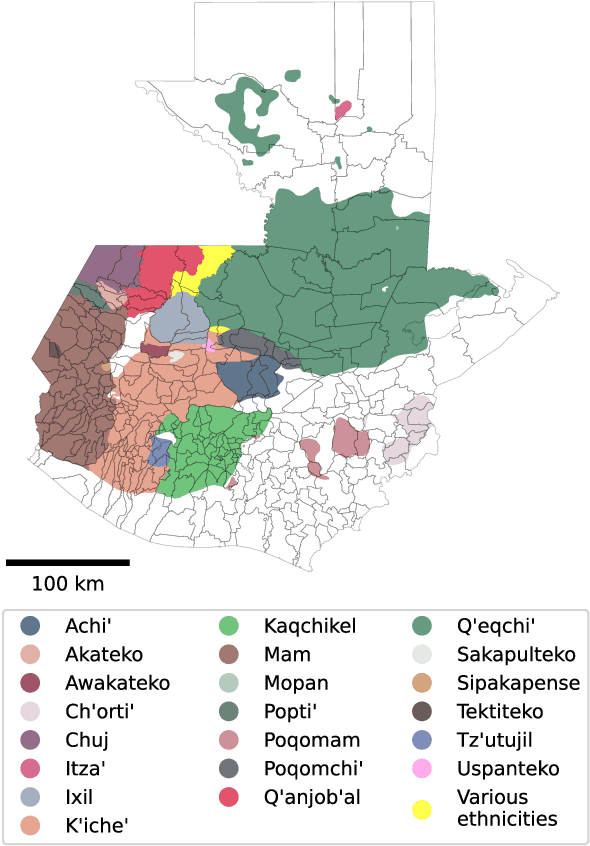

The Mayan languages comprise a language family with an ancient history, millions of speakers, and immense cultural value, that, nevertheless, remains severely underrepresented in terms of resources and global exposure. In this paper we develop, curate, and publicly release a set of corpora in several Mayan languages spoken in Guatemala and Southern Mexico, which we call MayanV. The datasets are parallel with Spanish, the dominant language of the region, and are taken from official native sources focused on representing informal, day-to-day, and non-domain-specific language. As such, and according to our dialectometric analysis, they differ in register from most other available resources. Additionally, we present neural machine translation models, trained on as many resources and Mayan languages as possible, and evaluated exclusively on our datasets. We observe lexical divergences between the dialects of Spanish in our resources and the more widespread written standard of Spanish, and that resources other than the ones we present do not seem to improve translation performance, indicating that many such resources may not accurately capture common, real-life language usage. The MayanV dataset is available at https://github.com/transducens/mayanv.
Understanding the effects of word-level linguistic annotations in under-resourced neural machine translation
Jan 29, 2024


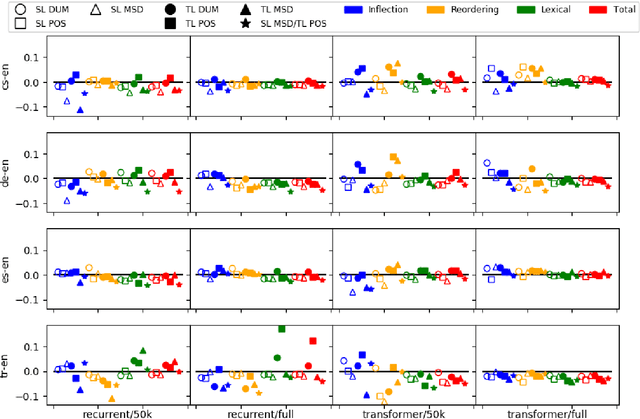
This paper studies the effects of word-level linguistic annotations in under-resourced neural machine translation, for which there is incomplete evidence in the literature. The study covers eight language pairs, different training corpus sizes, two architectures, and three types of annotation: dummy tags (with no linguistic information at all), part-of-speech tags, and morpho-syntactic description tags, which consist of part of speech and morphological features. These linguistic annotations are interleaved in the input or output streams as a single tag placed before each word. In order to measure the performance under each scenario, we use automatic evaluation metrics and perform automatic error classification. Our experiments show that, in general, source-language annotations are helpful and morpho-syntactic descriptions outperform part of speech for some language pairs. On the contrary, when words are annotated in the target language, part-of-speech tags systematically outperform morpho-syntactic description tags in terms of automatic evaluation metrics, even though the use of morpho-syntactic description tags improves the grammaticality of the output. We provide a detailed analysis of the reasons behind this result.
Non-Fluent Synthetic Target-Language Data Improve Neural Machine Translation
Jan 29, 2024When the amount of parallel sentences available to train a neural machine translation is scarce, a common practice is to generate new synthetic training samples from them. A number of approaches have been proposed to produce synthetic parallel sentences that are similar to those in the parallel data available. These approaches work under the assumption that non-fluent target-side synthetic training samples can be harmful and may deteriorate translation performance. Even so, in this paper we demonstrate that synthetic training samples with non-fluent target sentences can improve translation performance if they are used in a multilingual machine translation framework as if they were sentences in another language. We conducted experiments on ten low-resource and four high-resource translation tasks and found out that this simple approach consistently improves translation performance as compared to state-of-the-art methods for generating synthetic training samples similar to those found in corpora. Furthermore, this improvement is independent of the size of the original training corpus, the resulting systems are much more robust against domain shift and produce less hallucinations.
* arXiv admin note: text overlap with arXiv:2109.03645
Cross-lingual neural fuzzy matching for exploiting target-language monolingual corpora in computer-aided translation
Jan 16, 2024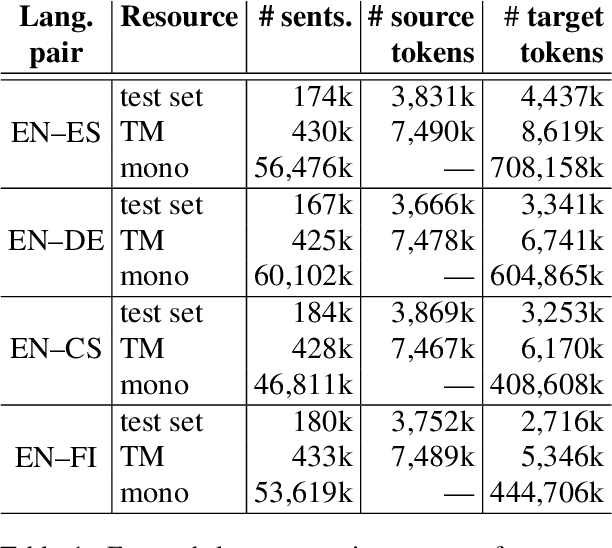

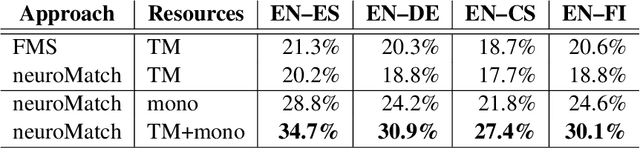
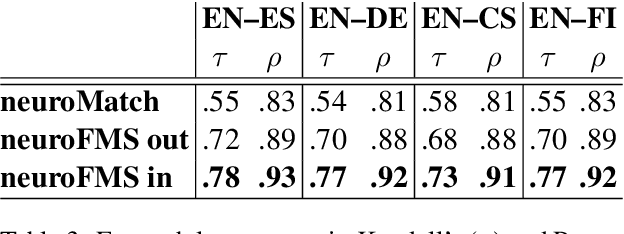
Computer-aided translation (CAT) tools based on translation memories (MT) play a prominent role in the translation workflow of professional translators. However, the reduced availability of in-domain TMs, as compared to in-domain monolingual corpora, limits its adoption for a number of translation tasks. In this paper, we introduce a novel neural approach aimed at overcoming this limitation by exploiting not only TMs, but also in-domain target-language (TL) monolingual corpora, and still enabling a similar functionality to that offered by conventional TM-based CAT tools. Our approach relies on cross-lingual sentence embeddings to retrieve translation proposals from TL monolingual corpora, and on a neural model to estimate their post-editing effort. The paper presents an automatic evaluation of these techniques on four language pairs that shows that our approach can successfully exploit monolingual texts in a TM-based CAT environment, increasing the amount of useful translation proposals, and that our neural model for estimating the post-editing effort enables the combination of translation proposals obtained from monolingual corpora and from TMs in the usual way. A human evaluation performed on a single language pair confirms the results of the automatic evaluation and seems to indicate that the translation proposals retrieved with our approach are more useful than what the automatic evaluation shows.
Rethinking Data Augmentation for Low-Resource Neural Machine Translation: A Multi-Task Learning Approach
Sep 08, 2021
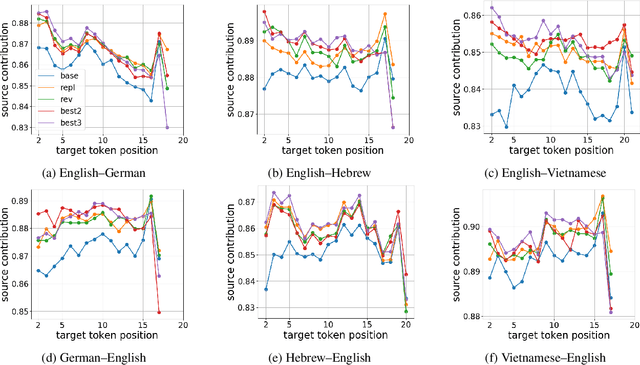
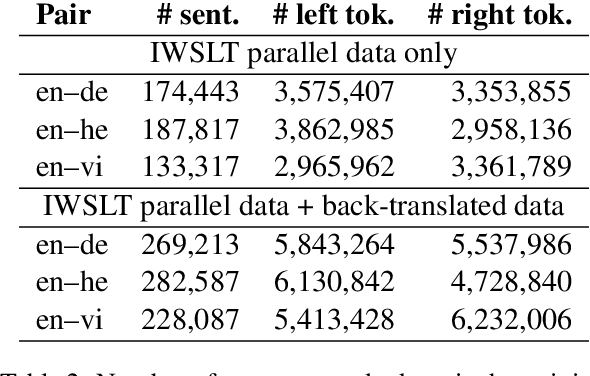
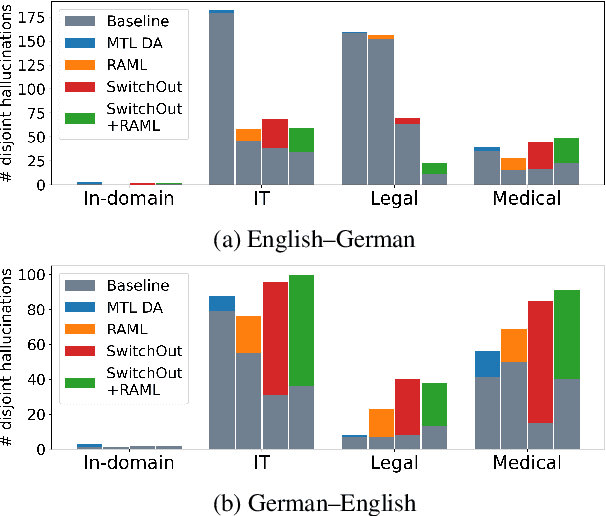
In the context of neural machine translation, data augmentation (DA) techniques may be used for generating additional training samples when the available parallel data are scarce. Many DA approaches aim at expanding the support of the empirical data distribution by generating new sentence pairs that contain infrequent words, thus making it closer to the true data distribution of parallel sentences. In this paper, we propose to follow a completely different approach and present a multi-task DA approach in which we generate new sentence pairs with transformations, such as reversing the order of the target sentence, which produce unfluent target sentences. During training, these augmented sentences are used as auxiliary tasks in a multi-task framework with the aim of providing new contexts where the target prefix is not informative enough to predict the next word. This strengthens the encoder and forces the decoder to pay more attention to the source representations of the encoder. Experiments carried out on six low-resource translation tasks show consistent improvements over the baseline and over DA methods aiming at extending the support of the empirical data distribution. The systems trained with our approach rely more on the source tokens, are more robust against domain shift and suffer less hallucinations.
Learning synchronous context-free grammars with multiple specialised non-terminals for hierarchical phrase-based translation
Apr 03, 2020
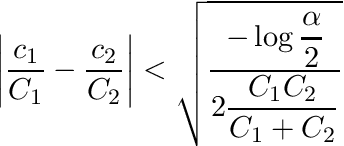


Translation models based on hierarchical phrase-based statistical machine translation (HSMT) have shown better performances than the non-hierarchical phrase-based counterparts for some language pairs. The standard approach to HSMT learns and apply a synchronous context-free grammar with a single non-terminal. The hypothesis behind the grammar refinement algorithm presented in this work is that this single non-terminal is overloaded, and insufficiently discriminative, and therefore, an adequate split of it into more specialised symbols could lead to improved models. This paper presents a method to learn synchronous context-free grammars with a huge number of initial non-terminals, which are then grouped via a clustering algorithm. Our experiments show that the resulting smaller set of non-terminals correctly capture the contextual information that makes it possible to statistically significantly improve the BLEU score of the standard HSMT approach.
UAlacant machine translation quality estimation at WMT 2018: a simple approach using phrase tables and feed-forward neural networks
Nov 06, 2018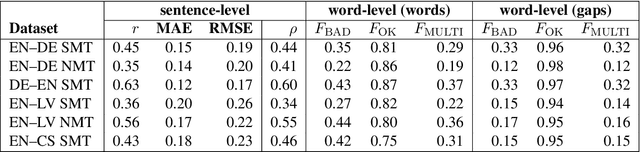
We describe the Universitat d'Alacant submissions to the word- and sentence-level machine translation (MT) quality estimation (QE) shared task at WMT 2018. Our approach to word-level MT QE builds on previous work to mark the words in the machine-translated sentence as \textit{OK} or \textit{BAD}, and is extended to determine if a word or sequence of words need to be inserted in the gap after each word. Our sentence-level submission simply uses the edit operations predicted by the word-level approach to approximate TER. The method presented ranked first in the sub-task of identifying insertions in gaps for three out of the six datasets, and second in the rest of them.
Generalized Biwords for Bitext Compression and Translation Spotting
Jan 18, 2014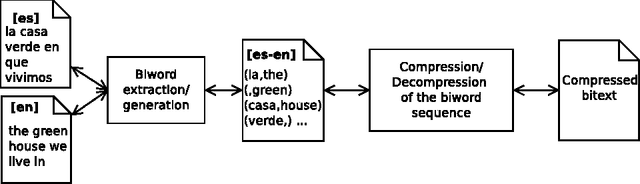
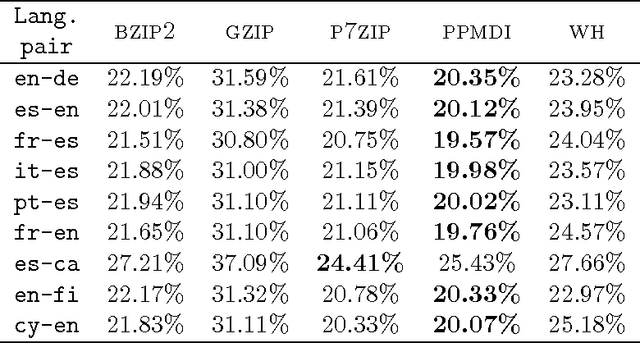

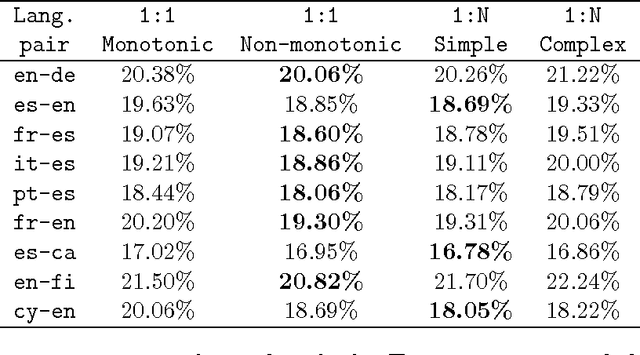
Large bilingual parallel texts (also known as bitexts) are usually stored in a compressed form, and previous work has shown that they can be more efficiently compressed if the fact that the two texts are mutual translations is exploited. For example, a bitext can be seen as a sequence of biwords ---pairs of parallel words with a high probability of co-occurrence--- that can be used as an intermediate representation in the compression process. However, the simple biword approach described in the literature can only exploit one-to-one word alignments and cannot tackle the reordering of words. We therefore introduce a generalization of biwords which can describe multi-word expressions and reorderings. We also describe some methods for the binary compression of generalized biword sequences, and compare their performance when different schemes are applied to the extraction of the biword sequence. In addition, we show that this generalization of biwords allows for the implementation of an efficient algorithm to look on the compressed bitext for words or text segments in one of the texts and retrieve their counterpart translations in the other text ---an application usually referred to as translation spotting--- with only some minor modifications in the compression algorithm.
Inferring Shallow-Transfer Machine Translation Rules from Small Parallel Corpora
Jan 15, 2014



This paper describes a method for the automatic inference of structural transfer rules to be used in a shallow-transfer machine translation (MT) system from small parallel corpora. The structural transfer rules are based on alignment templates, like those used in statistical MT. Alignment templates are extracted from sentence-aligned parallel corpora and extended with a set of restrictions which are derived from the bilingual dictionary of the MT system and control their application as transfer rules. The experiments conducted using three different language pairs in the free/open-source MT platform Apertium show that translation quality is improved as compared to word-for-word translation (when no transfer rules are used), and that the resulting translation quality is close to that obtained using hand-coded transfer rules. The method we present is entirely unsupervised and benefits from information in the rest of modules of the MT system in which the inferred rules are applied.