 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLearning synchronous context-free grammars with multiple specialised non-terminals for hierarchical phrase-based translation
Paper and Code
Apr 03, 2020
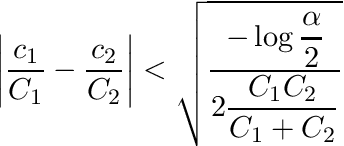


Translation models based on hierarchical phrase-based statistical machine translation (HSMT) have shown better performances than the non-hierarchical phrase-based counterparts for some language pairs. The standard approach to HSMT learns and apply a synchronous context-free grammar with a single non-terminal. The hypothesis behind the grammar refinement algorithm presented in this work is that this single non-terminal is overloaded, and insufficiently discriminative, and therefore, an adequate split of it into more specialised symbols could lead to improved models. This paper presents a method to learn synchronous context-free grammars with a huge number of initial non-terminals, which are then grouped via a clustering algorithm. Our experiments show that the resulting smaller set of non-terminals correctly capture the contextual information that makes it possible to statistically significantly improve the BLEU score of the standard HSMT approach.