 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeBeyond Holistic Scores: Automatic Trait-Based Quality Scoring of Argumentative Essays
Feb 04, 2026Automated Essay Scoring systems have traditionally focused on holistic scores, limiting their pedagogical usefulness, especially in the case of complex essay genres such as argumentative writing. In educational contexts, teachers and learners require interpretable, trait-level feedback that aligns with instructional goals and established rubrics. In this paper, we study trait-based Automatic Argumentative Essay Scoring using two complementary modeling paradigms designed for realistic educational deployment: (1) structured in-context learning with small open-source LLMs, and (2) a supervised, encoder-based BigBird model with a CORAL-style ordinal regression formulation, optimized for long-sequence understanding. We conduct a systematic evaluation on the ASAP++ dataset, which includes essay scores across five quality traits, offering strong coverage of core argumentation dimensions. LLMs are prompted with designed, rubric-aligned in-context examples, along with feedback and confidence requests, while we explicitly model ordinality in scores with the BigBird model via the rank-consistent CORAL framework. Our results show that explicitly modeling score ordinality substantially improves agreement with human raters across all traits, outperforming LLMs and nominal classification and regression-based baselines. This finding reinforces the importance of aligning model objectives with rubric semantics for educational assessment. At the same time, small open-source LLMs achieve a competitive performance without task-specific fine-tuning, particularly for reasoning-oriented traits, while enabling transparent, privacy-preserving, and locally deployable assessment scenarios. Our findings provide methodological, modeling, and practical insights for the design of AI-based educational systems that aim to deliver interpretable, rubric-aligned feedback for argumentative writing.
ELLIS Alicante at CQs-Gen 2025: Winning the critical thinking questions shared task: LLM-based question generation and selection
Jun 17, 2025The widespread adoption of chat interfaces based on Large Language Models (LLMs) raises concerns about promoting superficial learning and undermining the development of critical thinking skills. Instead of relying on LLMs purely for retrieving factual information, this work explores their potential to foster deeper reasoning by generating critical questions that challenge unsupported or vague claims in debate interventions. This study is part of a shared task of the 12th Workshop on Argument Mining, co-located with ACL 2025, focused on automatic critical question generation. We propose a two-step framework involving two small-scale open source language models: a Questioner that generates multiple candidate questions and a Judge that selects the most relevant ones. Our system ranked first in the shared task competition, demonstrating the potential of the proposed LLM-based approach to encourage critical engagement with argumentative texts.
Leveraging Small LLMs for Argument Mining in Education: Argument Component Identification, Classification, and Assessment
Feb 20, 2025



Argument mining algorithms analyze the argumentative structure of essays, making them a valuable tool for enhancing education by providing targeted feedback on the students' argumentation skills. While current methods often use encoder or encoder-decoder deep learning architectures, decoder-only models remain largely unexplored, offering a promising research direction. This paper proposes leveraging open-source, small Large Language Models (LLMs) for argument mining through few-shot prompting and fine-tuning. These models' small size and open-source nature ensure accessibility, privacy, and computational efficiency, enabling schools and educators to adopt and deploy them locally. Specifically, we perform three tasks: segmentation of student essays into arguments, classification of the arguments by type, and assessment of their quality. We empirically evaluate the models on the Feedback Prize - Predicting Effective Arguments dataset of grade 6-12 students essays and demonstrate how fine-tuned small LLMs outperform baseline methods in segmenting the essays and determining the argument types while few-shot prompting yields comparable performance to that of the baselines in assessing quality. This work highlights the educational potential of small, open-source LLMs to provide real-time, personalized feedback, enhancing independent learning and writing skills while ensuring low computational cost and privacy.
Curated Datasets and Neural Models for Machine Translation of Informal Registers between Mayan and Spanish Vernaculars
Apr 11, 2024
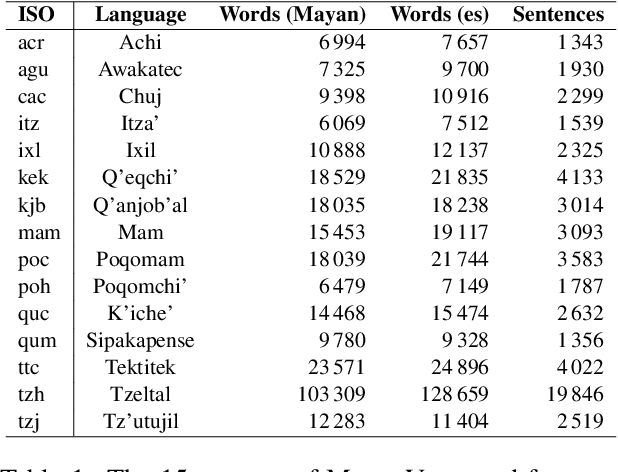
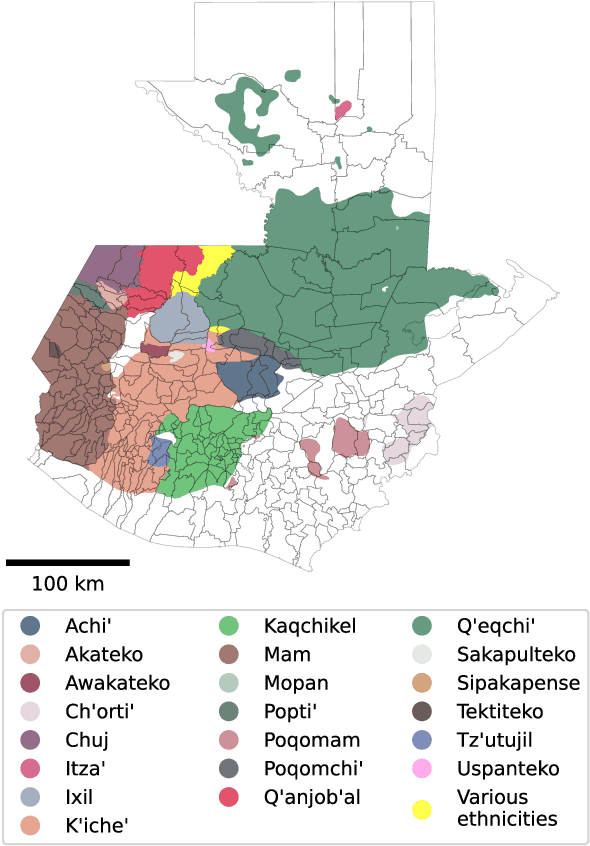

The Mayan languages comprise a language family with an ancient history, millions of speakers, and immense cultural value, that, nevertheless, remains severely underrepresented in terms of resources and global exposure. In this paper we develop, curate, and publicly release a set of corpora in several Mayan languages spoken in Guatemala and Southern Mexico, which we call MayanV. The datasets are parallel with Spanish, the dominant language of the region, and are taken from official native sources focused on representing informal, day-to-day, and non-domain-specific language. As such, and according to our dialectometric analysis, they differ in register from most other available resources. Additionally, we present neural machine translation models, trained on as many resources and Mayan languages as possible, and evaluated exclusively on our datasets. We observe lexical divergences between the dialects of Spanish in our resources and the more widespread written standard of Spanish, and that resources other than the ones we present do not seem to improve translation performance, indicating that many such resources may not accurately capture common, real-life language usage. The MayanV dataset is available at https://github.com/transducens/mayanv.
Non-Fluent Synthetic Target-Language Data Improve Neural Machine Translation
Jan 29, 2024When the amount of parallel sentences available to train a neural machine translation is scarce, a common practice is to generate new synthetic training samples from them. A number of approaches have been proposed to produce synthetic parallel sentences that are similar to those in the parallel data available. These approaches work under the assumption that non-fluent target-side synthetic training samples can be harmful and may deteriorate translation performance. Even so, in this paper we demonstrate that synthetic training samples with non-fluent target sentences can improve translation performance if they are used in a multilingual machine translation framework as if they were sentences in another language. We conducted experiments on ten low-resource and four high-resource translation tasks and found out that this simple approach consistently improves translation performance as compared to state-of-the-art methods for generating synthetic training samples similar to those found in corpora. Furthermore, this improvement is independent of the size of the original training corpus, the resulting systems are much more robust against domain shift and produce less hallucinations.
* arXiv admin note: text overlap with arXiv:2109.03645
Understanding the effects of word-level linguistic annotations in under-resourced neural machine translation
Jan 29, 2024


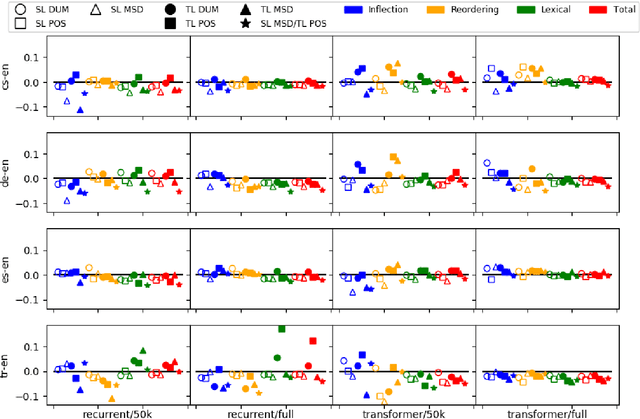
This paper studies the effects of word-level linguistic annotations in under-resourced neural machine translation, for which there is incomplete evidence in the literature. The study covers eight language pairs, different training corpus sizes, two architectures, and three types of annotation: dummy tags (with no linguistic information at all), part-of-speech tags, and morpho-syntactic description tags, which consist of part of speech and morphological features. These linguistic annotations are interleaved in the input or output streams as a single tag placed before each word. In order to measure the performance under each scenario, we use automatic evaluation metrics and perform automatic error classification. Our experiments show that, in general, source-language annotations are helpful and morpho-syntactic descriptions outperform part of speech for some language pairs. On the contrary, when words are annotated in the target language, part-of-speech tags systematically outperform morpho-syntactic description tags in terms of automatic evaluation metrics, even though the use of morpho-syntactic description tags improves the grammaticality of the output. We provide a detailed analysis of the reasons behind this result.
Cross-lingual neural fuzzy matching for exploiting target-language monolingual corpora in computer-aided translation
Jan 16, 2024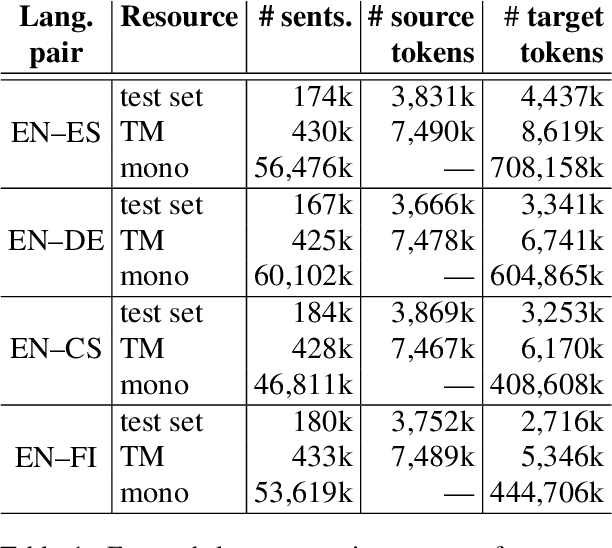

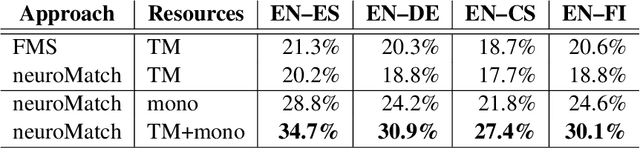
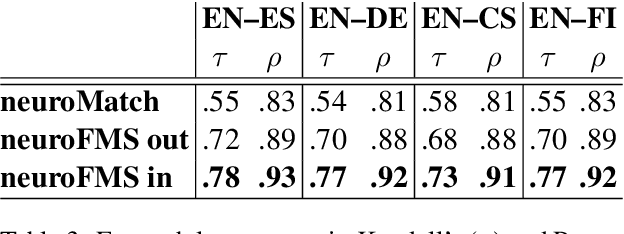
Computer-aided translation (CAT) tools based on translation memories (MT) play a prominent role in the translation workflow of professional translators. However, the reduced availability of in-domain TMs, as compared to in-domain monolingual corpora, limits its adoption for a number of translation tasks. In this paper, we introduce a novel neural approach aimed at overcoming this limitation by exploiting not only TMs, but also in-domain target-language (TL) monolingual corpora, and still enabling a similar functionality to that offered by conventional TM-based CAT tools. Our approach relies on cross-lingual sentence embeddings to retrieve translation proposals from TL monolingual corpora, and on a neural model to estimate their post-editing effort. The paper presents an automatic evaluation of these techniques on four language pairs that shows that our approach can successfully exploit monolingual texts in a TM-based CAT environment, increasing the amount of useful translation proposals, and that our neural model for estimating the post-editing effort enables the combination of translation proposals obtained from monolingual corpora and from TMs in the usual way. A human evaluation performed on a single language pair confirms the results of the automatic evaluation and seems to indicate that the translation proposals retrieved with our approach are more useful than what the automatic evaluation shows.
Rethinking Data Augmentation for Low-Resource Neural Machine Translation: A Multi-Task Learning Approach
Sep 08, 2021
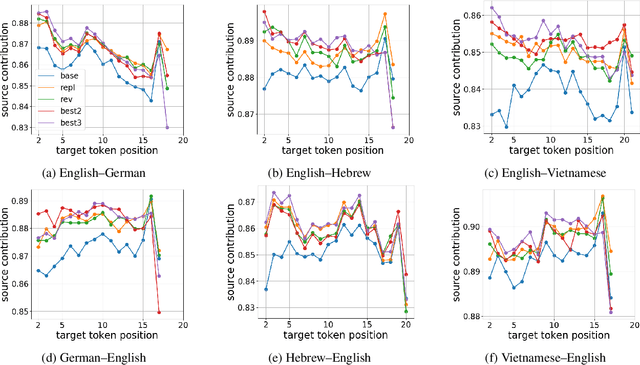
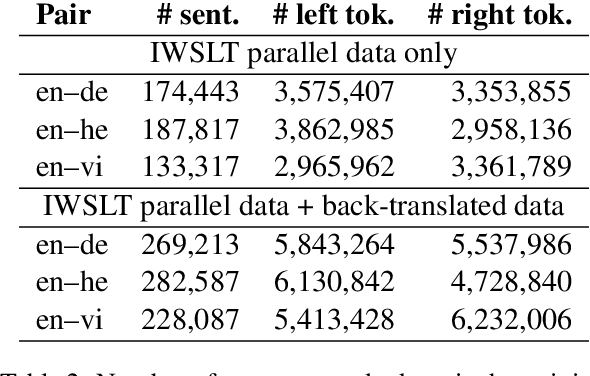
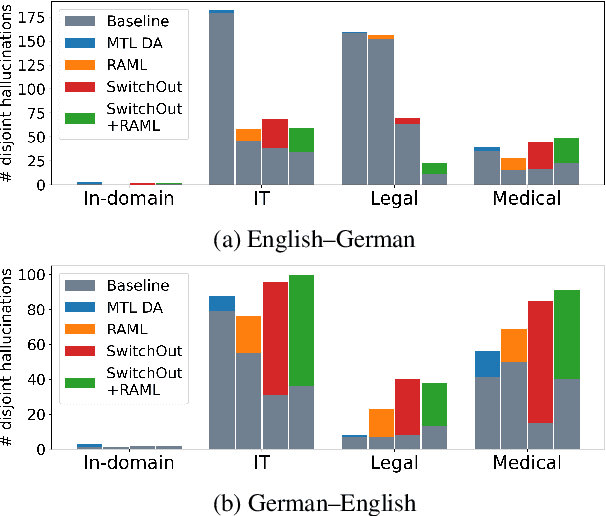
In the context of neural machine translation, data augmentation (DA) techniques may be used for generating additional training samples when the available parallel data are scarce. Many DA approaches aim at expanding the support of the empirical data distribution by generating new sentence pairs that contain infrequent words, thus making it closer to the true data distribution of parallel sentences. In this paper, we propose to follow a completely different approach and present a multi-task DA approach in which we generate new sentence pairs with transformations, such as reversing the order of the target sentence, which produce unfluent target sentences. During training, these augmented sentences are used as auxiliary tasks in a multi-task framework with the aim of providing new contexts where the target prefix is not informative enough to predict the next word. This strengthens the encoder and forces the decoder to pay more attention to the source representations of the encoder. Experiments carried out on six low-resource translation tasks show consistent improvements over the baseline and over DA methods aiming at extending the support of the empirical data distribution. The systems trained with our approach rely more on the source tokens, are more robust against domain shift and suffer less hallucinations.
Learning synchronous context-free grammars with multiple specialised non-terminals for hierarchical phrase-based translation
Apr 03, 2020
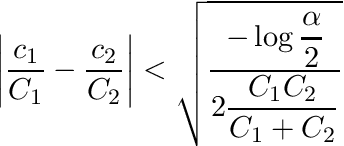


Translation models based on hierarchical phrase-based statistical machine translation (HSMT) have shown better performances than the non-hierarchical phrase-based counterparts for some language pairs. The standard approach to HSMT learns and apply a synchronous context-free grammar with a single non-terminal. The hypothesis behind the grammar refinement algorithm presented in this work is that this single non-terminal is overloaded, and insufficiently discriminative, and therefore, an adequate split of it into more specialised symbols could lead to improved models. This paper presents a method to learn synchronous context-free grammars with a huge number of initial non-terminals, which are then grouped via a clustering algorithm. Our experiments show that the resulting smaller set of non-terminals correctly capture the contextual information that makes it possible to statistically significantly improve the BLEU score of the standard HSMT approach.