 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCross-lingual neural fuzzy matching for exploiting target-language monolingual corpora in computer-aided translation
Paper and Code
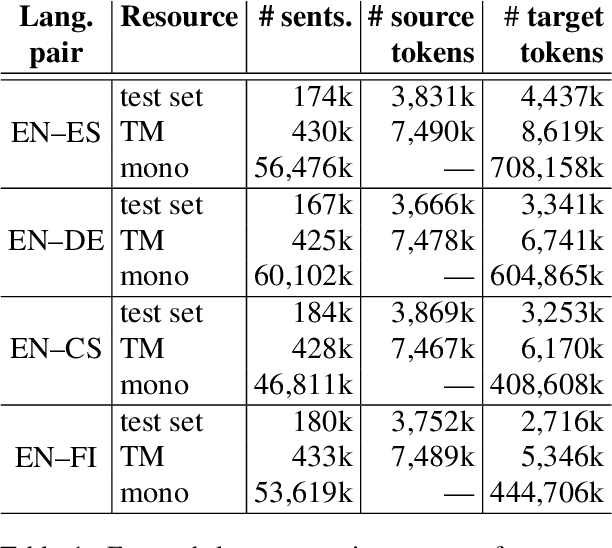

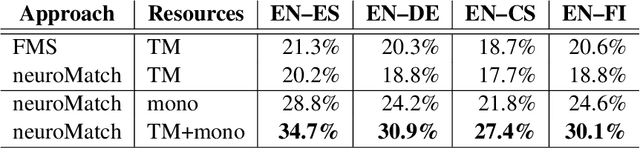
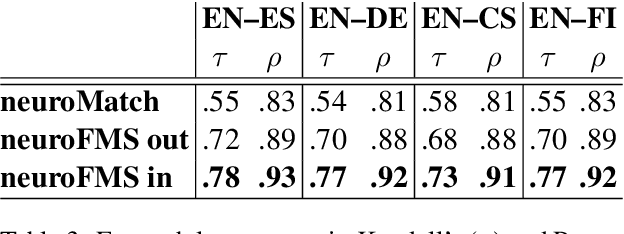
Computer-aided translation (CAT) tools based on translation memories (MT) play a prominent role in the translation workflow of professional translators. However, the reduced availability of in-domain TMs, as compared to in-domain monolingual corpora, limits its adoption for a number of translation tasks. In this paper, we introduce a novel neural approach aimed at overcoming this limitation by exploiting not only TMs, but also in-domain target-language (TL) monolingual corpora, and still enabling a similar functionality to that offered by conventional TM-based CAT tools. Our approach relies on cross-lingual sentence embeddings to retrieve translation proposals from TL monolingual corpora, and on a neural model to estimate their post-editing effort. The paper presents an automatic evaluation of these techniques on four language pairs that shows that our approach can successfully exploit monolingual texts in a TM-based CAT environment, increasing the amount of useful translation proposals, and that our neural model for estimating the post-editing effort enables the combination of translation proposals obtained from monolingual corpora and from TMs in the usual way. A human evaluation performed on a single language pair confirms the results of the automatic evaluation and seems to indicate that the translation proposals retrieved with our approach are more useful than what the automatic evaluation shows.