 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeGeneralized Biwords for Bitext Compression and Translation Spotting
Jan 18, 2014
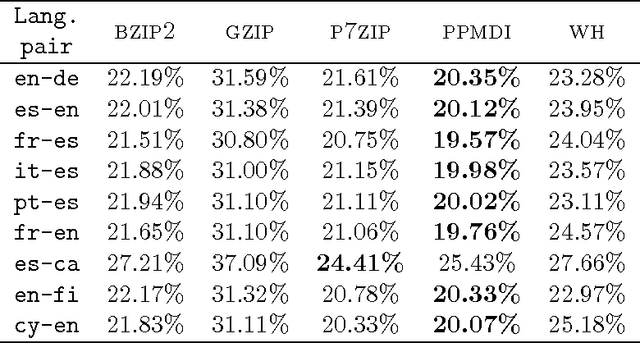

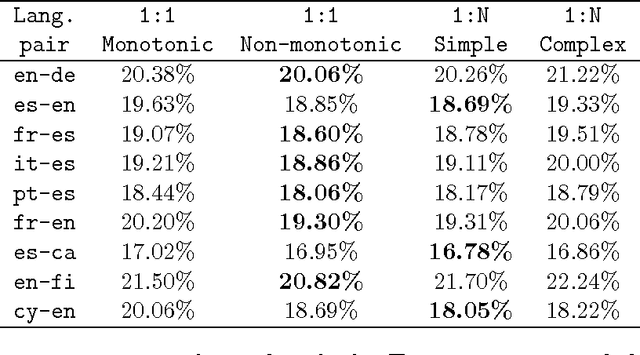
Large bilingual parallel texts (also known as bitexts) are usually stored in a compressed form, and previous work has shown that they can be more efficiently compressed if the fact that the two texts are mutual translations is exploited. For example, a bitext can be seen as a sequence of biwords ---pairs of parallel words with a high probability of co-occurrence--- that can be used as an intermediate representation in the compression process. However, the simple biword approach described in the literature can only exploit one-to-one word alignments and cannot tackle the reordering of words. We therefore introduce a generalization of biwords which can describe multi-word expressions and reorderings. We also describe some methods for the binary compression of generalized biword sequences, and compare their performance when different schemes are applied to the extraction of the biword sequence. In addition, we show that this generalization of biwords allows for the implementation of an efficient algorithm to look on the compressed bitext for words or text segments in one of the texts and retrieve their counterpart translations in the other text ---an application usually referred to as translation spotting--- with only some minor modifications in the compression algorithm.