Get our free extension to see links to code for papers anywhere online!Free add-on: code for papers everywhere!Free add-on: See code for papers anywhere!
 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeUAlacant machine translation quality estimation at WMT 2018: a simple approach using phrase tables and feed-forward neural networks
Paper and Code
Nov 06, 2018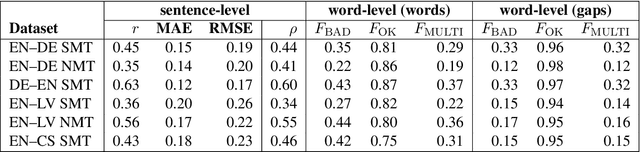
We describe the Universitat d'Alacant submissions to the word- and sentence-level machine translation (MT) quality estimation (QE) shared task at WMT 2018. Our approach to word-level MT QE builds on previous work to mark the words in the machine-translated sentence as \textit{OK} or \textit{BAD}, and is extended to determine if a word or sequence of words need to be inserted in the gap after each word. Our sentence-level submission simply uses the edit operations predicted by the word-level approach to approximate TER. The method presented ranked first in the sub-task of identifying insertions in gaps for three out of the six datasets, and second in the rest of them.
* 10 pages, 1 table, Proceedings of the 3rd Conference on Machine
Translation (WMT18), Brussels 31.10.2018--01.11.2018, pp. 814--821
View paper on