Get our free extension to see links to code for papers anywhere online!Free add-on: code for papers everywhere!Free add-on: See code for papers anywhere!
 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeExamining a hate speech corpus for hate speech detection and popularity prediction
Paper and Code
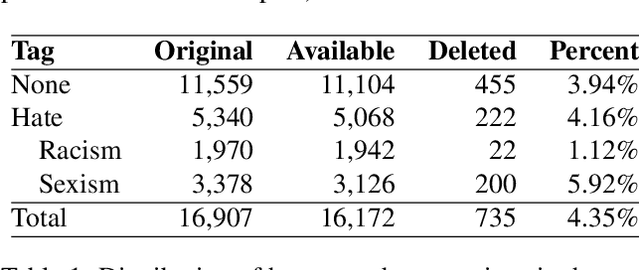
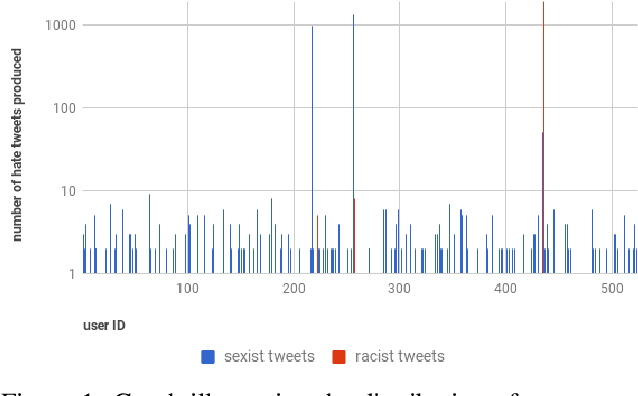
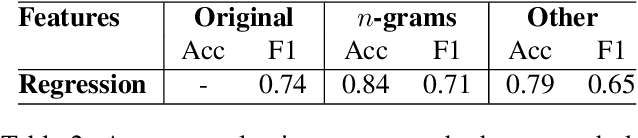
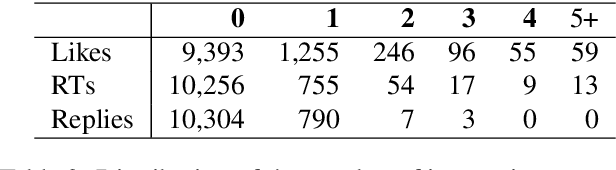
As research on hate speech becomes more and more relevant every day, most of it is still focused on hate speech detection. By attempting to replicate a hate speech detection experiment performed on an existing Twitter corpus annotated for hate speech, we highlight some issues that arise from doing research in the field of hate speech, which is essentially still in its infancy. We take a critical look at the training corpus in order to understand its biases, while also using it to venture beyond hate speech detection and investigate whether it can be used to shed light on other facets of research, such as popularity of hate tweets.
* In Proceedings of 4REAL Workshop 9-16 (2018) * 8 pages, 1 figure, 10 tables, published in proceedings of 4REAL2018:
Workshop on Replicability and Reproducibility of Research Results in Science
and Technology of Language
View paper on