 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeIs it worth it? Budget-related evaluation metrics for model selection
Paper and Code

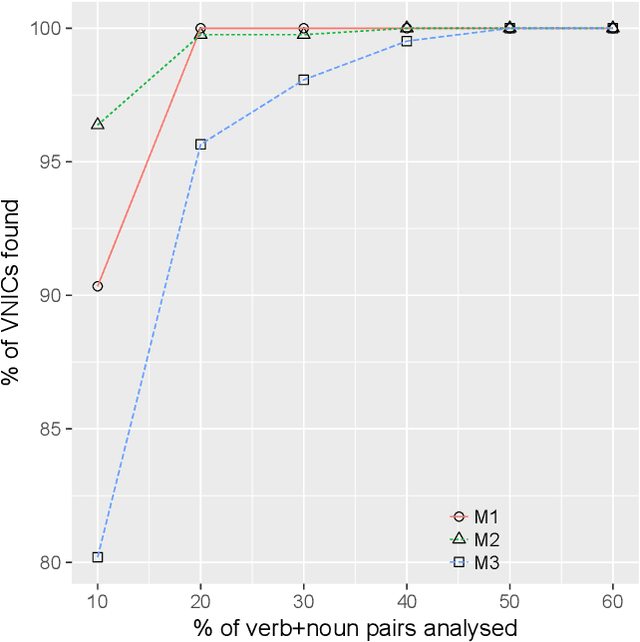
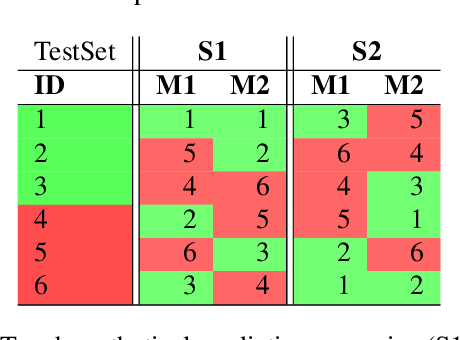

Creating a linguistic resource is often done by using a machine learning model that filters the content that goes through to a human annotator, before going into the final resource. However, budgets are often limited, and the amount of available data exceeds the amount of affordable annotation. In order to optimize the benefit from the invested human work, we argue that deciding on which model one should employ depends not only on generalized evaluation metrics such as F-score, but also on the gain metric. Because the model with the highest F-score may not necessarily have the best sequencing of predicted classes, this may lead to wasting funds on annotating false positives, yielding zero improvement of the linguistic resource. We exemplify our point with a case study, using real data from a task of building a verb-noun idiom dictionary. We show that, given the choice of three systems with varying F-scores, the system with the highest F-score does not yield the highest profits. In other words, in our case the cost-benefit trade off is more favorable for a system with a lower F-score.