 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTrusting Language Models in Education
Aug 07, 2023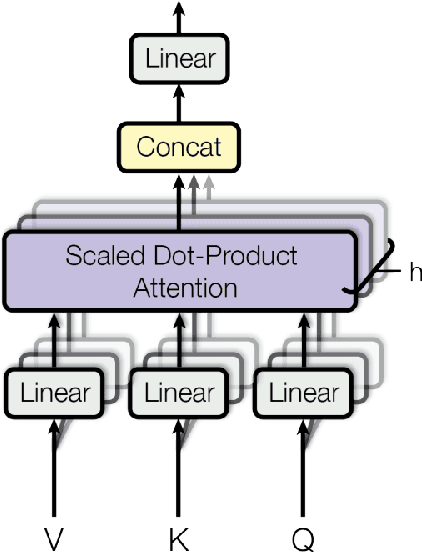
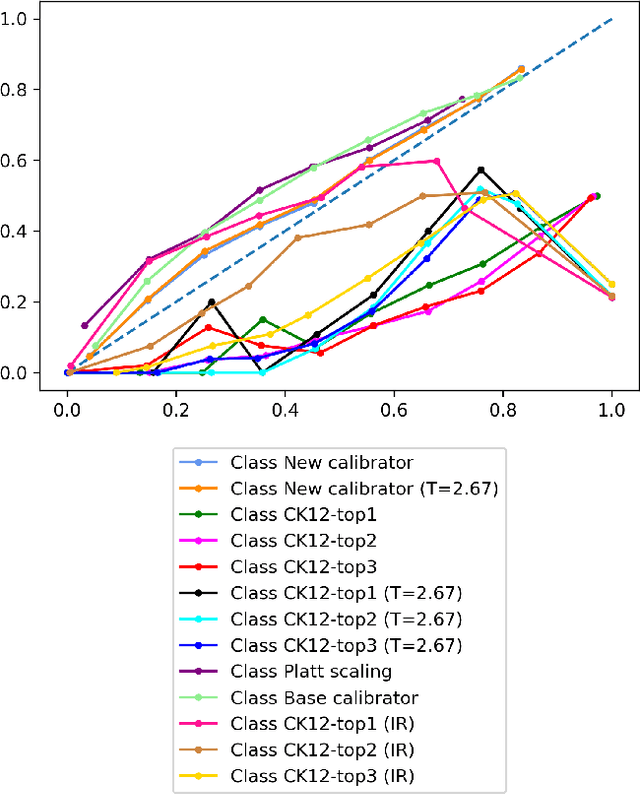
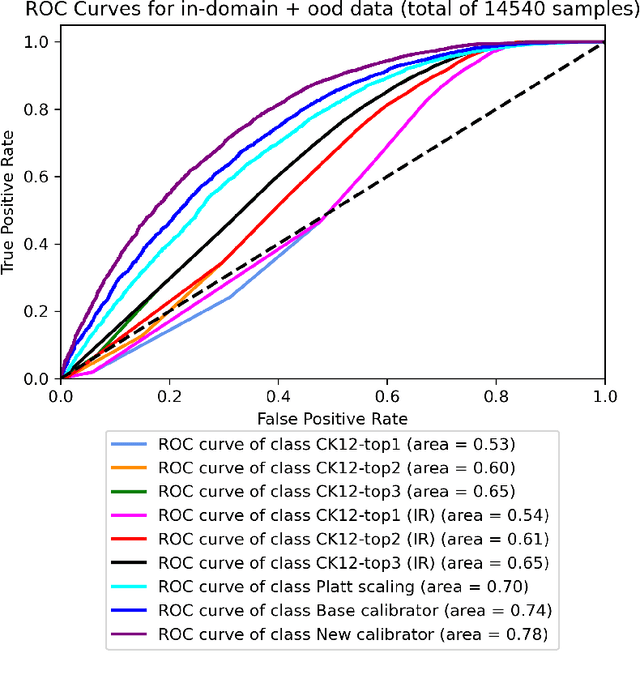
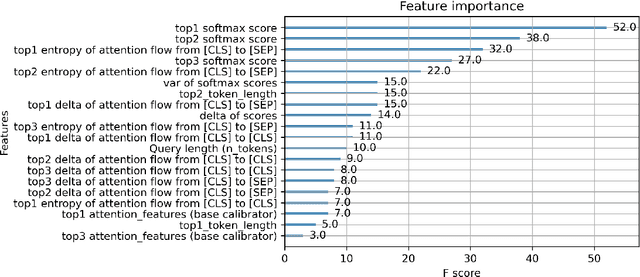
Language Models are being widely used in Education. Even though modern deep learning models achieve very good performance on question-answering tasks, sometimes they make errors. To avoid misleading students by showing wrong answers, it is important to calibrate the confidence - that is, the prediction probability - of these models. In our work, we propose to use an XGBoost on top of BERT to output the corrected probabilities, using features based on the attention mechanism. Our hypothesis is that the level of uncertainty contained in the flow of attention is related to the quality of the model's response itself.
Structural Isomprphism in Mathematical Expressions: A Simple Coding Scheme
May 29, 2018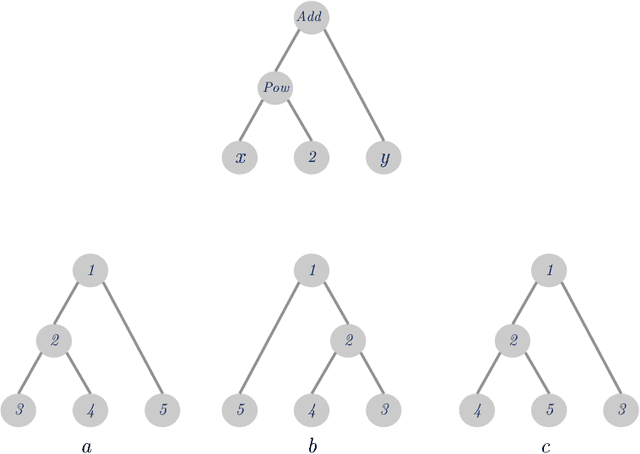

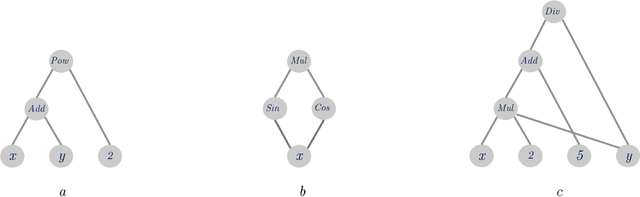
While there exist many methods in machine learning for comparison of letter string data, most are better equipped to handle strings that represent natural language, and their performance will not hold up when presented with strings that correspond to mathematical expressions. Based on the graphical representation of the expression tree, here I propose a simple method for encoding such expressions that is only sensitive to their structural properties, and invariant to the specifics which can vary between two seemingly different, but semantically similar mathematical expressions.