 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeWhen More is Less: Incorporating Additional Datasets Can Hurt Performance By Introducing Spurious Correlations
Aug 08, 2023



In machine learning, incorporating more data is often seen as a reliable strategy for improving model performance; this work challenges that notion by demonstrating that the addition of external datasets in many cases can hurt the resulting model's performance. In a large-scale empirical study across combinations of four different open-source chest x-ray datasets and 9 different labels, we demonstrate that in 43% of settings, a model trained on data from two hospitals has poorer worst group accuracy over both hospitals than a model trained on just a single hospital's data. This surprising result occurs even though the added hospital makes the training distribution more similar to the test distribution. We explain that this phenomenon arises from the spurious correlation that emerges between the disease and hospital, due to hospital-specific image artifacts. We highlight the trade-off one encounters when training on multiple datasets, between the obvious benefit of additional data and insidious cost of the introduced spurious correlation. In some cases, balancing the dataset can remove the spurious correlation and improve performance, but it is not always an effective strategy. We contextualize our results within the literature on spurious correlations to help explain these outcomes. Our experiments underscore the importance of exercising caution when selecting training data for machine learning models, especially in settings where there is a risk of spurious correlations such as with medical imaging. The risks outlined highlight the need for careful data selection and model evaluation in future research and practice.
MEDCOD: A Medically-Accurate, Emotive, Diverse, and Controllable Dialog System
Nov 17, 2021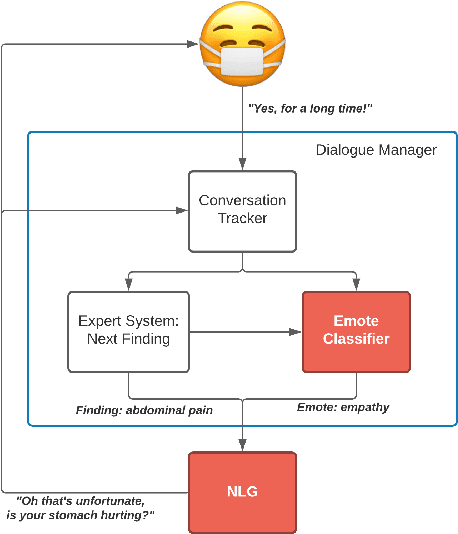



We present MEDCOD, a Medically-Accurate, Emotive, Diverse, and Controllable Dialog system with a unique approach to the natural language generator module. MEDCOD has been developed and evaluated specifically for the history taking task. It integrates the advantage of a traditional modular approach to incorporate (medical) domain knowledge with modern deep learning techniques to generate flexible, human-like natural language expressions. Two key aspects of MEDCOD's natural language output are described in detail. First, the generated sentences are emotive and empathetic, similar to how a doctor would communicate to the patient. Second, the generated sentence structures and phrasings are varied and diverse while maintaining medical consistency with the desired medical concept (provided by the dialogue manager module of MEDCOD). Experimental results demonstrate the effectiveness of our approach in creating a human-like medical dialogue system. Relevant code is available at https://github.com/curai/curai-research/tree/main/MEDCOD
Embedding Java Classes with code2vec: Improvements from Variable Obfuscation
Apr 06, 2020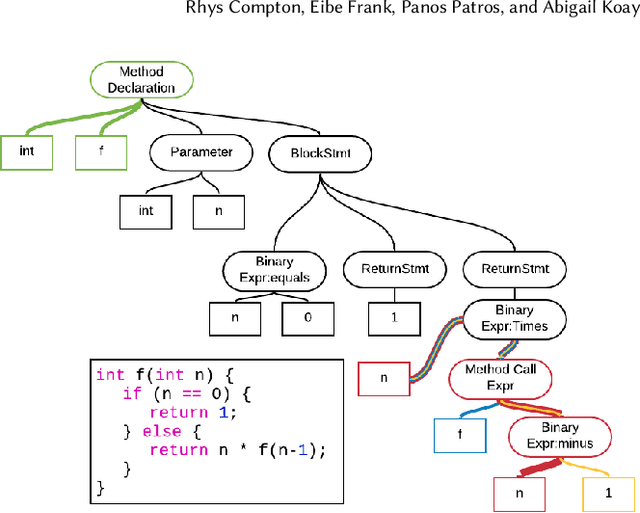

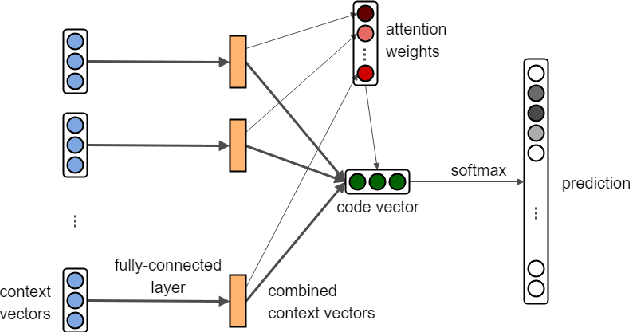
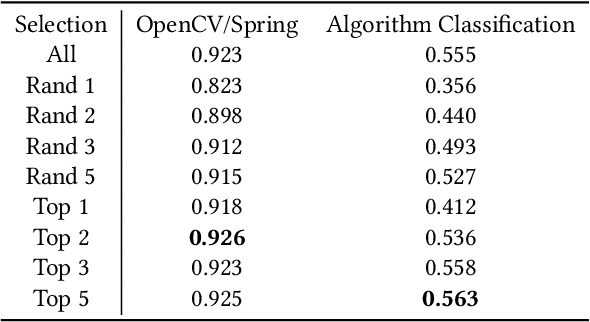
Automatic source code analysis in key areas of software engineering, such as code security, can benefit from Machine Learning (ML). However, many standard ML approaches require a numeric representation of data and cannot be applied directly to source code. Thus, to enable ML, we need to embed source code into numeric feature vectors while maintaining the semantics of the code as much as possible. code2vec is a recently released embedding approach that uses the proxy task of method name prediction to map Java methods to feature vectors. However, experimentation with code2vec shows that it learns to rely on variable names for prediction, causing it to be easily fooled by typos or adversarial attacks. Moreover, it is only able to embed individual Java methods and cannot embed an entire collection of methods such as those present in a typical Java class, making it difficult to perform predictions at the class level (e.g., for the identification of malicious Java classes). Both shortcomings are addressed in the research presented in this paper. We investigate the effect of obfuscating variable names during the training of a code2vec model to force it to rely on the structure of the code rather than specific names and consider a simple approach to creating class-level embeddings by aggregating sets of method embeddings. Our results, obtained on a challenging new collection of source-code classification problems, indicate that obfuscating variable names produces an embedding model that is both impervious to variable naming and more accurately reflects code semantics. The datasets, models, and code are shared for further ML research on source code.