 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeGeometric Coastline Localization using Vision-Language Models
Jun 09, 2026Coastline detection in remote sensing imagery is commonly formulated as a pixel-wise segmentation problem, where the final coastline is extracted from a predicted mask through post-processing. This formulation relegates coastline geometry, the primary representation used in coastal change analysis, to a secondary artifact rather than the learning objective. In practice, coastlines are defined by geomorphic proxies such as vegetation lines, dune toes, or cliff edges, rather than an instantaneous land-water boundary often used in pixel-based segmentation approaches. In this work, we revisit coastline extraction from a representation perspective and formulate the task as geometric boundary localization. We use the New Zealand Coastal Change Dataset (NZCCD) and high-resolution aerial imagery from Land Information New Zealand (LINZ) to develop CoastlineVLM-7B, a vision-language model (VLM) built on the GeoChat-7B/LLaVA-1.5 architecture that jointly performs coastline presence detection, proxy-type classification, and coastline grounding. The model directly predicts a coastline as a polyline rather than a dense segmentation mask. We evaluate CoastlineVLM-7B against segmentation baselines under strict one-pixel boundary supervision. Results show that geometry-based metrics are more suitable for assessing coastline localization quality than pixel-overlap metrics such as Intersection over Union (IoU). CoastlineVLM-7B improves global geometric alignment with reference coastlines, reducing Hausdorff distance from 37.74 m to 31.84 m and Earth Mover's Distance from 21.12 m to 17.32 m. These results indicate that output representation is a critical design choice in coastline extraction, and that geometry-oriented learning, combined with the semantic reasoning capabilities of vision-language models, aligns well with how coastlines are defined and evaluated in operational coastal monitoring.
Policy Gradient with Adaptive Entropy Annealing for Continual Fine-Tuning
Feb 15, 2026Despite their success, large pretrained vision models remain vulnerable to catastrophic forgetting when adapted to new tasks in class-incremental settings. Parameter-efficient fine-tuning (PEFT) alleviates this by restricting trainable parameters, yet most approaches still rely on cross-entropy (CE) loss, a surrogate for the 0-1 loss, to learn from new data. We revisit this choice and revive the true objective (0-1 loss) through a reinforcement learning perspective. By formulating classification as a one-step Markov Decision Process, we derive an Expected Policy Gradient (EPG) method that directly minimizes misclassification error with a low-variance gradient estimation. Our analysis shows that CE can be interpreted as EPG with an additional sample-weighting mechanism: CE encourages exploration by emphasizing low-confidence samples, while EPG prioritizes high-confidence ones. Building on this insight, we propose adaptive entropy annealing (aEPG), a training strategy that transitions from exploratory (CE-like) to exploitative (EPG-like) learning. aEPG-based methods outperform CE-based methods across diverse benchmarks and with various PEFT modules. More broadly, we evaluate various entropy regularization methods and demonstrate that lower entropy of the output prediction distribution enhances adaptation in pretrained vision models.
Using Multi-Instance Learning to Identify Unique Polyps in Colon Capsule Endoscopy Images
Jan 21, 2026Identifying unique polyps in colon capsule endoscopy (CCE) images is a critical yet challenging task for medical personnel due to the large volume of images, the cognitive load it creates for clinicians, and the ambiguity in labeling specific frames. This paper formulates this problem as a multi-instance learning (MIL) task, where a query polyp image is compared with a target bag of images to determine uniqueness. We employ a multi-instance verification (MIV) framework that incorporates attention mechanisms, such as variance-excited multi-head attention (VEMA) and distance-based attention (DBA), to enhance the model's ability to extract meaningful representations. Additionally, we investigate the impact of self-supervised learning using SimCLR to generate robust embeddings. Experimental results on a dataset of 1912 polyps from 754 patients demonstrate that attention mechanisms significantly improve performance, with DBA L1 achieving the highest test accuracy of 86.26\% and a test AUC of 0.928 using a ConvNeXt backbone with SimCLR pretraining. This study underscores the potential of MIL and self-supervised learning in advancing automated analysis of Colon Capsule Endoscopy images, with implications for broader medical imaging applications.
Experiments with Optimal Model Trees
Mar 17, 2025Model trees provide an appealing way to perform interpretable machine learning for both classification and regression problems. In contrast to ``classic'' decision trees with constant values in their leaves, model trees can use linear combinations of predictor variables in their leaf nodes to form predictions, which can help achieve higher accuracy and smaller trees. Typical algorithms for learning model trees from training data work in a greedy fashion, growing the tree in a top-down manner by recursively splitting the data into smaller and smaller subsets. Crucially, the selected splits are only locally optimal, potentially rendering the tree overly complex and less accurate than a tree whose structure is globally optimal for the training data. In this paper, we empirically investigate the effect of constructing globally optimal model trees for classification and regression with linear support vector machines at the leaf nodes. To this end, we present mixed-integer linear programming formulations to learn optimal trees, compute such trees for a large collection of benchmark data sets, and compare their performance against greedily grown model trees in terms of interpretability and accuracy. We also compare to classic optimal and greedily grown decision trees, random forests, and support vector machines. Our results show that optimal model trees can achieve competitive accuracy with very small trees. We also investigate the effect on the accuracy of replacing axis-parallel splits with multivariate ones, foregoing interpretability while potentially obtaining greater accuracy.
Utilising Deep Learning to Elicit Expert Uncertainty
Jan 21, 2025Recent work [ 14 ] has introduced a method for prior elicitation that utilizes records of expert decisions to infer a prior distribution. While this method provides a promising approach to eliciting expert uncertainty, it has only been demonstrated using tabular data, which may not entirely represent the information used by experts to make decisions. In this paper, we demonstrate how analysts can adopt a deep learning approach to utilize the method proposed in [14 ] with the actual information experts use. We provide an overview of deep learning models that can effectively model expert decision-making to elicit distributions that capture expert uncertainty and present an example examining the risk of colon cancer to show in detail how these models can be used.
Multiple Instance Verification
Jul 09, 2024We explore multiple-instance verification, a problem setting where a query instance is verified against a bag of target instances with heterogeneous, unknown relevancy. We show that naive adaptations of attention-based multiple instance learning (MIL) methods and standard verification methods like Siamese neural networks are unsuitable for this setting: directly combining state-of-the-art (SOTA) MIL methods and Siamese networks is shown to be no better, and sometimes significantly worse, than a simple baseline model. Postulating that this may be caused by the failure of the representation of the target bag to incorporate the query instance, we introduce a new pooling approach named ``cross-attention pooling'' (CAP). Under the CAP framework, we propose two novel attention functions to address the challenge of distinguishing between highly similar instances in a target bag. Through empirical studies on three different verification tasks, we demonstrate that CAP outperforms adaptations of SOTA MIL methods and the baseline by substantial margins, in terms of both classification accuracy and quality of the explanations provided for the classifications. Ablation studies confirm the superior ability of the new attention functions to identify key instances.
A simple but strong baseline for online continual learning: Repeated Augmented Rehearsal
Sep 28, 2022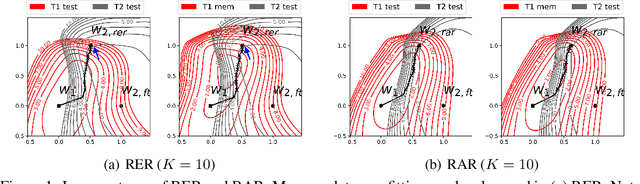
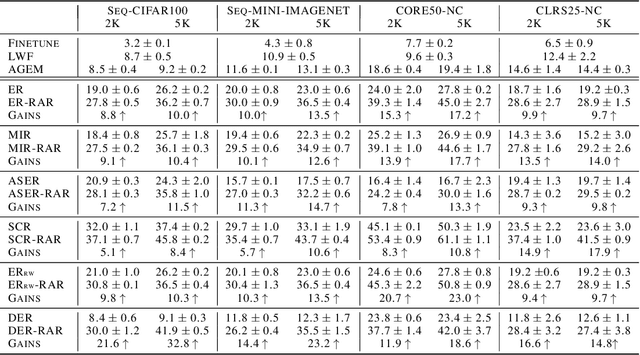
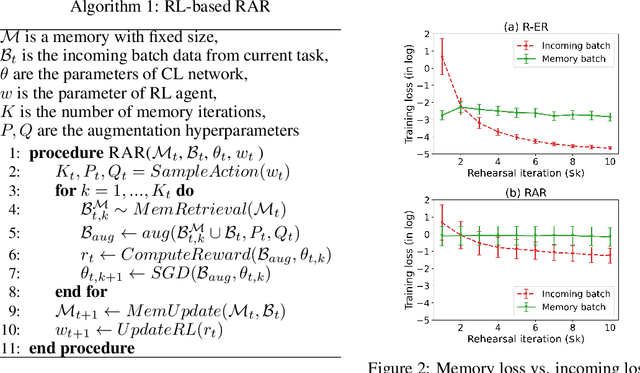
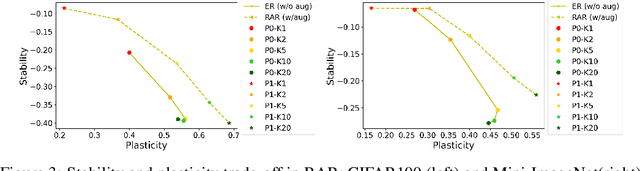
Online continual learning (OCL) aims to train neural networks incrementally from a non-stationary data stream with a single pass through data. Rehearsal-based methods attempt to approximate the observed input distributions over time with a small memory and revisit them later to avoid forgetting. Despite its strong empirical performance, rehearsal methods still suffer from a poor approximation of the loss landscape of past data with memory samples. This paper revisits the rehearsal dynamics in online settings. We provide theoretical insights on the inherent memory overfitting risk from the viewpoint of biased and dynamic empirical risk minimization, and examine the merits and limits of repeated rehearsal. Inspired by our analysis, a simple and intuitive baseline, Repeated Augmented Rehearsal (RAR), is designed to address the underfitting-overfitting dilemma of online rehearsal. Surprisingly, across four rather different OCL benchmarks, this simple baseline outperforms vanilla rehearsal by 9%-17% and also significantly improves state-of-the-art rehearsal-based methods MIR, ASER, and SCR. We also demonstrate that RAR successfully achieves an accurate approximation of the loss landscape of past data and high-loss ridge aversion in its learning trajectory. Extensive ablation studies are conducted to study the interplay between repeated and augmented rehearsal and reinforcement learning (RL) is applied to dynamically adjust the hyperparameters of RAR to balance the stability-plasticity trade-off online.
Cross-domain Few-shot Meta-learning Using Stacking
May 12, 2022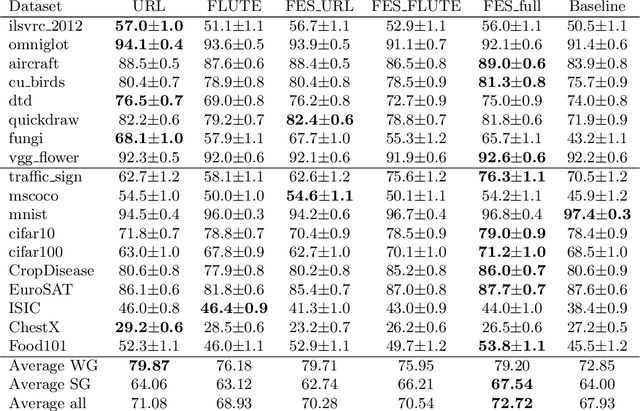
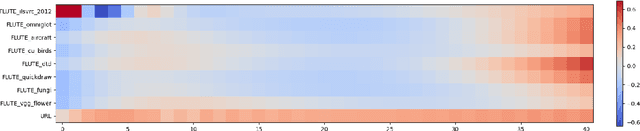
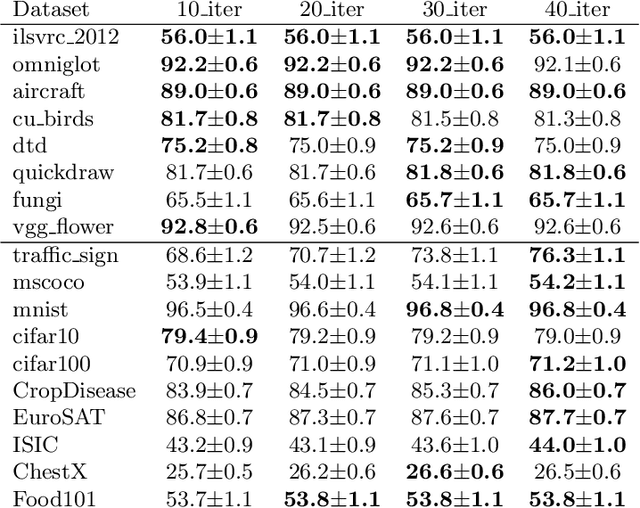
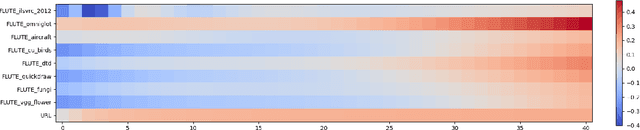
Cross-domain few-shot meta-learning (CDFSML) addresses learning problems where knowledge needs to be transferred from several source domains into an instance-scarce target domain with an explicitly different input distribution. Recently published CDFSML methods generally construct a "universal model" that combines knowledge of multiple source domains into one backbone feature extractor. This enables efficient inference but necessitates re-computation of the backbone whenever a new source domain is added. Moreover, state-of-the-art methods derive their universal model from a collection of backbones -- normally one for each source domain -- and the backbones may be constrained to have the same architecture as the universal model. We propose a CDFSML method that is inspired by the classic stacking approach to meta learning. It imposes no constraints on the backbones' architecture or feature shape and does not incur the computational overhead of (re-)computing a universal model. Given a target-domain task, it fine-tunes each backbone independently, uses cross-validation to extract meta training data from the task's instance-scarce support set, and learns a simple linear meta classifier from this data. We evaluate our stacking approach on the well-known Meta-Dataset benchmark, targeting image classification with convolutional neural networks, and show that it often yields substantially higher accuracy than competing methods.
Hitting the Target: Stopping Active Learning at the Cost-Based Optimum
Oct 07, 2021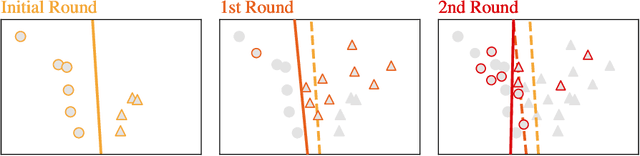

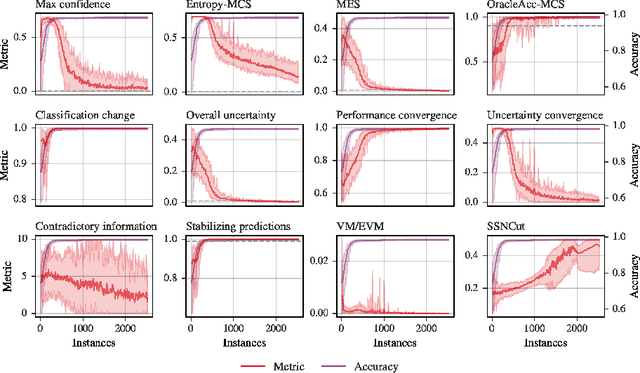
Active learning allows machine learning models to be trained using fewer labels while retaining similar performance to traditional fully supervised learning. An active learner selects the most informative data points, requests their labels, and retrains itself. While this approach is promising, it leaves an open problem of how to determine when the model is `good enough' without the additional labels required for traditional evaluation. In the past, different stopping criteria have been proposed aiming to identify the optimal stopping point. However, optimality can only be expressed as a domain-dependent trade-off between accuracy and the number of labels, and no criterion is superior in all applications. This paper is the first to give actionable advice to practitioners on what stopping criteria they should use in a given real-world scenario. We contribute the first large-scale comparison of stopping criteria, using a cost measure to quantify the accuracy/label trade-off, public implementations of all stopping criteria we evaluate, and an open-source framework for evaluating stopping criteria. Our research enables practitioners to substantially reduce labelling costs by utilizing the stopping criterion which best suits their domain.
Better Self-training for Image Classification through Self-supervision
Sep 09, 2021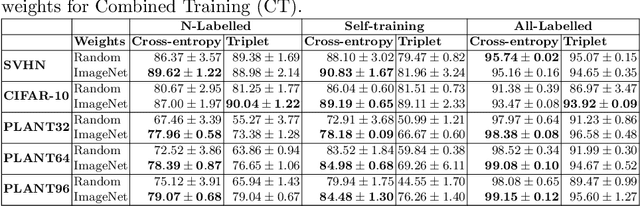
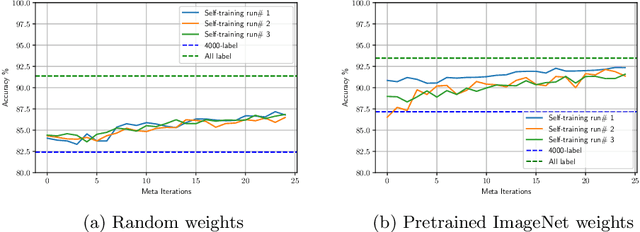
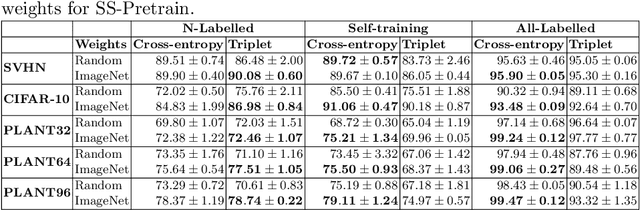
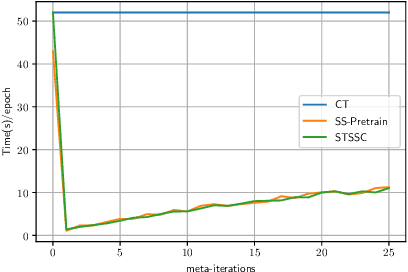
Self-training is a simple semi-supervised learning approach: Unlabelled examples that attract high-confidence predictions are labelled with their predictions and added to the training set, with this process being repeated multiple times. Recently, self-supervision -- learning without manual supervision by solving an automatically-generated pretext task -- has gained prominence in deep learning. This paper investigates three different ways of incorporating self-supervision into self-training to improve accuracy in image classification: self-supervision as pretraining only, self-supervision performed exclusively in the first iteration of self-training, and self-supervision added to every iteration of self-training. Empirical results on the SVHN, CIFAR-10, and PlantVillage datasets, using both training from scratch, and Imagenet-pretrained weights, show that applying self-supervision only in the first iteration of self-training can greatly improve accuracy, for a modest increase in computation time.