 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeBetter Self-training for Image Classification through Self-supervision
Paper and Code
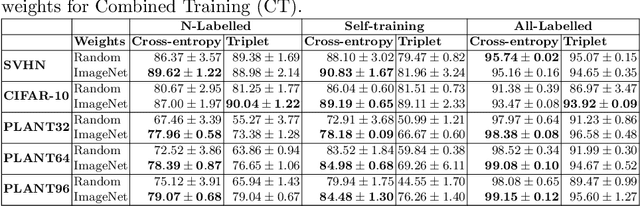
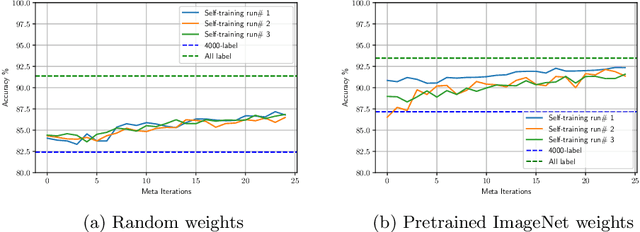
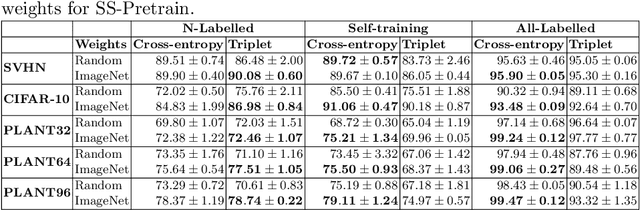
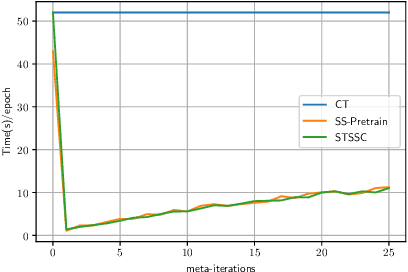
Self-training is a simple semi-supervised learning approach: Unlabelled examples that attract high-confidence predictions are labelled with their predictions and added to the training set, with this process being repeated multiple times. Recently, self-supervision -- learning without manual supervision by solving an automatically-generated pretext task -- has gained prominence in deep learning. This paper investigates three different ways of incorporating self-supervision into self-training to improve accuracy in image classification: self-supervision as pretraining only, self-supervision performed exclusively in the first iteration of self-training, and self-supervision added to every iteration of self-training. Empirical results on the SVHN, CIFAR-10, and PlantVillage datasets, using both training from scratch, and Imagenet-pretrained weights, show that applying self-supervision only in the first iteration of self-training can greatly improve accuracy, for a modest increase in computation time.