 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePolicy Gradient with Adaptive Entropy Annealing for Continual Fine-Tuning
Feb 15, 2026Despite their success, large pretrained vision models remain vulnerable to catastrophic forgetting when adapted to new tasks in class-incremental settings. Parameter-efficient fine-tuning (PEFT) alleviates this by restricting trainable parameters, yet most approaches still rely on cross-entropy (CE) loss, a surrogate for the 0-1 loss, to learn from new data. We revisit this choice and revive the true objective (0-1 loss) through a reinforcement learning perspective. By formulating classification as a one-step Markov Decision Process, we derive an Expected Policy Gradient (EPG) method that directly minimizes misclassification error with a low-variance gradient estimation. Our analysis shows that CE can be interpreted as EPG with an additional sample-weighting mechanism: CE encourages exploration by emphasizing low-confidence samples, while EPG prioritizes high-confidence ones. Building on this insight, we propose adaptive entropy annealing (aEPG), a training strategy that transitions from exploratory (CE-like) to exploitative (EPG-like) learning. aEPG-based methods outperform CE-based methods across diverse benchmarks and with various PEFT modules. More broadly, we evaluate various entropy regularization methods and demonstrate that lower entropy of the output prediction distribution enhances adaptation in pretrained vision models.
Fake News Classification in Urdu: A Domain Adaptation Approach for a Low-Resource Language
Dec 28, 2025Misinformation on social media is a widely acknowledged issue, and researchers worldwide are actively engaged in its detection. However, low-resource languages such as Urdu have received limited attention in this domain. An obvious approach is to utilize a multilingual pretrained language model and fine-tune it for a downstream classification task, such as misinformation detection. However, these models struggle with domain-specific terms, leading to suboptimal performance. To address this, we investigate the effectiveness of domain adaptation before fine-tuning for fake news classification in Urdu, employing a staged training approach to optimize model generalization. We evaluate two widely used multilingual models, XLM-RoBERTa and mBERT, and apply domain-adaptive pretraining using a publicly available Urdu news corpus. Experiments on four publicly available Urdu fake news datasets show that domain-adapted XLM-R consistently outperforms its vanilla counterpart, while domain-adapted mBERT exhibits mixed results.
Online Isolation Forest
May 14, 2025The anomaly detection literature is abundant with offline methods, which require repeated access to data in memory, and impose impractical assumptions when applied to a streaming context. Existing online anomaly detection methods also generally fail to address these constraints, resorting to periodic retraining to adapt to the online context. We propose Online-iForest, a novel method explicitly designed for streaming conditions that seamlessly tracks the data generating process as it evolves over time. Experimental validation on real-world datasets demonstrated that Online-iForest is on par with online alternatives and closely rivals state-of-the-art offline anomaly detection techniques that undergo periodic retraining. Notably, Online-iForest consistently outperforms all competitors in terms of efficiency, making it a promising solution in applications where fast identification of anomalies is of primary importance such as cybersecurity, fraud and fault detection.
CapyMOA: Efficient Machine Learning for Data Streams in Python
Feb 11, 2025

CapyMOA is an open-source library designed for efficient machine learning on streaming data. It provides a structured framework for real-time learning and evaluation, featuring a flexible data representation. CapyMOA includes an extensible architecture that allows integration with external frameworks such as MOA and PyTorch, facilitating hybrid learning approaches that combine traditional online algorithms with deep learning techniques. By emphasizing adaptability, scalability, and usability, CapyMOA allows researchers and practitioners to tackle dynamic learning challenges across various domains.
Evaluation for Regression Analyses on Evolving Data Streams
Feb 11, 2025



The paper explores the challenges of regression analysis in evolving data streams, an area that remains relatively underexplored compared to classification. We propose a standardized evaluation process for regression and prediction interval tasks in streaming contexts. Additionally, we introduce an innovative drift simulation strategy capable of synthesizing various drift types, including the less-studied incremental drift. Comprehensive experiments with state-of-the-art methods, conducted under the proposed process, validate the effectiveness and robustness of our approach.
Optimizing Hyperparameters for Quantum Data Re-Uploaders in Calorimetric Particle Identification
Dec 16, 2024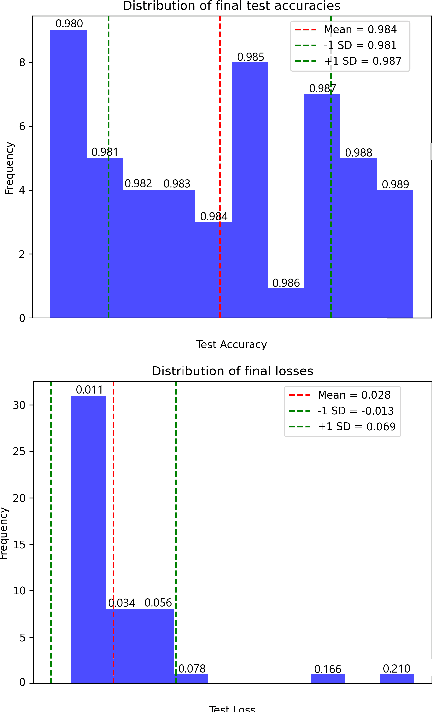

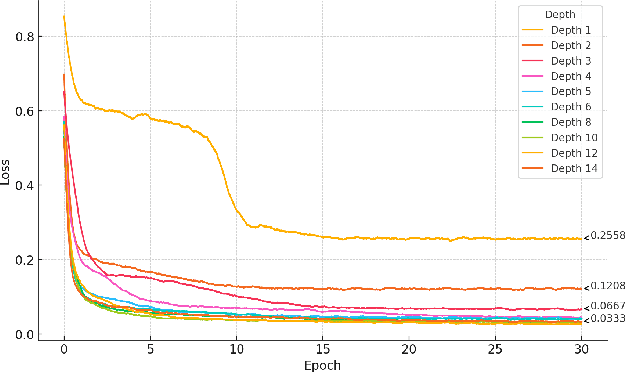

We present an application of a single-qubit Data Re-Uploading (QRU) quantum model for particle classification in calorimetric experiments. Optimized for Noisy Intermediate-Scale Quantum (NISQ) devices, this model requires minimal qubits while delivering strong classification performance. Evaluated on a novel simulated dataset specific to particle physics, the QRU model achieves high accuracy in classifying particle types. Through a systematic exploration of model hyperparameters -- such as circuit depth, rotation gates, input normalization and the number of trainable parameters per input -- and training parameters like batch size, optimizer, loss function and learning rate, we assess their individual impacts on model accuracy and efficiency. Additionally, we apply global optimization methods, uncovering hyperparameter correlations that further enhance performance. Our results indicate that the QRU model attains significant accuracy with efficient computational costs, underscoring its potential for practical quantum machine learning applications.
Detection of Human and Machine-Authored Fake News in Urdu
Oct 25, 2024The rise of social media has amplified the spread of fake news, now further complicated by large language models (LLMs) like ChatGPT, which ease the generation of highly convincing, error-free misinformation, making it increasingly challenging for the public to discern truth from falsehood. Traditional fake news detection methods relying on linguistic cues also becomes less effective. Moreover, current detectors primarily focus on binary classification and English texts, often overlooking the distinction between machine-generated true vs. fake news and the detection in low-resource languages. To this end, we updated detection schema to include machine-generated news with focus on the Urdu language. We further propose a hierarchical detection strategy to improve the accuracy and robustness. Experiments show its effectiveness across four datasets in various settings.
Real-Time Energy Pricing in New Zealand: An Evolving Stream Analysis
Aug 29, 2024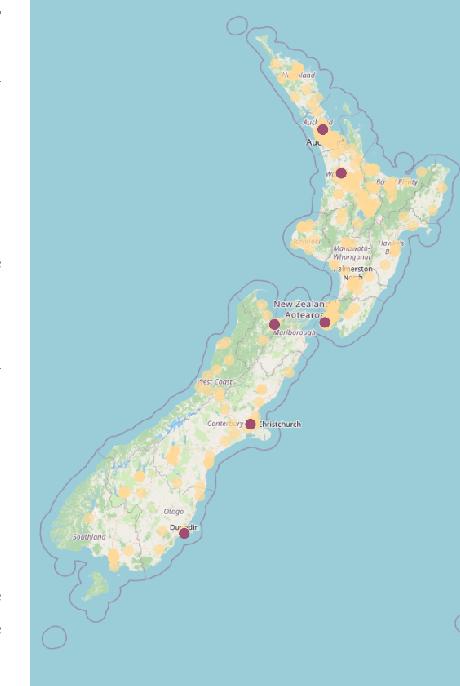
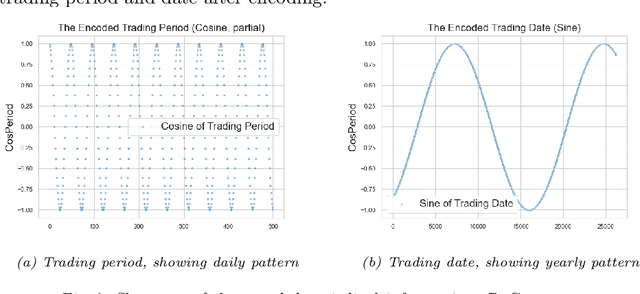
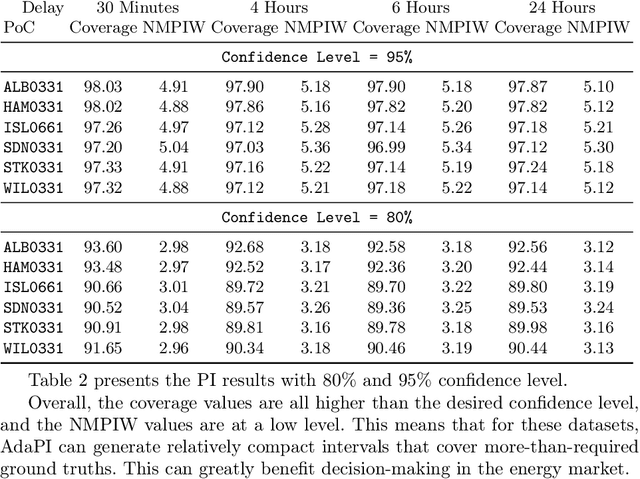
This paper introduces a group of novel datasets representing real-time time-series and streaming data of energy prices in New Zealand, sourced from the Electricity Market Information (EMI) website maintained by the New Zealand government. The datasets are intended to address the scarcity of proper datasets for streaming regression learning tasks. We conduct extensive analyses and experiments on these datasets, covering preprocessing techniques, regression tasks, prediction intervals, concept drift detection, and anomaly detection. Our experiments demonstrate the datasets' utility and highlight the challenges and opportunities for future research in energy price forecasting.
Look At Me, No Replay! SurpriseNet: Anomaly Detection Inspired Class Incremental Learning
Oct 30, 2023

Continual learning aims to create artificial neural networks capable of accumulating knowledge and skills through incremental training on a sequence of tasks. The main challenge of continual learning is catastrophic interference, wherein new knowledge overrides or interferes with past knowledge, leading to forgetting. An associated issue is the problem of learning "cross-task knowledge," where models fail to acquire and retain knowledge that helps differentiate classes across task boundaries. A common solution to both problems is "replay," where a limited buffer of past instances is utilized to learn cross-task knowledge and mitigate catastrophic interference. However, a notable drawback of these methods is their tendency to overfit the limited replay buffer. In contrast, our proposed solution, SurpriseNet, addresses catastrophic interference by employing a parameter isolation method and learning cross-task knowledge using an auto-encoder inspired by anomaly detection. SurpriseNet is applicable to both structured and unstructured data, as it does not rely on image-specific inductive biases. We have conducted empirical experiments demonstrating the strengths of SurpriseNet on various traditional vision continual-learning benchmarks, as well as on structured data datasets. Source code made available at https://doi.org/10.5281/zenodo.8247906 and https://github.com/tachyonicClock/SurpriseNet-CIKM-23
A simple but strong baseline for online continual learning: Repeated Augmented Rehearsal
Sep 28, 2022
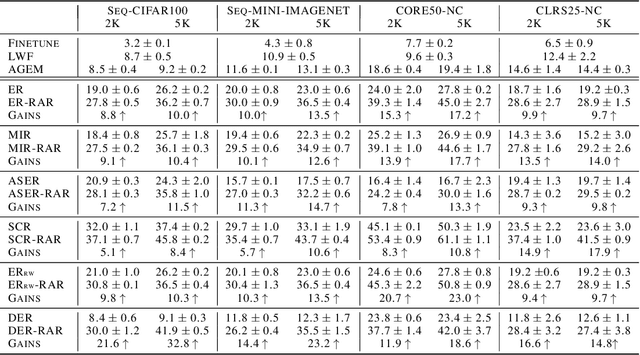
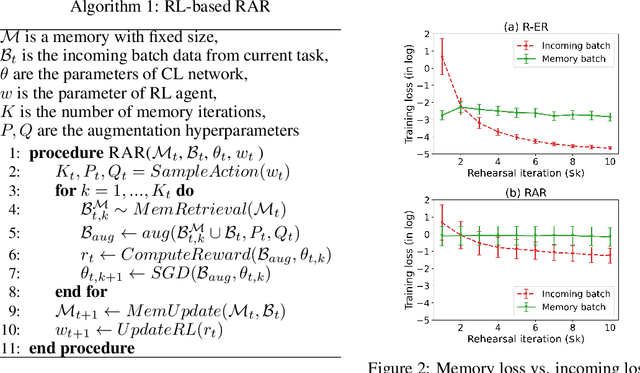
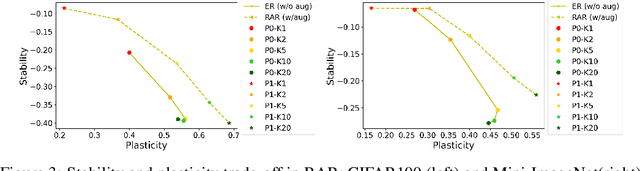
Online continual learning (OCL) aims to train neural networks incrementally from a non-stationary data stream with a single pass through data. Rehearsal-based methods attempt to approximate the observed input distributions over time with a small memory and revisit them later to avoid forgetting. Despite its strong empirical performance, rehearsal methods still suffer from a poor approximation of the loss landscape of past data with memory samples. This paper revisits the rehearsal dynamics in online settings. We provide theoretical insights on the inherent memory overfitting risk from the viewpoint of biased and dynamic empirical risk minimization, and examine the merits and limits of repeated rehearsal. Inspired by our analysis, a simple and intuitive baseline, Repeated Augmented Rehearsal (RAR), is designed to address the underfitting-overfitting dilemma of online rehearsal. Surprisingly, across four rather different OCL benchmarks, this simple baseline outperforms vanilla rehearsal by 9%-17% and also significantly improves state-of-the-art rehearsal-based methods MIR, ASER, and SCR. We also demonstrate that RAR successfully achieves an accurate approximation of the loss landscape of past data and high-loss ridge aversion in its learning trajectory. Extensive ablation studies are conducted to study the interplay between repeated and augmented rehearsal and reinforcement learning (RL) is applied to dynamically adjust the hyperparameters of RAR to balance the stability-plasticity trade-off online.