 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeEntropy-based Guidance of Deep Neural Networks for Accelerated Convergence and Improved Performance
Aug 28, 2023



Neural networks have dramatically increased our capacity to learn from large, high-dimensional datasets across innumerable disciplines. However, their decisions are not easily interpretable, their computational costs are high, and building and training them are uncertain processes. To add structure to these efforts, we derive new mathematical results to efficiently measure the changes in entropy as fully-connected and convolutional neural networks process data, and introduce entropy-based loss terms. Experiments in image compression and image classification on benchmark datasets demonstrate these losses guide neural networks to learn rich latent data representations in fewer dimensions, converge in fewer training epochs, and achieve better test metrics.
Keep It Simple: Fault Tolerance Evaluation of Federated Learning with Unreliable Clients
May 16, 2023Federated learning (FL), as an emerging artificial intelligence (AI) approach, enables decentralized model training across multiple devices without exposing their local training data. FL has been increasingly gaining popularity in both academia and industry. While research works have been proposed to improve the fault tolerance of FL, the real impact of unreliable devices (e.g., dropping out, misconfiguration, poor data quality) in real-world applications is not fully investigated. We carefully chose two representative, real-world classification problems with a limited numbers of clients to better analyze FL fault tolerance. Contrary to the intuition, simple FL algorithms can perform surprisingly well in the presence of unreliable clients.
Cross-domain Few-shot Meta-learning Using Stacking
May 12, 2022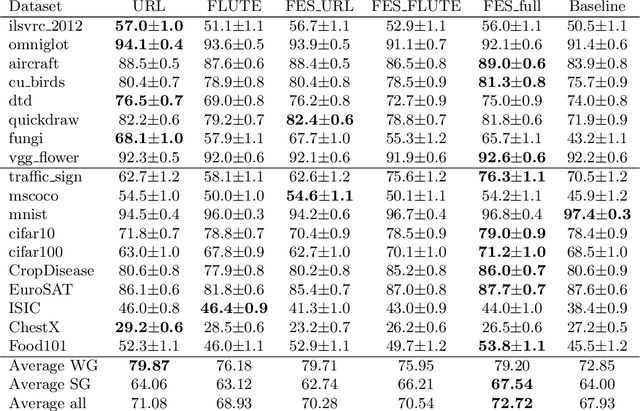
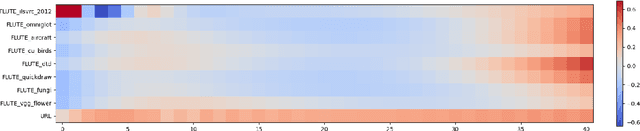
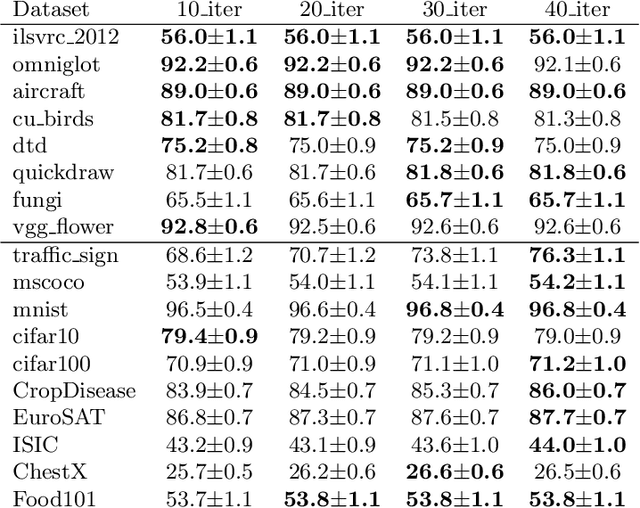
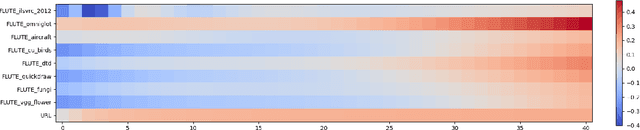
Cross-domain few-shot meta-learning (CDFSML) addresses learning problems where knowledge needs to be transferred from several source domains into an instance-scarce target domain with an explicitly different input distribution. Recently published CDFSML methods generally construct a "universal model" that combines knowledge of multiple source domains into one backbone feature extractor. This enables efficient inference but necessitates re-computation of the backbone whenever a new source domain is added. Moreover, state-of-the-art methods derive their universal model from a collection of backbones -- normally one for each source domain -- and the backbones may be constrained to have the same architecture as the universal model. We propose a CDFSML method that is inspired by the classic stacking approach to meta learning. It imposes no constraints on the backbones' architecture or feature shape and does not incur the computational overhead of (re-)computing a universal model. Given a target-domain task, it fine-tunes each backbone independently, uses cross-validation to extract meta training data from the task's instance-scarce support set, and learns a simple linear meta classifier from this data. We evaluate our stacking approach on the well-known Meta-Dataset benchmark, targeting image classification with convolutional neural networks, and show that it often yields substantially higher accuracy than competing methods.
Automatic end-to-end De-identification: Is high accuracy the only metric?
Jan 27, 2019



De-identification of electronic health records (EHR) is a vital step towards advancing health informatics research and maximising the use of available data. It is a two-step process where step one is the identification of protected health information (PHI), and step two is replacing such PHI with surrogates. Despite the recent advances in automatic de-identification of EHR, significant obstacles remain if the abundant health data available are to be used to the full potential. Accuracy in de-identification could be considered a necessary, but not sufficient condition for the use of EHR without individual patient consent. We present here a comprehensive review of the progress to date, both the impressive successes in achieving high accuracy and the significant risks and challenges that remain. To best of our knowledge, this is the first paper to present a complete picture of end-to-end automatic de-identification. We review 18 recently published automatic de-identification systems -designed to de-identify EHR in the form of free text- to show the advancements made in improving the overall accuracy of the system, and in identifying individual PHI. We argue that despite the improvements in accuracy there remain challenges in surrogate generation and replacements of identified PHIs, and the risks posed to patient protection and privacy.
A survey of automatic de-identification of longitudinal clinical narratives
Oct 16, 2018

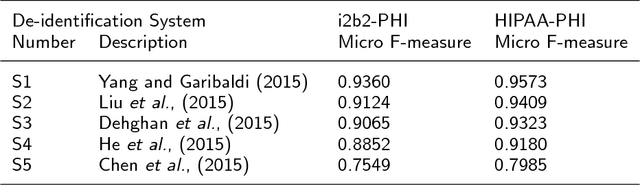
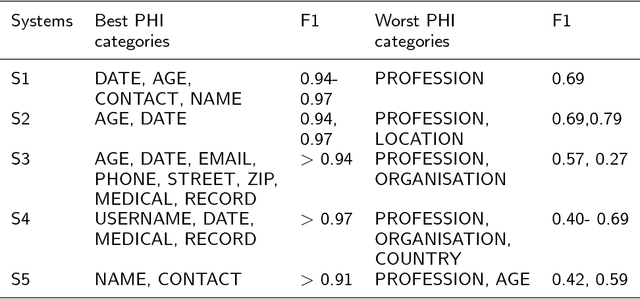
Use of medical data, also known as electronic health records, in research helps develop and advance medical science. However, protecting patient confidentiality and identity while using medical data for analysis is crucial. Medical data can be in the form of tabular structures (i.e. tables), free-form narratives, and images. This study focuses on medical data in the free form longitudinal text. De-identification of electronic health records provides the opportunity to use such data for research without it affecting patient privacy, and avoids the need for individual patient consent. In recent years there is increasing interest in developing an accurate, robust and adaptable automatic de-identification system for electronic health records. This is mainly due to the dilemma between the availability of an abundance of health data, and the inability to use such data in research due to legal and ethical restrictions. De-identification tracks in competitions such as the 2014 i2b2 UTHealth and the 2016 CEGS N-GRID shared tasks have provided a great platform to advance this area. The primary reasons for this include the open source nature of the dataset and the fact that raw psychiatric data were used for 2016 competitions. This study focuses on noticeable trend changes in the techniques used in the development of automatic de-identification for longitudinal clinical narratives. More specifically, the shift from using conditional random fields (CRF) based systems only or rules (regular expressions, dictionary or combinations) based systems only, to hybrid models (combining CRF and rules), and more recently to deep learning based systems. We review the literature and results that arose from the 2014 and the 2016 competitions and discuss the outcomes of these systems. We also provide a list of research questions that emerged from this survey.
Using Swarm Optimization To Enhance Autoencoders Images
Jul 09, 2018
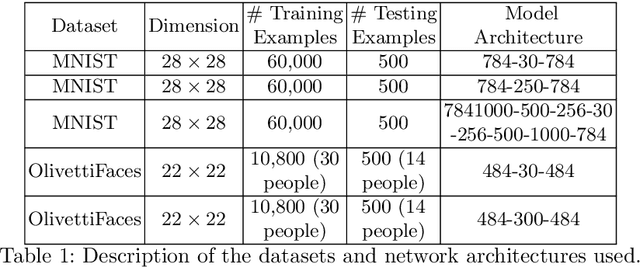
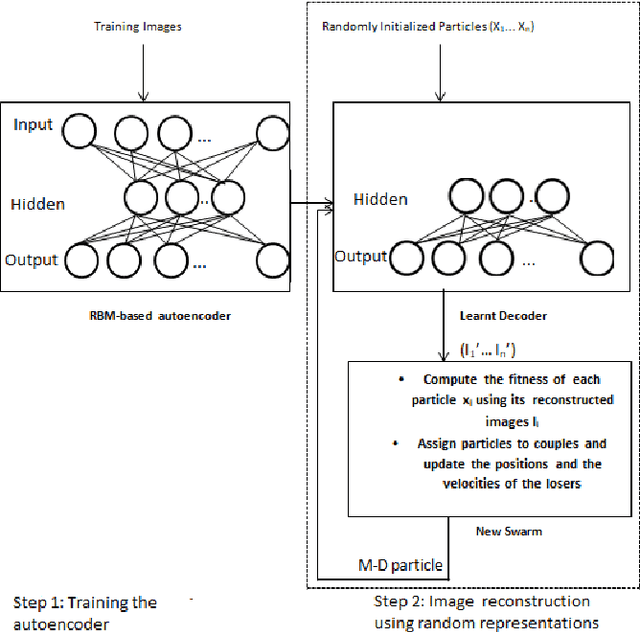
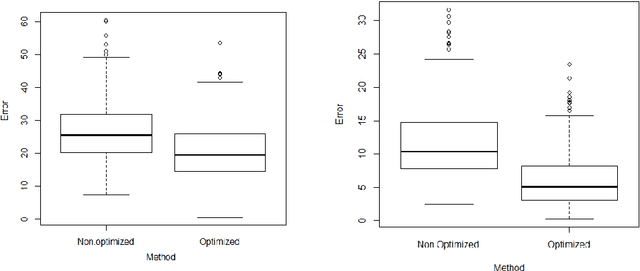
Autoencoders learn data representations through reconstruction. Robust training is the key factor affecting the quality of the learned representations and, consequently, the accuracy of the application that use them. Previous works suggested methods for deciding the optimal autoencoder configuration which allows for robust training. Nevertheless, improving the accuracy of a trained autoencoder has got limited, if no, attention. We propose a new approach that improves the accuracy of a trained autoencoders results and answers the following question, Given a trained autoencoder, a test image, and using a real-parameter optimizer, can we generate better quality reconstructed image version than the one generated by the autoencoder?. Our proposed approach combines both the decoder part of a trained Resitricted Boltman Machine-based autoencoder with the Competitive Swarm Optimization algorithm. Experiments show that it is possible to reconstruct images using trained decoder from randomly initialized representations. Results also show that our approach reconstructed better quality images than the autoencoder in most of the test cases. Indicating that, we can use the approach for improving the performance of a pre-trained autoencoder if it does not give satisfactory results.
* 14 pages,2 figures and 17 graphs, conference paper (MDAI2017) http://mdai.cat/mdai2017/mdai2017.usb.pdf
Improving Naive Bayes for Regression with Optimised Artificial Surrogate Data
Oct 10, 2017



Can we evolve better training data for machine learning algorithms? To investigate this question we use population-based optimisation algorithms to generate artificial surrogate training data for naive Bayes for regression. We demonstrate that the generalisation performance of naive Bayes for regression models is enhanced by training them on the artificial data as opposed to the real data. These results are important for two reasons. Firstly, naive Bayes models are simple and interpretable but frequently underperform compared to more complex "black box" models, and therefore new methods of enhancing accuracy are called for. Secondly, the idea of using the real training data indirectly in the construction of the artificial training data, as opposed to directly for model training, is a novel twist on the usual machine learning paradigm.