 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLearning to Solve Climate Sensor Placement Problems with a Transformer
Oct 18, 2023The optimal placement of sensors for environmental monitoring and disaster management is a challenging problem due to its NP-hard nature. Traditional methods for sensor placement involve exact, approximation, or heuristic approaches, with the latter being the most widely used. However, heuristic methods are limited by expert intuition and experience. Deep learning (DL) has emerged as a promising approach for generating heuristic algorithms automatically. In this paper, we introduce a novel sensor placement approach focused on learning improvement heuristics using deep reinforcement learning (RL) methods. Our approach leverages an RL formulation for learning improvement heuristics, driven by an actor-critic algorithm for training the policy network. We compare our method with several state-of-the-art approaches by conducting comprehensive experiments, demonstrating the effectiveness and superiority of our proposed approach in producing high-quality solutions. Our work presents a promising direction for applying advanced DL and RL techniques to challenging climate sensor placement problems.
Deep Metric Tensor Regularized Policy Gradient
May 18, 2023Policy gradient algorithms are an important family of deep reinforcement learning techniques. Many past research endeavors focused on using the first-order policy gradient information to train policy networks. Different from these works, we conduct research in this paper driven by the believe that properly utilizing and controlling Hessian information associated with the policy gradient can noticeably improve the performance of policy gradient algorithms. One key Hessian information that attracted our attention is the Hessian trace, which gives the divergence of the policy gradient vector field in the Euclidean policy parametric space. We set the goal to generalize this Euclidean policy parametric space into a general Riemmanian manifold by introducing a metric tensor field $g_ab$ in the parametric space. This is achieved through newly developed mathematical tools, deep learning algorithms, and metric tensor deep neural networks (DNNs). Armed with these technical developments, we propose a new policy gradient algorithm that learns to minimize the absolute divergence in the Riemannian manifold as an important regularization mechanism, allowing the Riemannian manifold to smoothen its policy gradient vector field. The newly developed algorithm is experimentally studied on several benchmark reinforcement learning problems. Our experiments clearly show that the new metric tensor regularized algorithm can significantly outperform its counterpart that does not use our regularization technique. Additional experimental analysis further suggests that the trained metric tensor DNN and the corresponding metric tensor $g_{ab}$ can effectively reduce the absolute divergence towards zero in the Riemannian manifold.
Keep It Simple: Fault Tolerance Evaluation of Federated Learning with Unreliable Clients
May 16, 2023Federated learning (FL), as an emerging artificial intelligence (AI) approach, enables decentralized model training across multiple devices without exposing their local training data. FL has been increasingly gaining popularity in both academia and industry. While research works have been proposed to improve the fault tolerance of FL, the real impact of unreliable devices (e.g., dropping out, misconfiguration, poor data quality) in real-world applications is not fully investigated. We carefully chose two representative, real-world classification problems with a limited numbers of clients to better analyze FL fault tolerance. Contrary to the intuition, simple FL algorithms can perform surprisingly well in the presence of unreliable clients.
Hierarchical Training of Deep Ensemble Policies for Reinforcement Learning in Continuous Spaces
Sep 29, 2022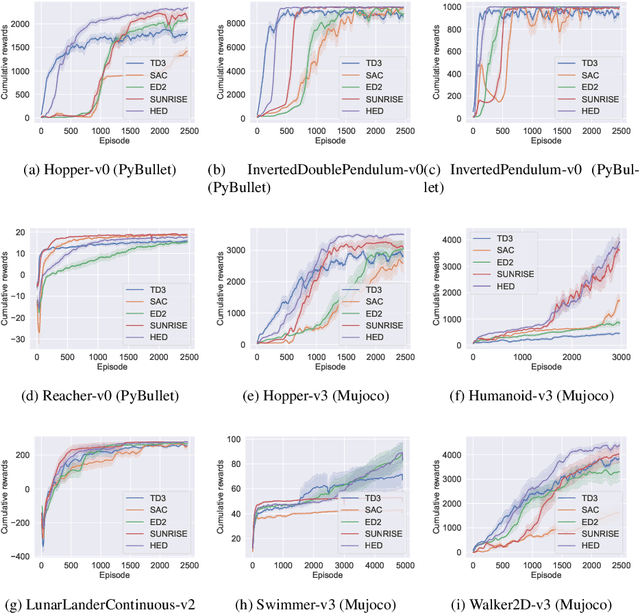
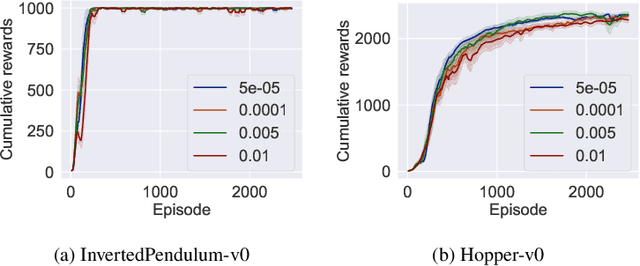
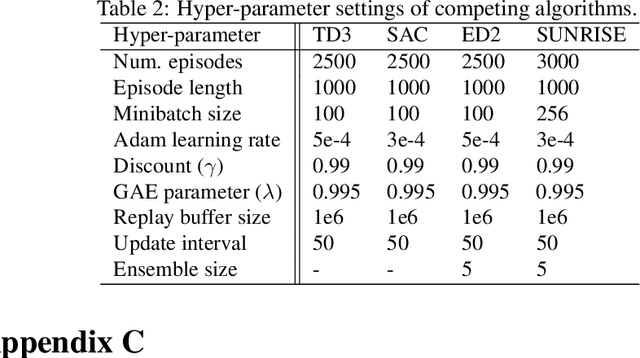
Many actor-critic deep reinforcement learning (DRL) algorithms have achieved cutting-edge performance in tackling various challenging reinforcement learning (RL) problems, including complex control tasks with high-dimensional continuous state and action spaces. Despite of widely reported success, existing DRL algorithms often suffer from the ineffective exploration issue, resulting in limited learning stability and performance. To address this limitation, several ensemble DRL algorithms have been proposed recently to boost exploration and stabilize the learning process. However, many existing ensemble algorithms are designed to train each base learner individually without controlling explicitly the collaboration among the trained base learners. In this paper, we propose a new technique to train an ensemble of base learners based on the multi-step integration methods. The new multi-step training technique enables us to develop a new hierarchical training algorithm for ensemble DRL that promotes inter-learner collaboration through explicit inter-learner parameter sharing. The design of our new algorithm is verified theoretically. The algorithm is also shown empirically to outperform several cutting-edge DRL algorithms on multiple benchmark RL problems.
Multi-Agent Deep Reinforcement Learning for Request Dispatching in Distributed-Controller Software-Defined Networking
Feb 06, 2021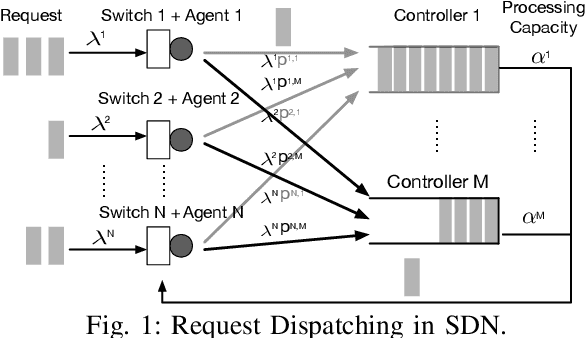
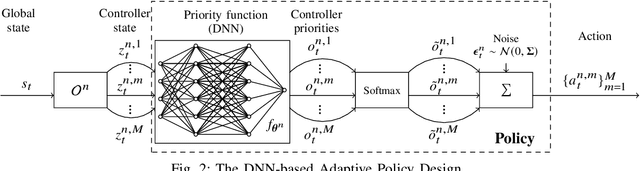

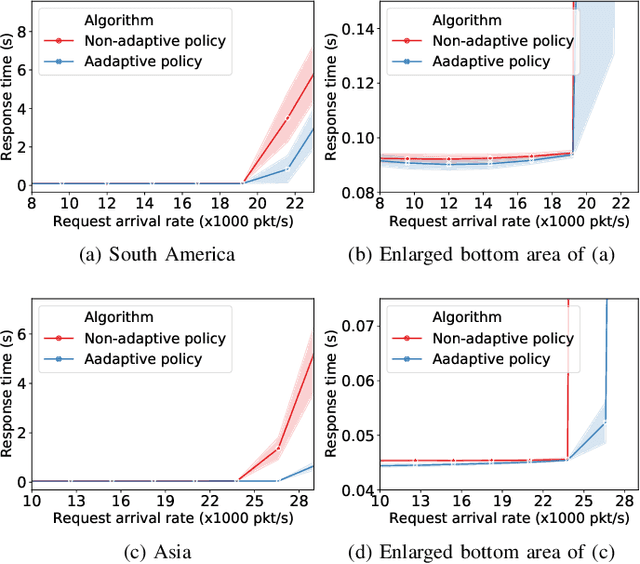
Recently, distributed controller architectures have been quickly gaining popularity in Software-Defined Networking (SDN). However, the use of distributed controllers introduces a new and important Request Dispatching (RD) problem with the goal for every SDN switch to properly dispatch their requests among all controllers so as to optimize network performance. This goal can be fulfilled by designing an RD policy to guide distribution of requests at each switch. In this paper, we propose a Multi-Agent Deep Reinforcement Learning (MA-DRL) approach to automatically design RD policies with high adaptability and performance. This is achieved through a new problem formulation in the form of a Multi-Agent Markov Decision Process (MA-MDP), a new adaptive RD policy design and a new MA-DRL algorithm called MA-PPO. Extensive simulation studies show that our MA-DRL technique can effectively train RD policies to significantly outperform man-made policies, model-based policies, as well as RD policies learned via single-agent DRL algorithms.
Optimizing Controller Placement for Software-Defined Networks
Feb 14, 2019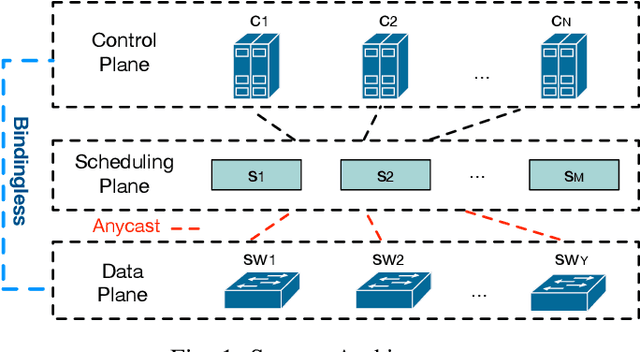
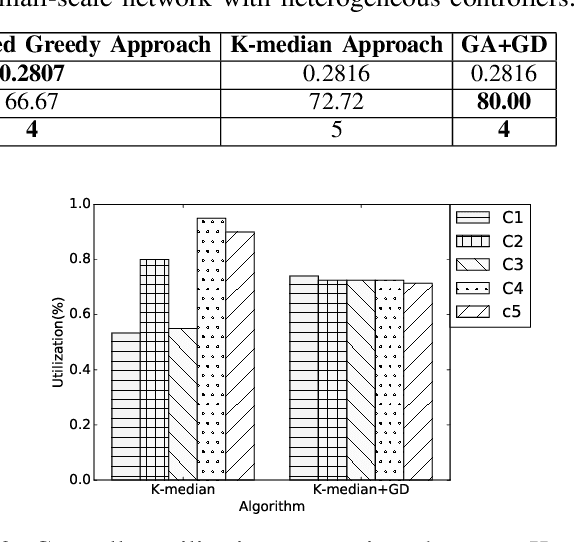
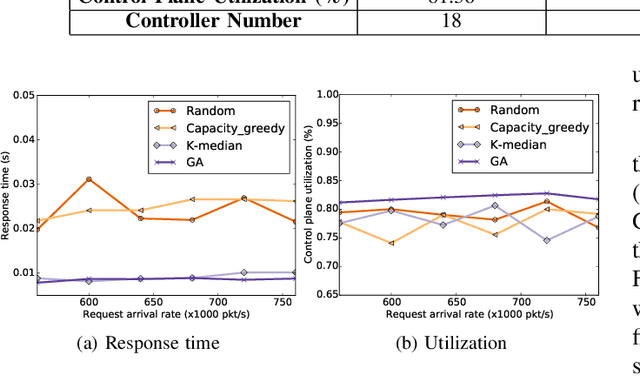
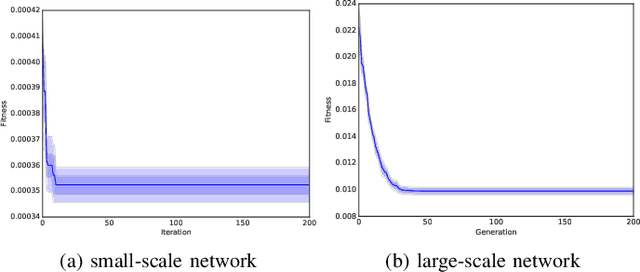
Controller placement problem (CPP) is a key issue for Software-Defined Networking (SDN) with distributed controller architectures. This problem aims to determine a suitable number of controllers deployed in important locations so as to optimize the overall network performance. In comparison to communication delay, existing literature on the CPP assumes that the influence of controller workload distribution on network performance is negligible. In this paper, we tackle the CPP that simultaneously considers the communication delay, the control plane utilization, and the controller workload distribution. Due to this reason, our CPP is intrinsically different from and clearly more difficult than any previously studied CPPs that are NP-hard. To tackle this challenging issue, we develop a new algorithm that seamlessly integrates the genetic algorithm (GA) and the gradient descent (GD) optimization method. Particularly, GA is used to search for suitable CPP solutions. The quality of each solution is further evaluated through GD. Simulation results on two representative network scenarios (small-scale and large-scale) show that our algorithm can effectively strike the trade-off between the control plane utilization and the network response time.