 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeRethinking Perplexity: Revealing the Impact of Input Length on Perplexity Evaluation in LLMs
Feb 04, 2026Perplexity is a widely adopted metric for assessing the predictive quality of large language models (LLMs) and often serves as a reference metric for downstream evaluations. However, recent evidence shows that perplexity can be unreliable, especially when irrelevant long inputs are used, raising concerns for both benchmarking and system deployment. While prior efforts have employed selective input filtering and curated datasets, the impact of input length on perplexity has not been systematically studied from a systems perspective and input length has rarely been treated as a first-class system variable affecting both fairness and efficiency. In this work, we close this gap by introducing LengthBenchmark, a system-conscious evaluation framework that explicitly integrates input length, evaluation protocol design, and system-level costs, evaluating representative LLMs under two scoring protocols (direct accumulation and fixed window sliding) across varying context lengths. Unlike prior work that focuses solely on accuracy-oriented metrics, LengthBenchmark additionally measures latency, memory footprint, and evaluation cost, thereby linking predictive metrics to deployment realities. We further incorporate quantized variants not as a main contribution, but as robustness checks, showing that length-induced biases persist across both full-precision and compressed models. This design disentangles the effects of evaluation logic, quantization, and input length, and demonstrates that length bias is a general phenomenon that undermines fair cross-model comparison. Our analysis yields two key observations: (i) sliding window evaluation consistently inflates performance on short inputs, and (ii) both full-precision and quantized models appear to realise gains as the evaluated segment length grows.
VR.net: A Real-world Dataset for Virtual Reality Motion Sickness Research
Jun 06, 2023Researchers have used machine learning approaches to identify motion sickness in VR experience. These approaches demand an accurately-labeled, real-world, and diverse dataset for high accuracy and generalizability. As a starting point to address this need, we introduce `VR.net', a dataset offering approximately 12-hour gameplay videos from ten real-world games in 10 diverse genres. For each video frame, a rich set of motion sickness-related labels, such as camera/object movement, depth field, and motion flow, are accurately assigned. Building such a dataset is challenging since manual labeling would require an infeasible amount of time. Instead, we utilize a tool to automatically and precisely extract ground truth data from 3D engines' rendering pipelines without accessing VR games' source code. We illustrate the utility of VR.net through several applications, such as risk factor detection and sickness level prediction. We continuously expand VR.net and envision its next version offering 10X more data than the current form. We believe that the scale, accuracy, and diversity of VR.net can offer unparalleled opportunities for VR motion sickness research and beyond.
Improving the Domain Adaptation of Retrieval Augmented Generation (RAG) Models for Open Domain Question Answering
Oct 06, 2022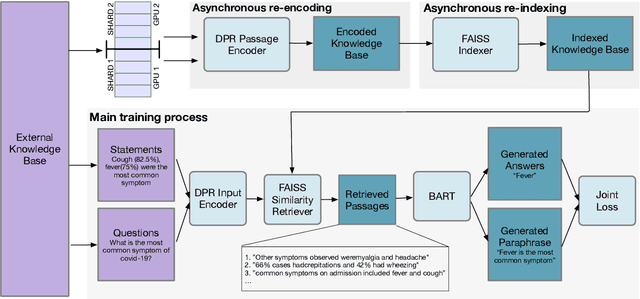
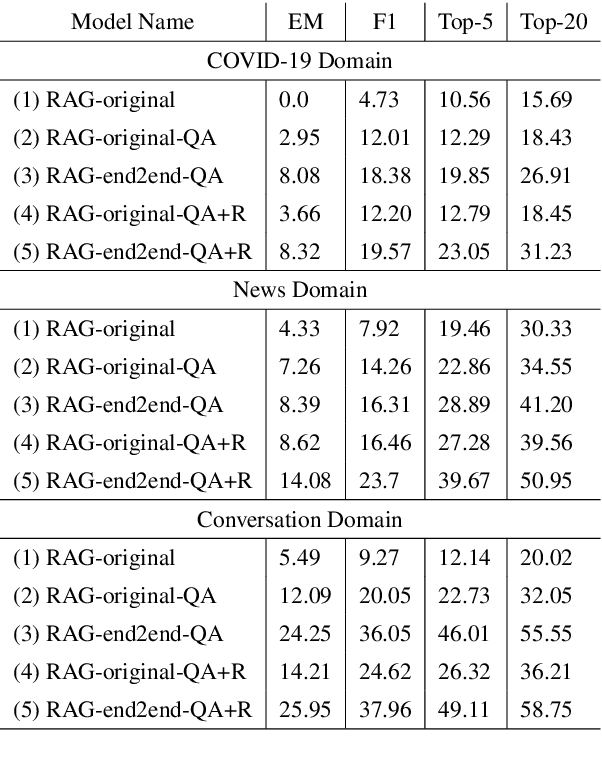
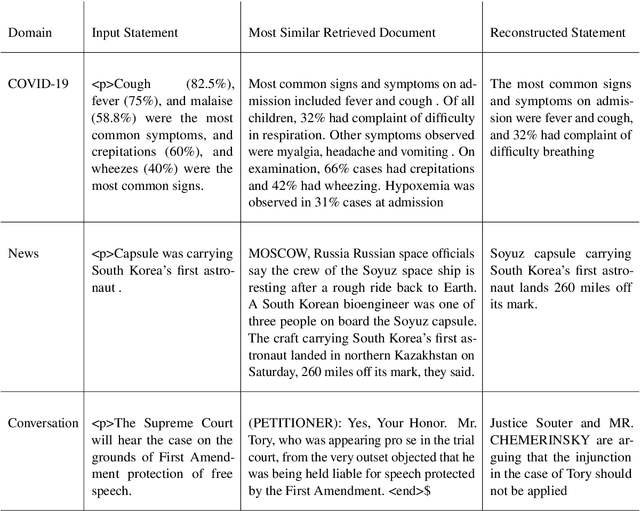
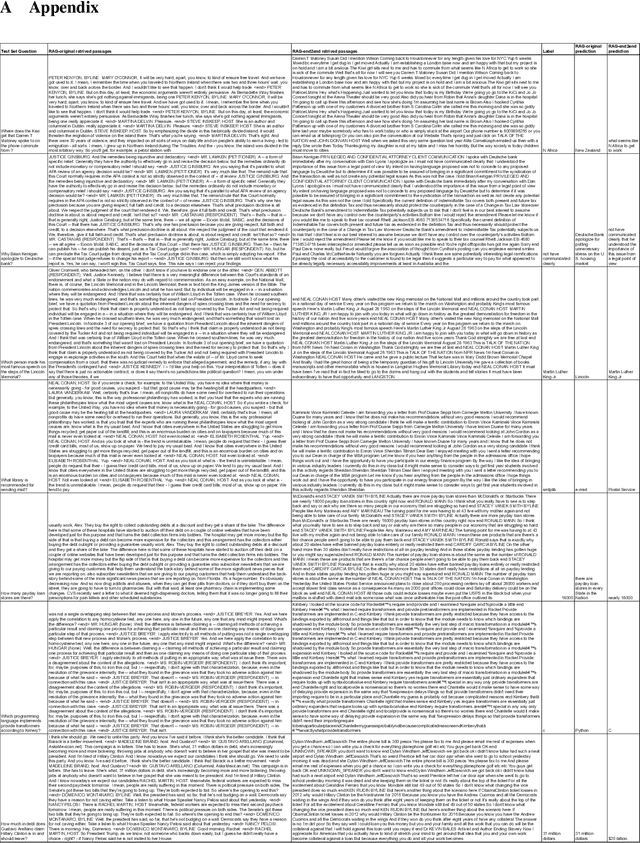
Retrieval Augment Generation (RAG) is a recent advancement in Open-Domain Question Answering (ODQA). RAG has only been trained and explored with a Wikipedia-based external knowledge base and is not optimized for use in other specialized domains such as healthcare and news. In this paper, we evaluate the impact of joint training of the retriever and generator components of RAG for the task of domain adaptation in ODQA. We propose \textit{RAG-end2end}, an extension to RAG, that can adapt to a domain-specific knowledge base by updating all components of the external knowledge base during training. In addition, we introduce an auxiliary training signal to inject more domain-specific knowledge. This auxiliary signal forces \textit{RAG-end2end} to reconstruct a given sentence by accessing the relevant information from the external knowledge base. Our novel contribution is unlike RAG, RAG-end2end does joint training of the retriever and generator for the end QA task and domain adaptation. We evaluate our approach with datasets from three domains: COVID-19, News, and Conversations, and achieve significant performance improvements compared to the original RAG model. Our work has been open-sourced through the Huggingface Transformers library, attesting to our work's credibility and technical consistency.
Fine-tune the Entire RAG Architecture for Question-Answering
Jun 22, 2021In this paper, we illustrate how to fine-tune the entire Retrieval Augment Generation (RAG) architecture in an end-to-end manner. We highlighted the main engineering challenges that needed to be addressed to achieve this objective. We also compare how end-to-end RAG architecture outperforms the original RAG architecture for the task of question answering. We have open-sourced our implementation in the HuggingFace Transformers library.
Optimizing Controller Placement for Software-Defined Networks
Feb 14, 2019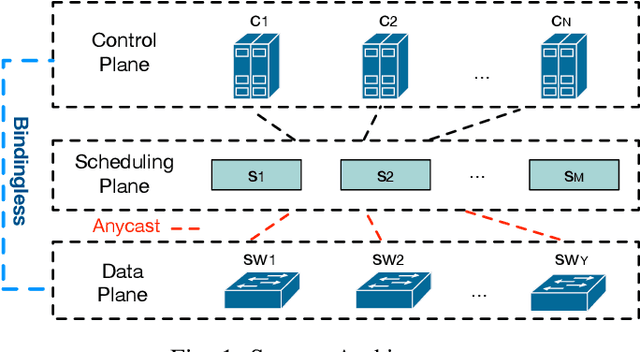
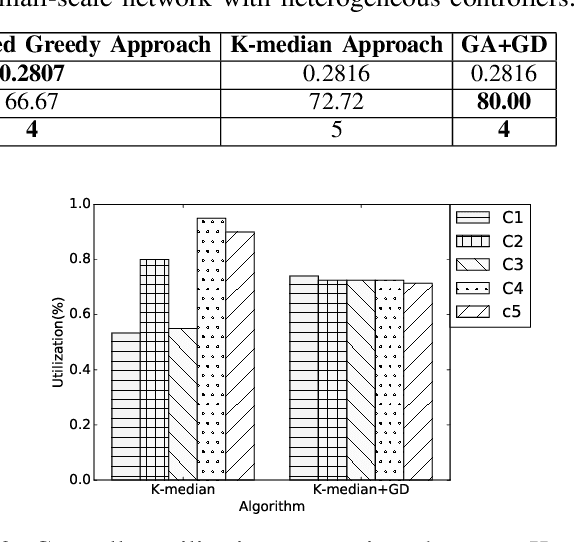
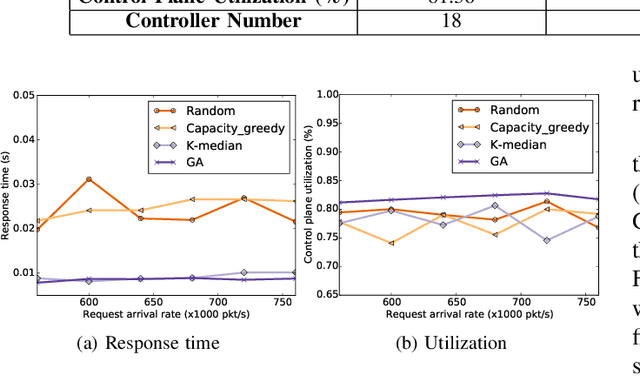
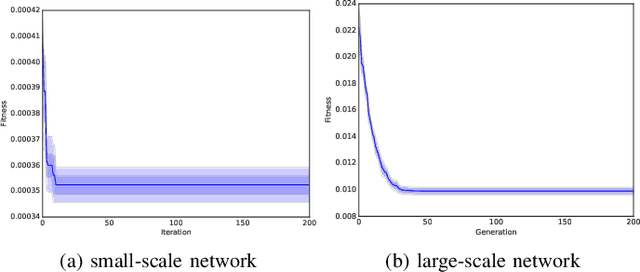
Controller placement problem (CPP) is a key issue for Software-Defined Networking (SDN) with distributed controller architectures. This problem aims to determine a suitable number of controllers deployed in important locations so as to optimize the overall network performance. In comparison to communication delay, existing literature on the CPP assumes that the influence of controller workload distribution on network performance is negligible. In this paper, we tackle the CPP that simultaneously considers the communication delay, the control plane utilization, and the controller workload distribution. Due to this reason, our CPP is intrinsically different from and clearly more difficult than any previously studied CPPs that are NP-hard. To tackle this challenging issue, we develop a new algorithm that seamlessly integrates the genetic algorithm (GA) and the gradient descent (GD) optimization method. Particularly, GA is used to search for suitable CPP solutions. The quality of each solution is further evaluated through GD. Simulation results on two representative network scenarios (small-scale and large-scale) show that our algorithm can effectively strike the trade-off between the control plane utilization and the network response time.