 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeBeyond Descriptions: A Generative Scene2Audio Framework for Blind and Low-Vision Users to Experience Vista Landscapes
Mar 28, 2026Current scene perception tools for Blind and Low Vision (BLV) individuals rely on spoken descriptions but lack engaging representations of visually pleasing distant environmental landscapes (Vista spaces). Our proposed Scene2Audio framework generates comprehensible and enjoyable nonverbal audio using generative models informed by psychoacoustics, and principles of scene audio composition. Through a user study with 11 BLV participants, we found that combining the Scene2Audio sounds with speech creates a better experience than speech alone, as the sound effects complement the speech making the scene easier to imagine. A mobile app "in-the-wild" study with 7 BLV users for more than a week further showed the potential of Scene2Audio in enhancing outdoor scene experiences. Our work bridges the gap between visual and auditory scene perception by moving beyond purely descriptive aids, addressing the aesthetic needs of BLV users.
MorphFader: Enabling Fine-grained Controllable Morphing with Text-to-Audio Models
Aug 14, 2024Sound morphing is the process of gradually and smoothly transforming one sound into another to generate novel and perceptually hybrid sounds that simultaneously resemble both. Recently, diffusion-based text-to-audio models have produced high-quality sounds using text prompts. However, granularly controlling the semantics of the sound, which is necessary for morphing, can be challenging using text. In this paper, we propose \textit{MorphFader}, a controllable method for morphing sounds generated by disparate prompts using text-to-audio models. By intercepting and interpolating the components of the cross-attention layers within the diffusion process, we can create smooth morphs between sounds generated by different text prompts. Using both objective metrics and perceptual listening tests, we demonstrate the ability of our method to granularly control the semantics in the sound and generate smooth morphs.
EMO-KNOW: A Large Scale Dataset on Emotion and Emotion-cause
Jun 18, 2024
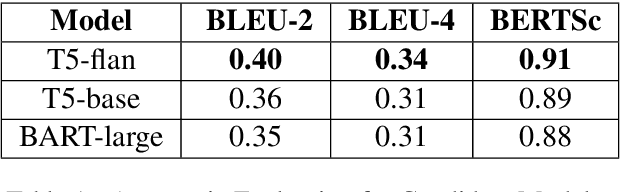

Emotion-Cause analysis has attracted the attention of researchers in recent years. However, most existing datasets are limited in size and number of emotion categories. They often focus on extracting parts of the document that contain the emotion cause and fail to provide more abstractive, generalizable root cause. To bridge this gap, we introduce a large-scale dataset of emotion causes, derived from 9.8 million cleaned tweets over 15 years. We describe our curation process, which includes a comprehensive pipeline for data gathering, cleaning, labeling, and validation, ensuring the dataset's reliability and richness. We extract emotion labels and provide abstractive summarization of the events causing emotions. The final dataset comprises over 700,000 tweets with corresponding emotion-cause pairs spanning 48 emotion classes, validated by human evaluators. The novelty of our dataset stems from its broad spectrum of emotion classes and the abstractive emotion cause that facilitates the development of an emotion-cause knowledge graph for nuanced reasoning. Our dataset will enable the design of emotion-aware systems that account for the diverse emotional responses of different people for the same event.
* Accepted to Findings of EMNLP 2023
Example-Based Framework for Perceptually Guided Audio Texture Generation
Aug 23, 2023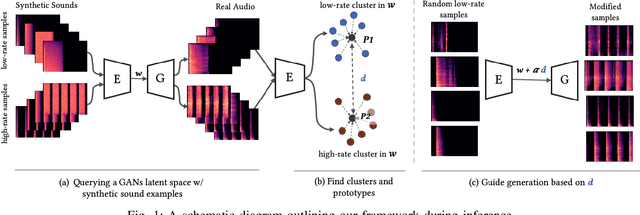

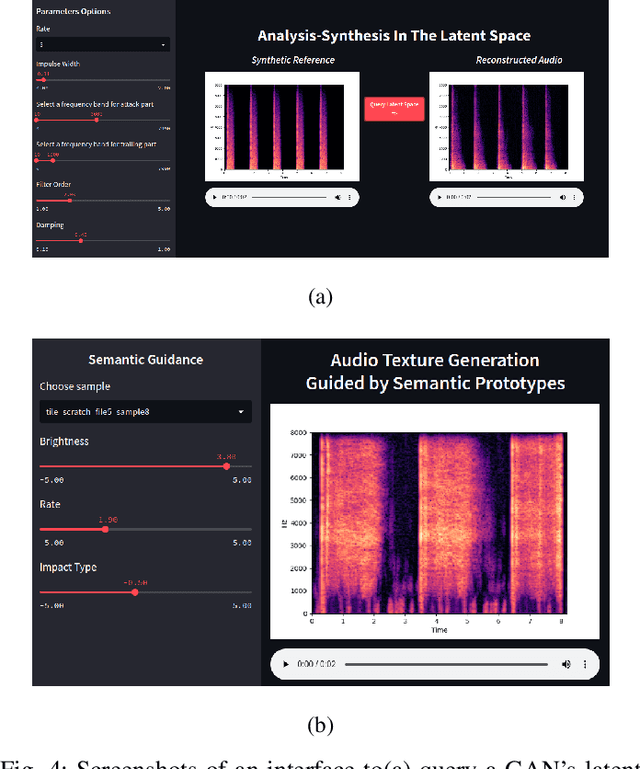
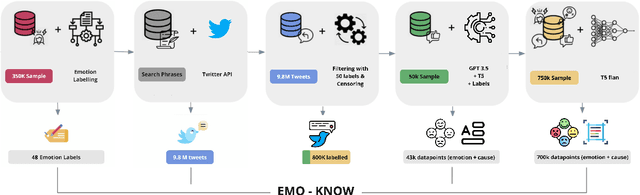
Generative models for synthesizing audio textures explicitly encode controllability by conditioning the model with labelled data. While datasets for audio textures can be easily recorded in-the-wild, semantically labeling them is expensive, time-consuming, and prone to errors due to human annotator subjectivity. Thus, to control generation, there is a need to automatically infer user-defined perceptual factors of variation in the latent space of a generative model while modelling unlabeled textures. In this paper, we propose an example-based framework to determine vectors to guide texture generation based on user-defined semantic attributes. By synthesizing a few synthetic examples to indicate the presence or absence of a semantic attribute, we can infer the guidance vectors in the latent space of a generative model to control that attribute during generation. Our results show that our method is capable of finding perceptually relevant and deterministic guidance vectors for controllable generation for both discrete as well as continuous textures. Furthermore, we demonstrate the application of this method to other tasks such as selective semantic attribute transfer.
VR.net: A Real-world Dataset for Virtual Reality Motion Sickness Research
Jun 06, 2023Researchers have used machine learning approaches to identify motion sickness in VR experience. These approaches demand an accurately-labeled, real-world, and diverse dataset for high accuracy and generalizability. As a starting point to address this need, we introduce `VR.net', a dataset offering approximately 12-hour gameplay videos from ten real-world games in 10 diverse genres. For each video frame, a rich set of motion sickness-related labels, such as camera/object movement, depth field, and motion flow, are accurately assigned. Building such a dataset is challenging since manual labeling would require an infeasible amount of time. Instead, we utilize a tool to automatically and precisely extract ground truth data from 3D engines' rendering pipelines without accessing VR games' source code. We illustrate the utility of VR.net through several applications, such as risk factor detection and sickness level prediction. We continuously expand VR.net and envision its next version offering 10X more data than the current form. We believe that the scale, accuracy, and diversity of VR.net can offer unparalleled opportunities for VR motion sickness research and beyond.
Towards Controllable Audio Texture Morphing
Apr 23, 2023In this paper, we propose a data-driven approach to train a Generative Adversarial Network (GAN) conditioned on "soft-labels" distilled from the penultimate layer of an audio classifier trained on a target set of audio texture classes. We demonstrate that interpolation between such conditions or control vectors provides smooth morphing between the generated audio textures, and shows similar or better audio texture morphing capability compared to the state-of-the-art methods. The proposed approach results in a well-organized latent space that generates novel audio outputs while remaining consistent with the semantics of the conditioning parameters. This is a step towards a general data-driven approach to designing generative audio models with customized controls capable of traversing out-of-distribution regions for novel sound synthesis.
Parameter Sensitivity of Deep-Feature based Evaluation Metrics for Audio Textures
Aug 23, 2022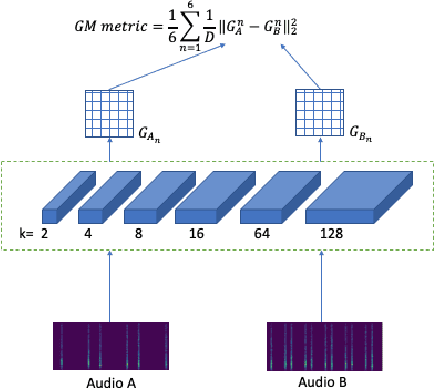
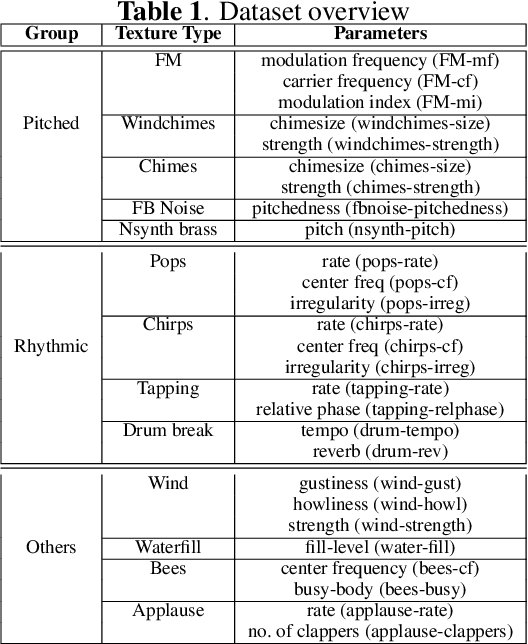
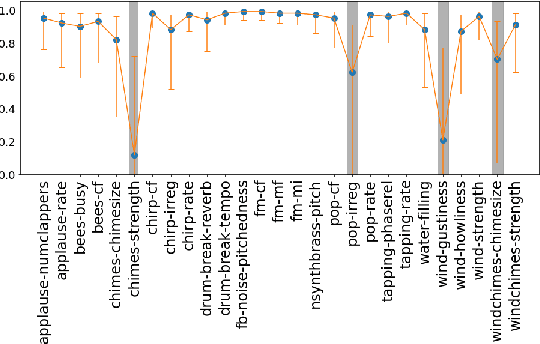
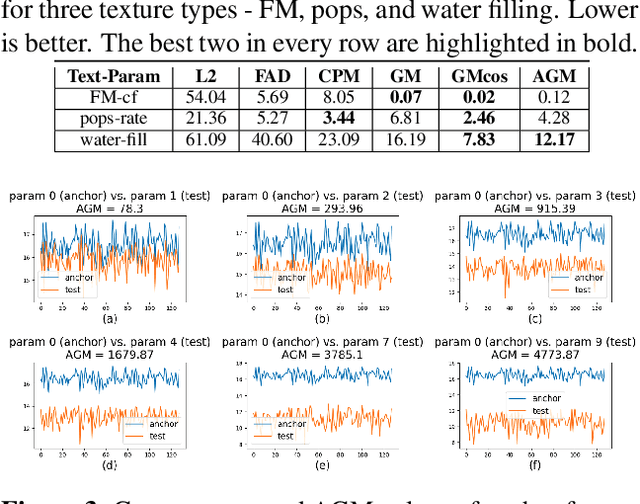
Standard evaluation metrics such as the Inception score and Fr\'echet Audio Distance provide a general audio quality distance metric between the synthesized audio and reference clean audio. However, the sensitivity of these metrics to variations in the statistical parameters that define an audio texture is not well studied. In this work, we provide a systematic study of the sensitivity of some of the existing audio quality evaluation metrics to parameter variations in audio textures. Furthermore, we also study three more potentially parameter-sensitive metrics for audio texture synthesis, (a) a Gram matrix based distance, (b) an Accumulated Gram metric using a summarized version of the Gram matrices, and (c) a cochlear-model based statistical features metric. These metrics use deep features that summarize the statistics of any given audio texture, thus being inherently sensitive to variations in the statistical parameters that define an audio texture. We study and evaluate the sensitivity of existing standard metrics as well as Gram matrix and cochlear-model based metrics to control-parameter variations in audio textures across a wide range of texture and parameter types, and validate with subjective evaluation. We find that each of the metrics is sensitive to different sets of texture-parameter types. This is the first step towards investigating objective metrics for assessing parameter sensitivity in audio textures.
PoLyScribers: Joint Training of Vocal Extractor and Lyrics Transcriber for Polyphonic Music
Jul 15, 2022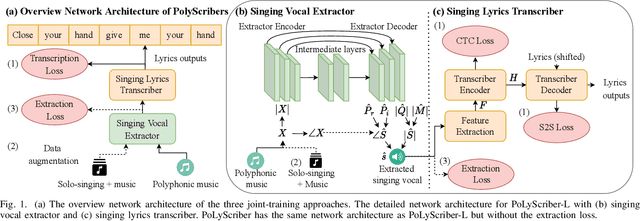
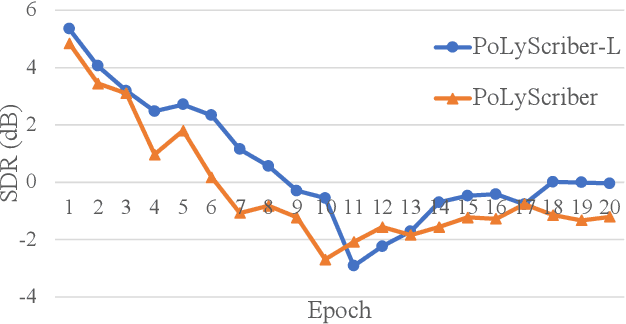
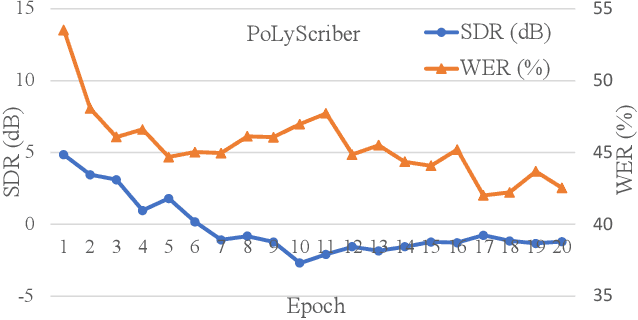
Lyrics transcription of polyphonic music is challenging as the background music affects lyrics intelligibility. Typically, lyrics transcription can be performed by a two step pipeline, i.e. singing vocal extraction frontend, followed by a lyrics transcriber decoder backend, where the frontend and backend are trained separately. Such a two step pipeline suffers from both imperfect vocal extraction and mismatch between frontend and backend. In this work, we propose novel end-to-end joint-training framework, that we call PoLyScribers, to jointly optimize the vocal extractor front-end and lyrics transcriber backend for lyrics transcription in polyphonic music. The experimental results show that our proposed joint-training model achieves substantial improvements over the existing approaches on publicly available test datasets.
Sound Model Factory: An Integrated System Architecture for Generative Audio Modelling
Jun 27, 2022We introduce a new system for data-driven audio sound model design built around two different neural network architectures, a Generative Adversarial Network(GAN) and a Recurrent Neural Network (RNN), that takes advantage of the unique characteristics of each to achieve the system objectives that neither is capable of addressing alone. The objective of the system is to generate interactively controllable sound models given (a) a range of sounds the model should be able to synthesize, and (b) a specification of the parametric controls for navigating that space of sounds. The range of sounds is defined by a dataset provided by the designer, while the means of navigation is defined by a combination of data labels and the selection of a sub-manifold from the latent space learned by the GAN. Our proposed system takes advantage of the rich latent space of a GAN that consists of sounds that fill out the spaces ''between" real data-like sounds. This augmented data from the GAN is then used to train an RNN for its ability to respond immediately and continuously to parameter changes and to generate audio over unlimited periods of time. Furthermore, we develop a self-organizing map technique for ``smoothing" the latent space of GAN that results in perceptually smooth interpolation between audio timbres. We validate this process through user studies. The system contributes advances to the state of the art for generative sound model design that include system configuration and components for improving interpolation and the expansion of audio modeling capabilities beyond musical pitch and percussive instrument sounds into the more complex space of audio textures.
Genre-conditioned Acoustic Models for Automatic Lyrics Transcription of Polyphonic Music
Apr 07, 2022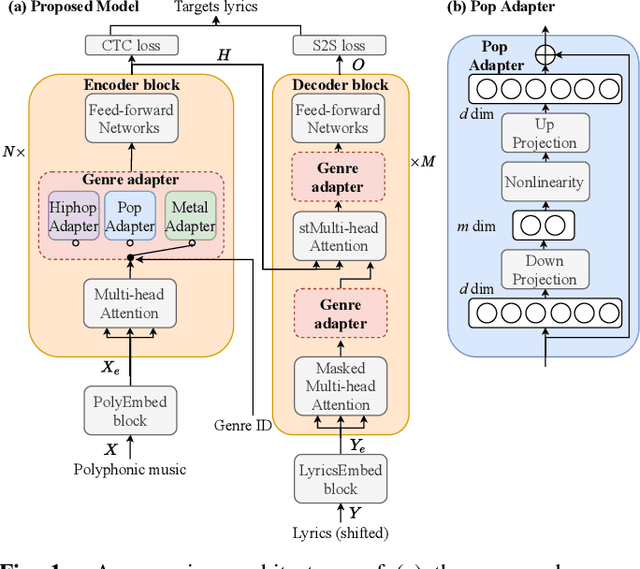
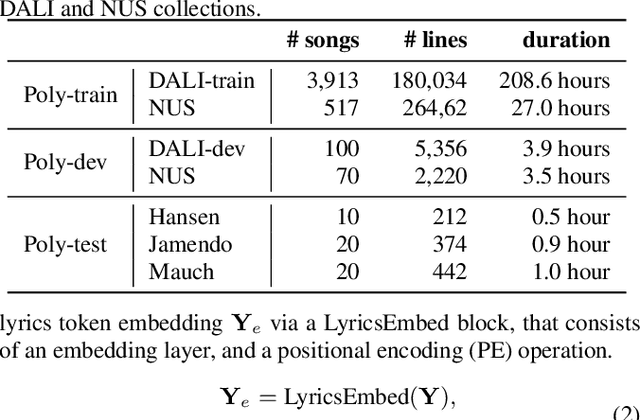
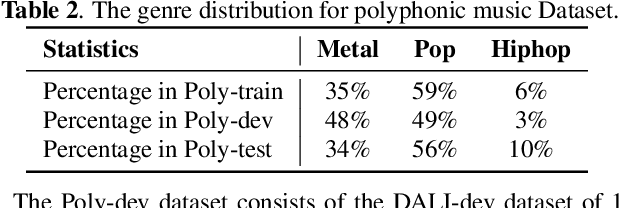
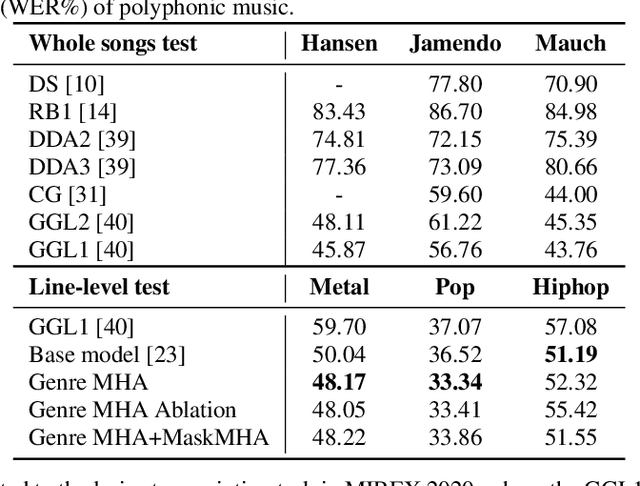
Lyrics transcription of polyphonic music is challenging not only because the singing vocals are corrupted by the background music, but also because the background music and the singing style vary across music genres, such as pop, metal, and hip hop, which affects lyrics intelligibility of the song in different ways. In this work, we propose to transcribe the lyrics of polyphonic music using a novel genre-conditioned network. The proposed network adopts pre-trained model parameters, and incorporates the genre adapters between layers to capture different genre peculiarities for lyrics-genre pairs, thereby only requiring lightweight genre-specific parameters for training. Our experiments show that the proposed genre-conditioned network outperforms the existing lyrics transcription systems.