 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMusic-robust Automatic Lyrics Transcription of Polyphonic Music
Paper and Code
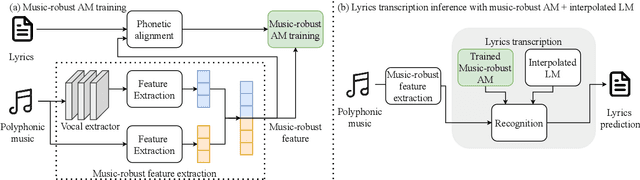
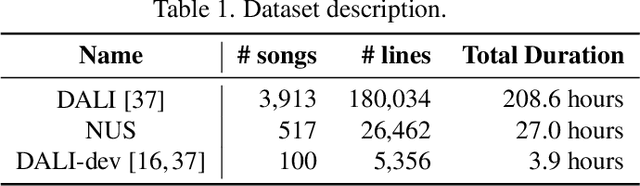
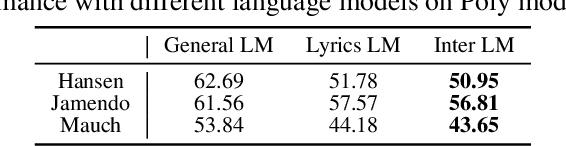
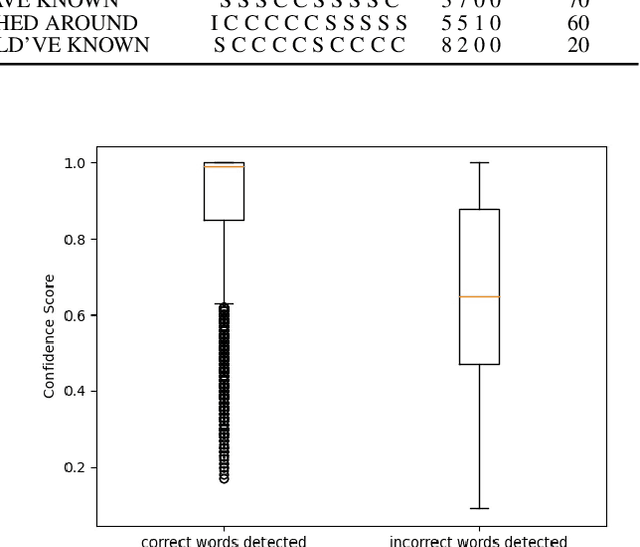
Lyrics transcription of polyphonic music is challenging because singing vocals are corrupted by the background music. To improve the robustness of lyrics transcription to the background music, we propose a strategy of combining the features that emphasize the singing vocals, i.e. music-removed features that represent singing vocal extracted features, and the features that capture the singing vocals as well as the background music, i.e. music-present features. We show that these two sets of features complement each other, and their combination performs better than when they are used alone, thus improving the robustness of the acoustic model to the background music. Furthermore, language model interpolation between a general-purpose language model and an in-domain lyrics-specific language model provides further improvement in transcription results. Our experiments show that our proposed strategy outperforms the existing lyrics transcription systems for polyphonic music. Moreover, we find that our proposed music-robust features specially improve the lyrics transcription performance in metal genre of songs, where the background music is loud and dominant.