 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeA Statistics-Driven Differentiable Approach for Sound Texture Synthesis and Analysis
Jun 04, 2025In this work, we introduce TexStat, a novel loss function specifically designed for the analysis and synthesis of texture sounds characterized by stochastic structure and perceptual stationarity. Drawing inspiration from the statistical and perceptual framework of McDermott and Simoncelli, TexStat identifies similarities between signals belonging to the same texture category without relying on temporal structure. We also propose using TexStat as a validation metric alongside Frechet Audio Distances (FAD) to evaluate texture sound synthesis models. In addition to TexStat, we present TexEnv, an efficient, lightweight and differentiable texture sound synthesizer that generates audio by imposing amplitude envelopes on filtered noise. We further integrate these components into TexDSP, a DDSP-inspired generative model tailored for texture sounds. Through extensive experiments across various texture sound types, we demonstrate that TexStat is perceptually meaningful, time-invariant, and robust to noise, features that make it effective both as a loss function for generative tasks and as a validation metric. All tools and code are provided as open-source contributions and our PyTorch implementations are efficient, differentiable, and highly configurable, enabling its use in both generative tasks and as a perceptually grounded evaluation metric.
Example-Based Framework for Perceptually Guided Audio Texture Generation
Aug 23, 2023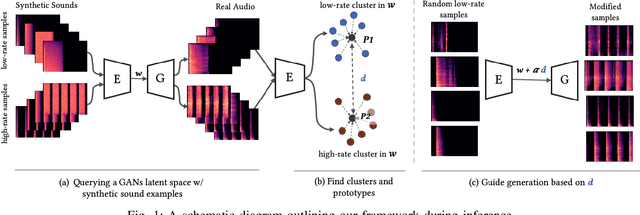

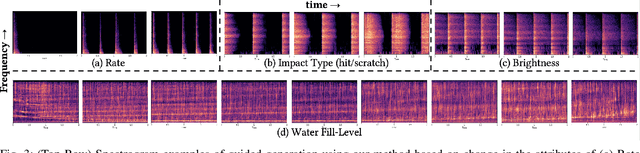
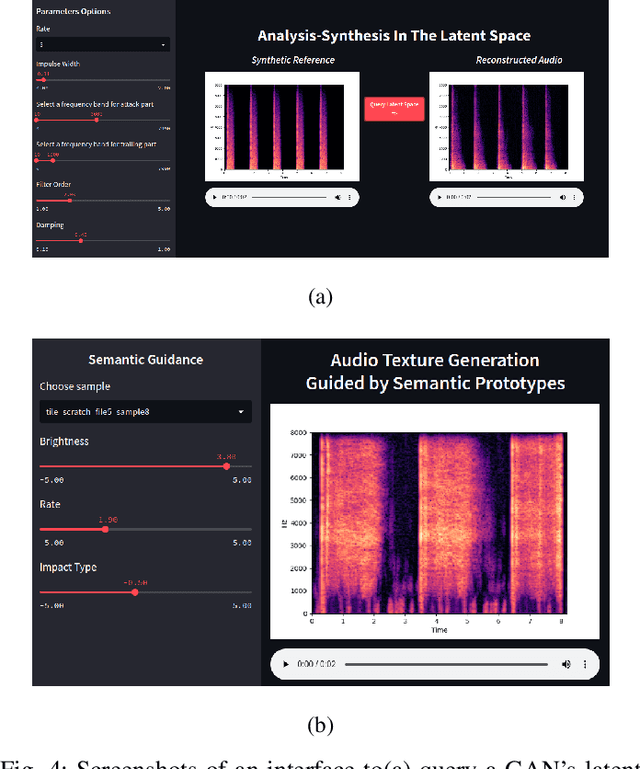
Generative models for synthesizing audio textures explicitly encode controllability by conditioning the model with labelled data. While datasets for audio textures can be easily recorded in-the-wild, semantically labeling them is expensive, time-consuming, and prone to errors due to human annotator subjectivity. Thus, to control generation, there is a need to automatically infer user-defined perceptual factors of variation in the latent space of a generative model while modelling unlabeled textures. In this paper, we propose an example-based framework to determine vectors to guide texture generation based on user-defined semantic attributes. By synthesizing a few synthetic examples to indicate the presence or absence of a semantic attribute, we can infer the guidance vectors in the latent space of a generative model to control that attribute during generation. Our results show that our method is capable of finding perceptually relevant and deterministic guidance vectors for controllable generation for both discrete as well as continuous textures. Furthermore, we demonstrate the application of this method to other tasks such as selective semantic attribute transfer.
Towards Controllable Audio Texture Morphing
Apr 23, 2023In this paper, we propose a data-driven approach to train a Generative Adversarial Network (GAN) conditioned on "soft-labels" distilled from the penultimate layer of an audio classifier trained on a target set of audio texture classes. We demonstrate that interpolation between such conditions or control vectors provides smooth morphing between the generated audio textures, and shows similar or better audio texture morphing capability compared to the state-of-the-art methods. The proposed approach results in a well-organized latent space that generates novel audio outputs while remaining consistent with the semantics of the conditioning parameters. This is a step towards a general data-driven approach to designing generative audio models with customized controls capable of traversing out-of-distribution regions for novel sound synthesis.
Parameter Sensitivity of Deep-Feature based Evaluation Metrics for Audio Textures
Aug 23, 2022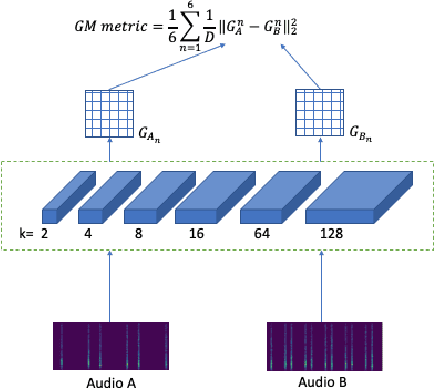
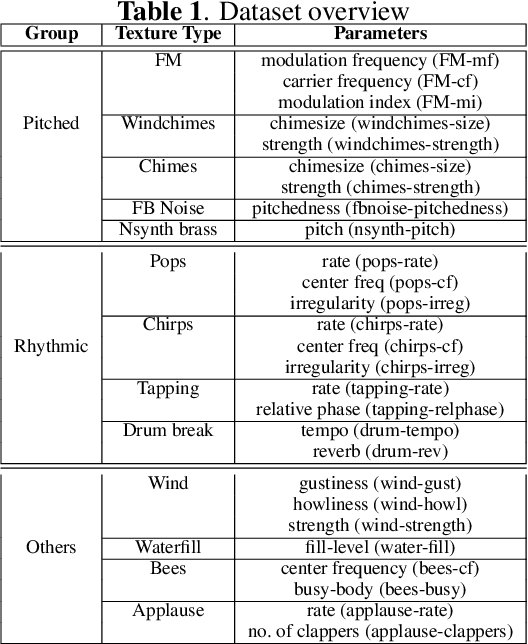
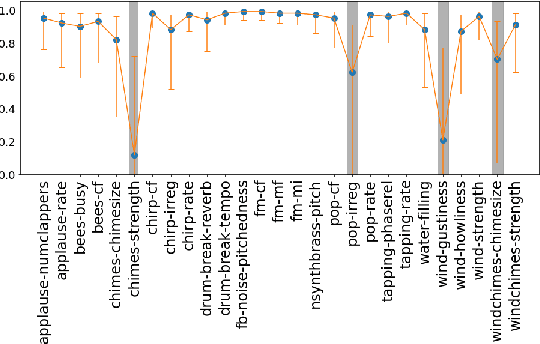
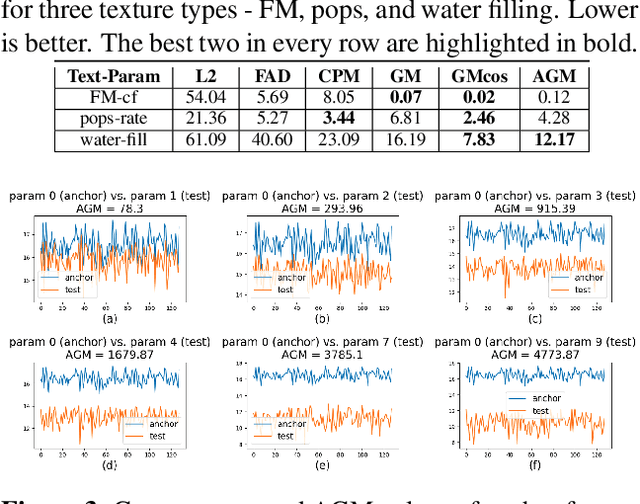
Standard evaluation metrics such as the Inception score and Fr\'echet Audio Distance provide a general audio quality distance metric between the synthesized audio and reference clean audio. However, the sensitivity of these metrics to variations in the statistical parameters that define an audio texture is not well studied. In this work, we provide a systematic study of the sensitivity of some of the existing audio quality evaluation metrics to parameter variations in audio textures. Furthermore, we also study three more potentially parameter-sensitive metrics for audio texture synthesis, (a) a Gram matrix based distance, (b) an Accumulated Gram metric using a summarized version of the Gram matrices, and (c) a cochlear-model based statistical features metric. These metrics use deep features that summarize the statistics of any given audio texture, thus being inherently sensitive to variations in the statistical parameters that define an audio texture. We study and evaluate the sensitivity of existing standard metrics as well as Gram matrix and cochlear-model based metrics to control-parameter variations in audio textures across a wide range of texture and parameter types, and validate with subjective evaluation. We find that each of the metrics is sensitive to different sets of texture-parameter types. This is the first step towards investigating objective metrics for assessing parameter sensitivity in audio textures.
Sound Model Factory: An Integrated System Architecture for Generative Audio Modelling
Jun 27, 2022We introduce a new system for data-driven audio sound model design built around two different neural network architectures, a Generative Adversarial Network(GAN) and a Recurrent Neural Network (RNN), that takes advantage of the unique characteristics of each to achieve the system objectives that neither is capable of addressing alone. The objective of the system is to generate interactively controllable sound models given (a) a range of sounds the model should be able to synthesize, and (b) a specification of the parametric controls for navigating that space of sounds. The range of sounds is defined by a dataset provided by the designer, while the means of navigation is defined by a combination of data labels and the selection of a sub-manifold from the latent space learned by the GAN. Our proposed system takes advantage of the rich latent space of a GAN that consists of sounds that fill out the spaces ''between" real data-like sounds. This augmented data from the GAN is then used to train an RNN for its ability to respond immediately and continuously to parameter changes and to generate audio over unlimited periods of time. Furthermore, we develop a self-organizing map technique for ``smoothing" the latent space of GAN that results in perceptually smooth interpolation between audio timbres. We validate this process through user studies. The system contributes advances to the state of the art for generative sound model design that include system configuration and components for improving interpolation and the expansion of audio modeling capabilities beyond musical pitch and percussive instrument sounds into the more complex space of audio textures.
Signal Representations for Synthesizing Audio Textures with Generative Adversarial Networks
Mar 12, 2021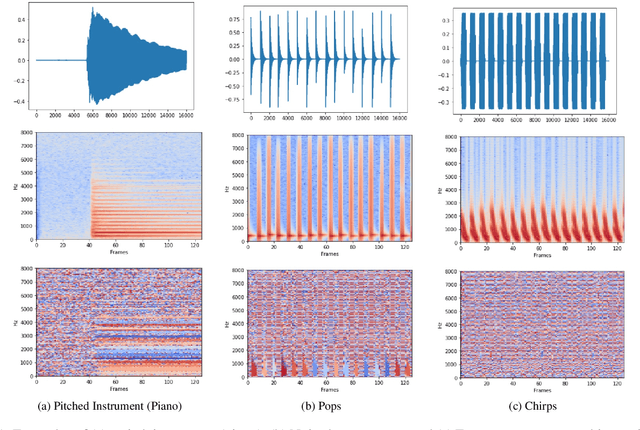


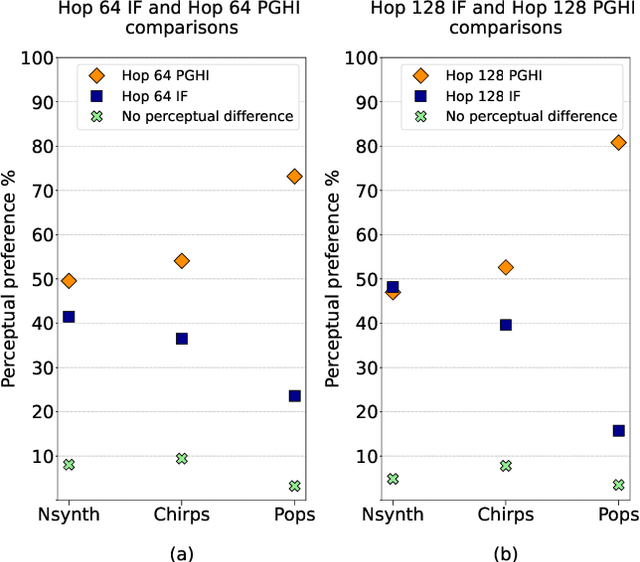
Generative Adversarial Networks (GANs) currently achieve the state-of-the-art sound synthesis quality for pitched musical instruments using a 2-channel spectrogram representation consisting of log magnitude and instantaneous frequency (the "IFSpectrogram"). Many other synthesis systems use representations derived from the magnitude spectra, and then depend on a backend component to invert the output magnitude spectrograms that generally result in audible artefacts associated with the inversion process. However, for signals that have closely-spaced frequency components such as non-pitched and other noisy sounds, training the GAN on the 2-channel IFSpectrogram representation offers no advantage over the magnitude spectra based representations. In this paper, we propose that training GANs on single-channel magnitude spectra, and using the Phase Gradient Heap Integration (PGHI) inversion algorithm is a better comprehensive approach for audio synthesis modeling of diverse signals that include pitched, non-pitched, and dynamically complex sounds. We show that this method produces higher-quality output for wideband and noisy sounds, such as pops and chirps, compared to using the IFSpectrogram. Furthermore, the sound quality for pitched sounds is comparable to using the IFSpectrogram, even while using a simpler representation with half the memory requirements.
Mechanisms of Artistic Creativity in Deep Learning Neural Networks
Jun 30, 2019



The generative capabilities of deep learning neural networks (DNNs) have been attracting increasing attention for both the remarkable artifacts they produce, but also because of the vast conceptual difference between how they are programmed and what they do. DNNs are 'black boxes' where high-level behavior is not explicitly programmed, but emerges from the complex interactions of thousands or millions of simple computational elements. Their behavior is often described in anthropomorphic terms that can be misleading, seem magical, or stoke fears of an imminent singularity in which machines become 'more' than human. In this paper, we examine 5 distinct behavioral characteristics associated with creativity, and provide an example of a mechanisms from generative deep learning architectures that give rise to each these characteristics. All 5 emerge from machinery built for purposes other than the creative characteristics they exhibit, mostly classification. These mechanisms of creative generative capabilities thus demonstrate a deep kinship to computational perceptual processes. By understanding how these different behaviors arise, we hope to on one hand take the magic out of anthropomorphic descriptions, but on the other, to build a deeper appreciation of machinic forms of creativity on their own terms that will allow us to nurture their further development.
Conditioning a Recurrent Neural Network to synthesize musical instrument transients
Mar 26, 2019
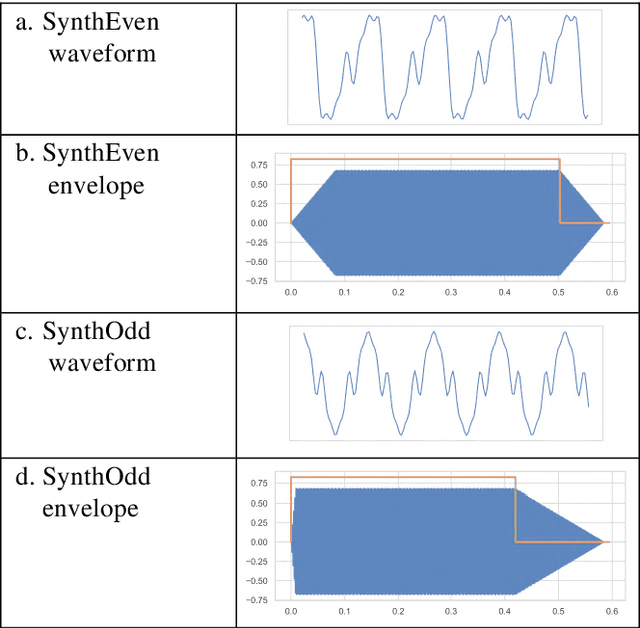
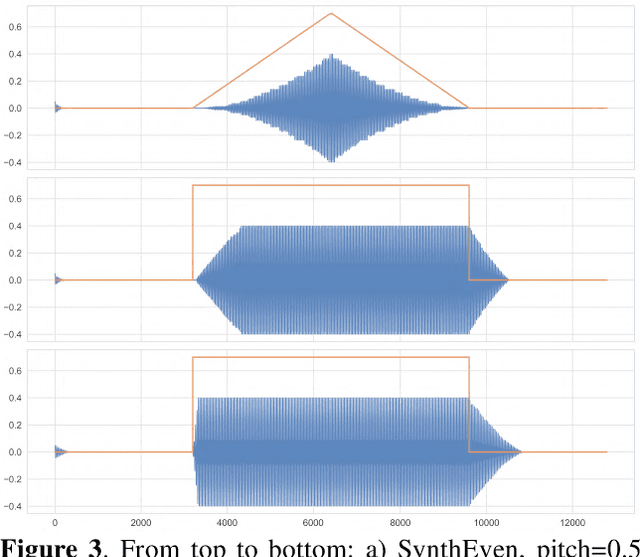
A recurrent Neural Network (RNN) is trained to predict sound samples based on audio input augmented by control parameter information for pitch, volume, and instrument identification. During the generative phase following training, audio input is taken from the output of the previous time step, and the parameters are externally controlled allowing the network to be played as a musical instrument. Building on an architecture developed in previous work, we focus on the learning and synthesis of transients - the temporal response of the network during the short time (tens of milliseconds) following the onset and offset of a control signal. We find that the network learns the particular transient characteristics of two different synthetic instruments, and furthermore shows some ability to interpolate between the characteristics of the instruments used in training in response to novel parameter settings. We also study the behaviour of the units in hidden layers of the RNN using various visualisation techniques and find a variety of volume-specific response characteristics.
Real-valued parametric conditioning of an RNN for interactive sound synthesis
May 30, 2018
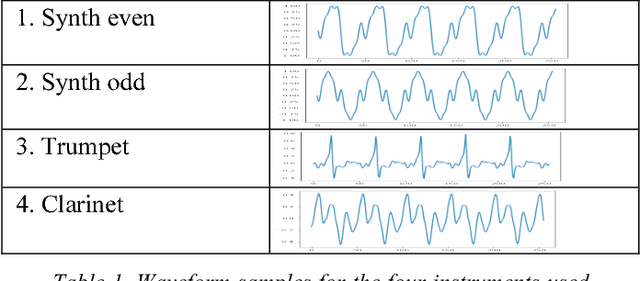
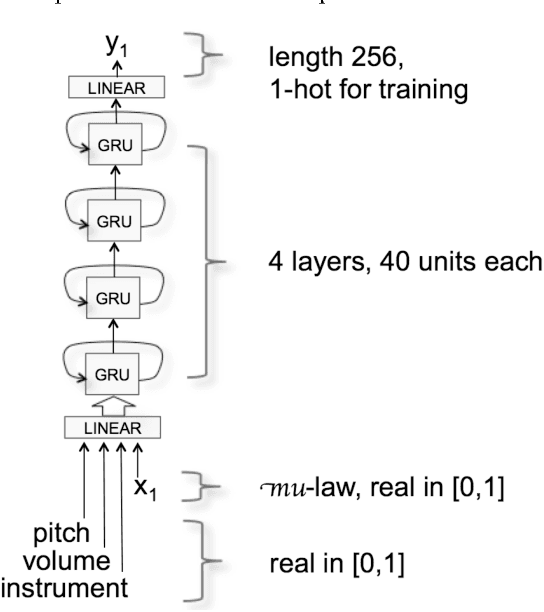

A Recurrent Neural Network (RNN) for audio synthesis is trained by augmenting the audio input with information about signal characteristics such as pitch, amplitude, and instrument. The result after training is an audio synthesizer that is played like a musical instrument with the desired musical characteristics provided as continuous parametric control. The focus of this paper is on conditioning data-driven synthesis models with real-valued parameters, and in particular, on the ability of the system a) to generalize and b) to be responsive to parameter values and sequences not seen during training.