 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTowards Controllable Audio Texture Morphing
Apr 23, 2023In this paper, we propose a data-driven approach to train a Generative Adversarial Network (GAN) conditioned on "soft-labels" distilled from the penultimate layer of an audio classifier trained on a target set of audio texture classes. We demonstrate that interpolation between such conditions or control vectors provides smooth morphing between the generated audio textures, and shows similar or better audio texture morphing capability compared to the state-of-the-art methods. The proposed approach results in a well-organized latent space that generates novel audio outputs while remaining consistent with the semantics of the conditioning parameters. This is a step towards a general data-driven approach to designing generative audio models with customized controls capable of traversing out-of-distribution regions for novel sound synthesis.
Parameter Sensitivity of Deep-Feature based Evaluation Metrics for Audio Textures
Aug 23, 2022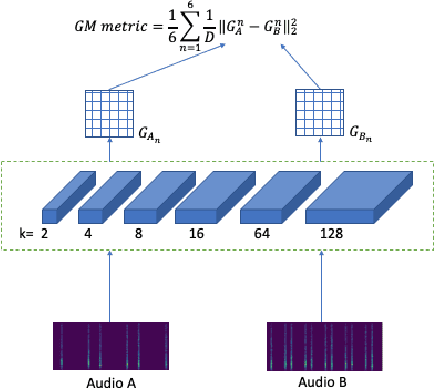
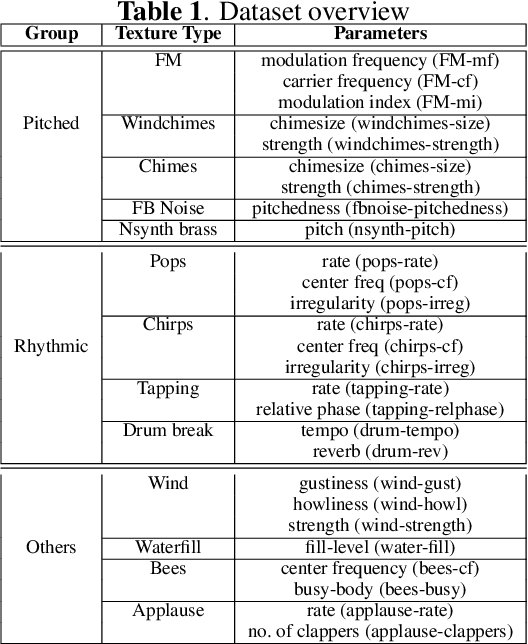
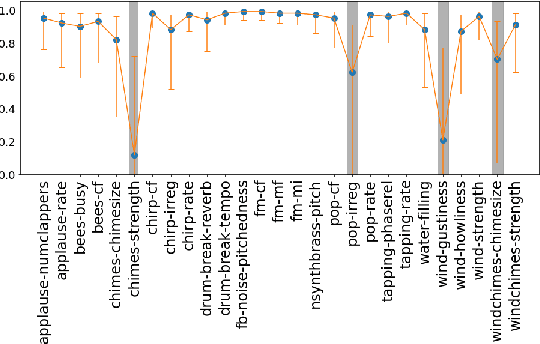
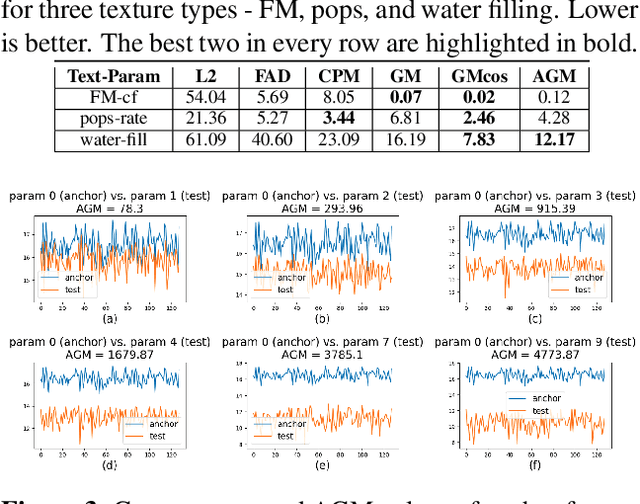
Standard evaluation metrics such as the Inception score and Fr\'echet Audio Distance provide a general audio quality distance metric between the synthesized audio and reference clean audio. However, the sensitivity of these metrics to variations in the statistical parameters that define an audio texture is not well studied. In this work, we provide a systematic study of the sensitivity of some of the existing audio quality evaluation metrics to parameter variations in audio textures. Furthermore, we also study three more potentially parameter-sensitive metrics for audio texture synthesis, (a) a Gram matrix based distance, (b) an Accumulated Gram metric using a summarized version of the Gram matrices, and (c) a cochlear-model based statistical features metric. These metrics use deep features that summarize the statistics of any given audio texture, thus being inherently sensitive to variations in the statistical parameters that define an audio texture. We study and evaluate the sensitivity of existing standard metrics as well as Gram matrix and cochlear-model based metrics to control-parameter variations in audio textures across a wide range of texture and parameter types, and validate with subjective evaluation. We find that each of the metrics is sensitive to different sets of texture-parameter types. This is the first step towards investigating objective metrics for assessing parameter sensitivity in audio textures.