 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSensitivity Analysis of Generative Spatial Audio Metrics: A Study on Responsiveness, Smoothness, and Symmetry
Jun 10, 2026Evaluating generative spatial audio for First-Order Ambisonics (FOA) remains challenging due to a limited understanding of how metrics respond to changes in spatial parameters such as azimuth and elevation. We propose a framework to analyze metric sensitivity along continuous spatial trajectories, drawing on principles of sensitivity analysis in parametric sound synthesis. Using controlled FOA scenes with increasing scene complexity, we define three desiderata for metric behavior: Responsiveness, Smoothness, and Symmetry. We assess standard distribution-based and sample-based metrics, including Fréchet Audio Distance (FAD), intensity vectors, and acoustic maps. Our findings show that FAD using localization-specific embeddings and acoustic maps yield high Responsiveness and robust Smoothness and Symmetry across conditions, while intensity vectors degrade with increasing scene complexity. This is the first step towards investigating the sensitivity of metrics for generative spatial audio.
MorphFader: Enabling Fine-grained Controllable Morphing with Text-to-Audio Models
Aug 14, 2024Sound morphing is the process of gradually and smoothly transforming one sound into another to generate novel and perceptually hybrid sounds that simultaneously resemble both. Recently, diffusion-based text-to-audio models have produced high-quality sounds using text prompts. However, granularly controlling the semantics of the sound, which is necessary for morphing, can be challenging using text. In this paper, we propose \textit{MorphFader}, a controllable method for morphing sounds generated by disparate prompts using text-to-audio models. By intercepting and interpolating the components of the cross-attention layers within the diffusion process, we can create smooth morphs between sounds generated by different text prompts. Using both objective metrics and perceptual listening tests, we demonstrate the ability of our method to granularly control the semantics in the sound and generate smooth morphs.
Example-Based Framework for Perceptually Guided Audio Texture Generation
Aug 23, 2023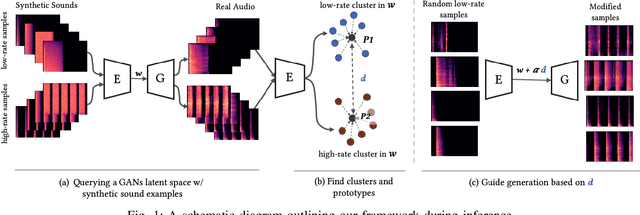

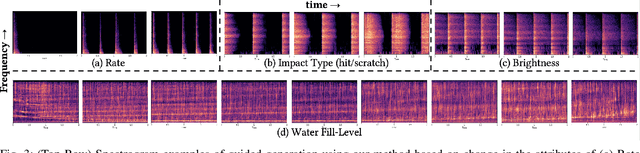
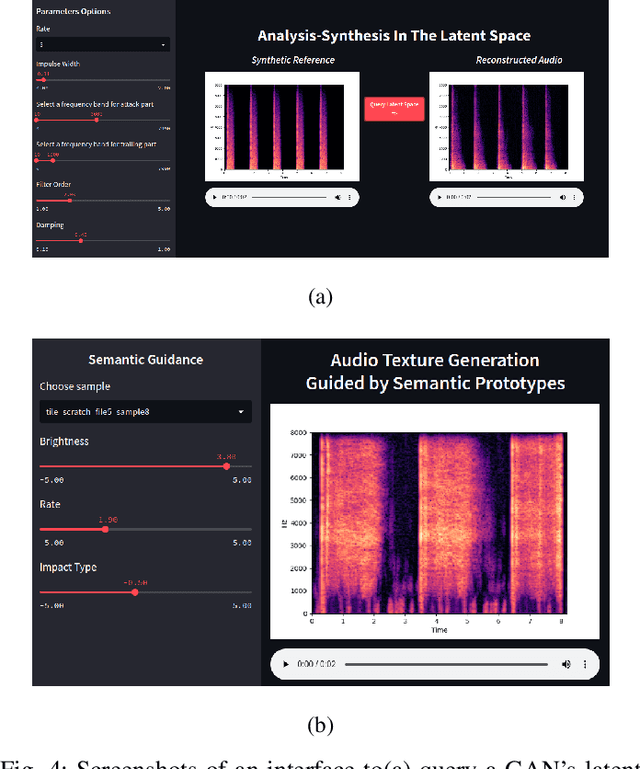
Generative models for synthesizing audio textures explicitly encode controllability by conditioning the model with labelled data. While datasets for audio textures can be easily recorded in-the-wild, semantically labeling them is expensive, time-consuming, and prone to errors due to human annotator subjectivity. Thus, to control generation, there is a need to automatically infer user-defined perceptual factors of variation in the latent space of a generative model while modelling unlabeled textures. In this paper, we propose an example-based framework to determine vectors to guide texture generation based on user-defined semantic attributes. By synthesizing a few synthetic examples to indicate the presence or absence of a semantic attribute, we can infer the guidance vectors in the latent space of a generative model to control that attribute during generation. Our results show that our method is capable of finding perceptually relevant and deterministic guidance vectors for controllable generation for both discrete as well as continuous textures. Furthermore, we demonstrate the application of this method to other tasks such as selective semantic attribute transfer.
Towards Controllable Audio Texture Morphing
Apr 23, 2023In this paper, we propose a data-driven approach to train a Generative Adversarial Network (GAN) conditioned on "soft-labels" distilled from the penultimate layer of an audio classifier trained on a target set of audio texture classes. We demonstrate that interpolation between such conditions or control vectors provides smooth morphing between the generated audio textures, and shows similar or better audio texture morphing capability compared to the state-of-the-art methods. The proposed approach results in a well-organized latent space that generates novel audio outputs while remaining consistent with the semantics of the conditioning parameters. This is a step towards a general data-driven approach to designing generative audio models with customized controls capable of traversing out-of-distribution regions for novel sound synthesis.
Parameter Sensitivity of Deep-Feature based Evaluation Metrics for Audio Textures
Aug 23, 2022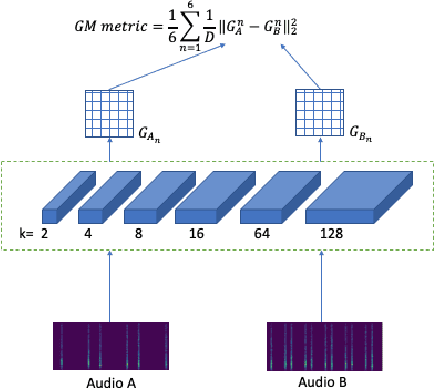
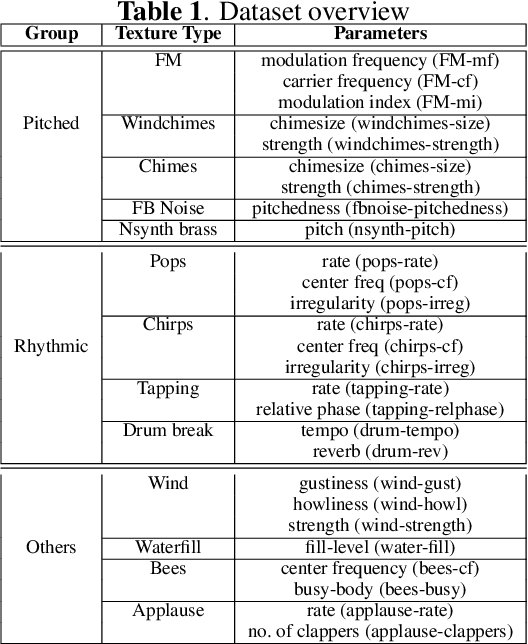
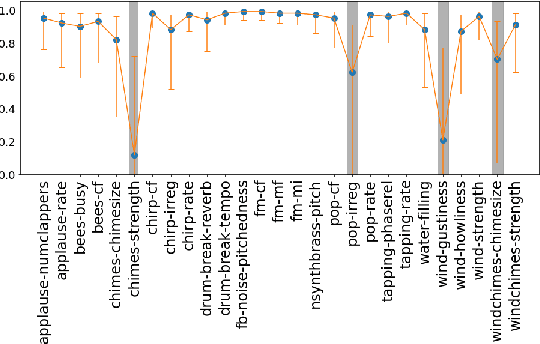
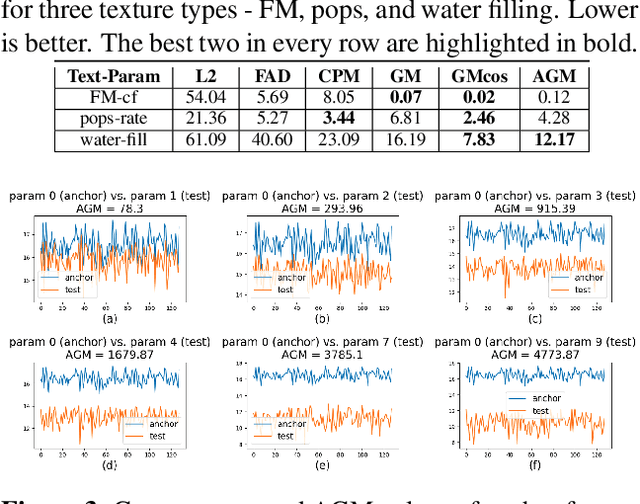
Standard evaluation metrics such as the Inception score and Fr\'echet Audio Distance provide a general audio quality distance metric between the synthesized audio and reference clean audio. However, the sensitivity of these metrics to variations in the statistical parameters that define an audio texture is not well studied. In this work, we provide a systematic study of the sensitivity of some of the existing audio quality evaluation metrics to parameter variations in audio textures. Furthermore, we also study three more potentially parameter-sensitive metrics for audio texture synthesis, (a) a Gram matrix based distance, (b) an Accumulated Gram metric using a summarized version of the Gram matrices, and (c) a cochlear-model based statistical features metric. These metrics use deep features that summarize the statistics of any given audio texture, thus being inherently sensitive to variations in the statistical parameters that define an audio texture. We study and evaluate the sensitivity of existing standard metrics as well as Gram matrix and cochlear-model based metrics to control-parameter variations in audio textures across a wide range of texture and parameter types, and validate with subjective evaluation. We find that each of the metrics is sensitive to different sets of texture-parameter types. This is the first step towards investigating objective metrics for assessing parameter sensitivity in audio textures.
Sound Model Factory: An Integrated System Architecture for Generative Audio Modelling
Jun 27, 2022We introduce a new system for data-driven audio sound model design built around two different neural network architectures, a Generative Adversarial Network(GAN) and a Recurrent Neural Network (RNN), that takes advantage of the unique characteristics of each to achieve the system objectives that neither is capable of addressing alone. The objective of the system is to generate interactively controllable sound models given (a) a range of sounds the model should be able to synthesize, and (b) a specification of the parametric controls for navigating that space of sounds. The range of sounds is defined by a dataset provided by the designer, while the means of navigation is defined by a combination of data labels and the selection of a sub-manifold from the latent space learned by the GAN. Our proposed system takes advantage of the rich latent space of a GAN that consists of sounds that fill out the spaces ''between" real data-like sounds. This augmented data from the GAN is then used to train an RNN for its ability to respond immediately and continuously to parameter changes and to generate audio over unlimited periods of time. Furthermore, we develop a self-organizing map technique for ``smoothing" the latent space of GAN that results in perceptually smooth interpolation between audio timbres. We validate this process through user studies. The system contributes advances to the state of the art for generative sound model design that include system configuration and components for improving interpolation and the expansion of audio modeling capabilities beyond musical pitch and percussive instrument sounds into the more complex space of audio textures.
Signal Representations for Synthesizing Audio Textures with Generative Adversarial Networks
Mar 12, 2021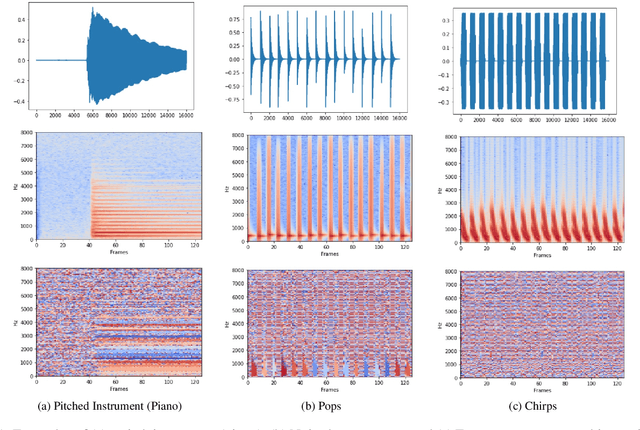


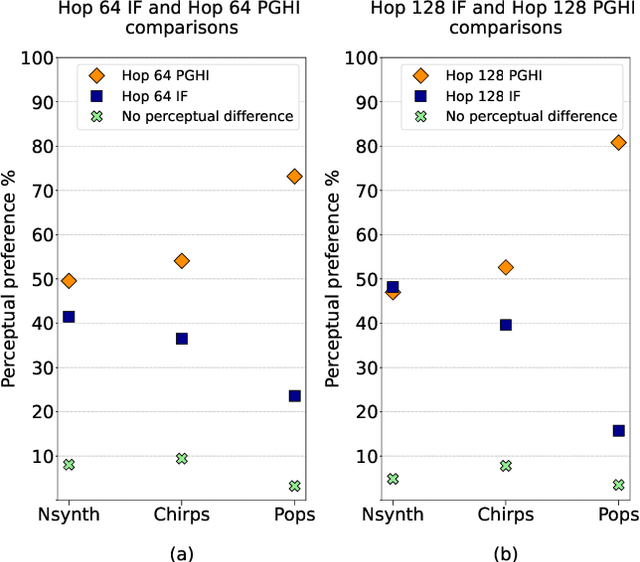
Generative Adversarial Networks (GANs) currently achieve the state-of-the-art sound synthesis quality for pitched musical instruments using a 2-channel spectrogram representation consisting of log magnitude and instantaneous frequency (the "IFSpectrogram"). Many other synthesis systems use representations derived from the magnitude spectra, and then depend on a backend component to invert the output magnitude spectrograms that generally result in audible artefacts associated with the inversion process. However, for signals that have closely-spaced frequency components such as non-pitched and other noisy sounds, training the GAN on the 2-channel IFSpectrogram representation offers no advantage over the magnitude spectra based representations. In this paper, we propose that training GANs on single-channel magnitude spectra, and using the Phase Gradient Heap Integration (PGHI) inversion algorithm is a better comprehensive approach for audio synthesis modeling of diverse signals that include pitched, non-pitched, and dynamically complex sounds. We show that this method produces higher-quality output for wideband and noisy sounds, such as pops and chirps, compared to using the IFSpectrogram. Furthermore, the sound quality for pitched sounds is comparable to using the IFSpectrogram, even while using a simpler representation with half the memory requirements.