 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePoLyScribers: Joint Training of Vocal Extractor and Lyrics Transcriber for Polyphonic Music
Paper and Code
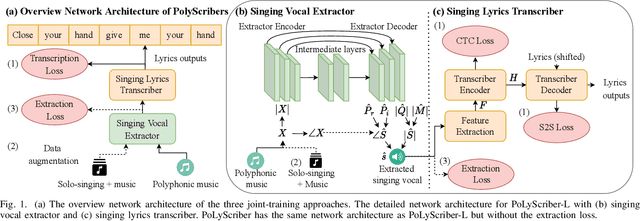
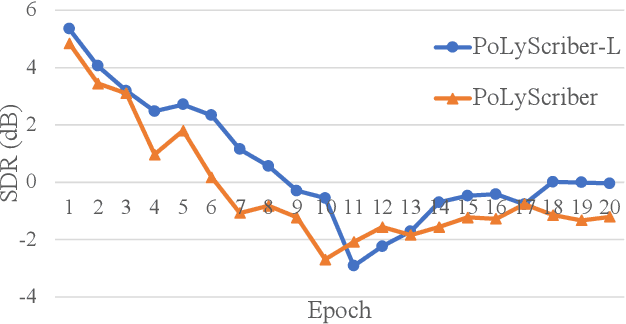
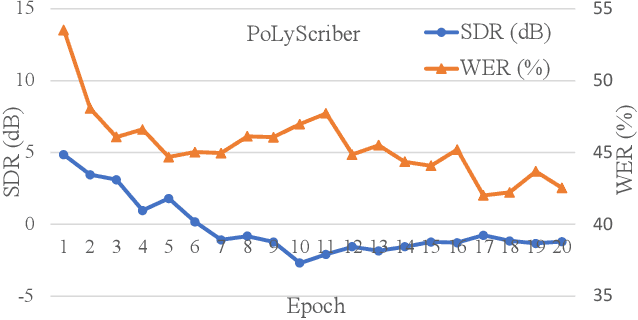
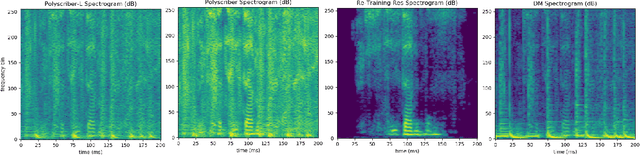
Lyrics transcription of polyphonic music is challenging as the background music affects lyrics intelligibility. Typically, lyrics transcription can be performed by a two step pipeline, i.e. singing vocal extraction frontend, followed by a lyrics transcriber decoder backend, where the frontend and backend are trained separately. Such a two step pipeline suffers from both imperfect vocal extraction and mismatch between frontend and backend. In this work, we propose novel end-to-end joint-training framework, that we call PoLyScribers, to jointly optimize the vocal extractor front-end and lyrics transcriber backend for lyrics transcription in polyphonic music. The experimental results show that our proposed joint-training model achieves substantial improvements over the existing approaches on publicly available test datasets.