 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeImproving the Domain Adaptation of Retrieval Augmented Generation (RAG) Models for Open Domain Question Answering
Oct 06, 2022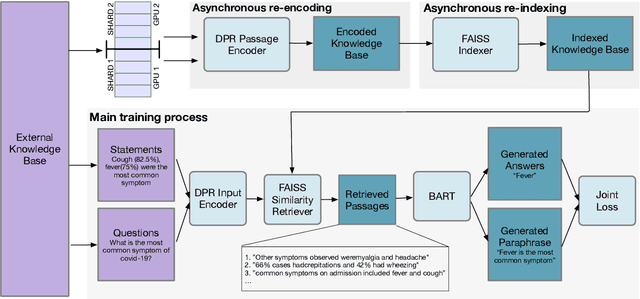
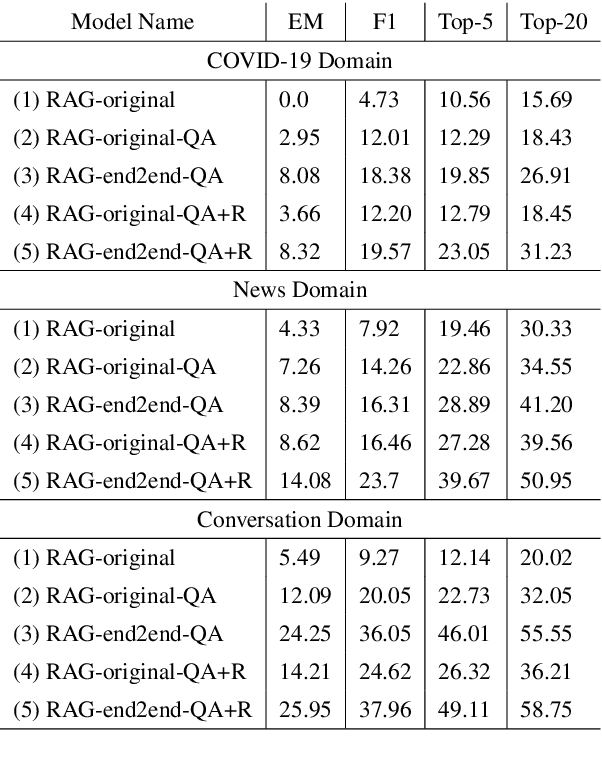
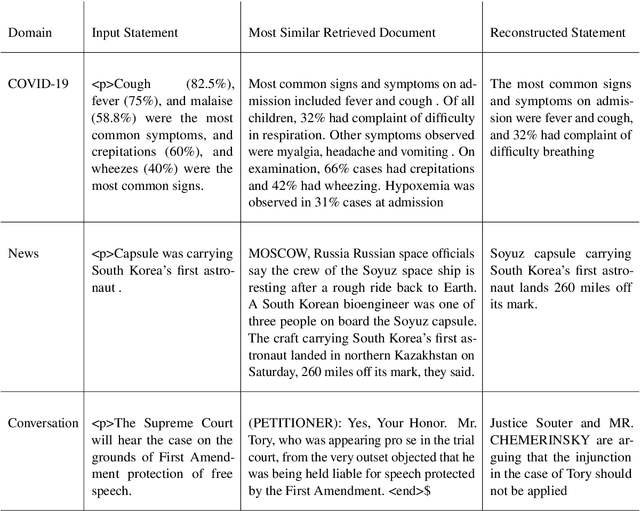
Retrieval Augment Generation (RAG) is a recent advancement in Open-Domain Question Answering (ODQA). RAG has only been trained and explored with a Wikipedia-based external knowledge base and is not optimized for use in other specialized domains such as healthcare and news. In this paper, we evaluate the impact of joint training of the retriever and generator components of RAG for the task of domain adaptation in ODQA. We propose \textit{RAG-end2end}, an extension to RAG, that can adapt to a domain-specific knowledge base by updating all components of the external knowledge base during training. In addition, we introduce an auxiliary training signal to inject more domain-specific knowledge. This auxiliary signal forces \textit{RAG-end2end} to reconstruct a given sentence by accessing the relevant information from the external knowledge base. Our novel contribution is unlike RAG, RAG-end2end does joint training of the retriever and generator for the end QA task and domain adaptation. We evaluate our approach with datasets from three domains: COVID-19, News, and Conversations, and achieve significant performance improvements compared to the original RAG model. Our work has been open-sourced through the Huggingface Transformers library, attesting to our work's credibility and technical consistency.
Fine-tune the Entire RAG Architecture for Question-Answering
Jun 22, 2021In this paper, we illustrate how to fine-tune the entire Retrieval Augment Generation (RAG) architecture in an end-to-end manner. We highlighted the main engineering challenges that needed to be addressed to achieve this objective. We also compare how end-to-end RAG architecture outperforms the original RAG architecture for the task of question answering. We have open-sourced our implementation in the HuggingFace Transformers library.
Jointly Fine-Tuning "BERT-like" Self Supervised Models to Improve Multimodal Speech Emotion Recognition
Aug 15, 2020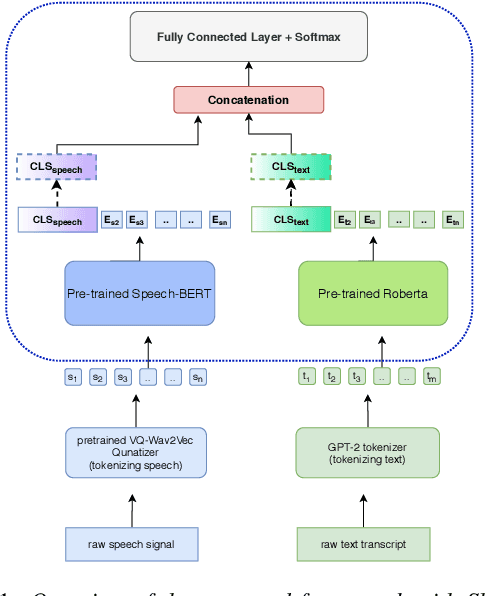
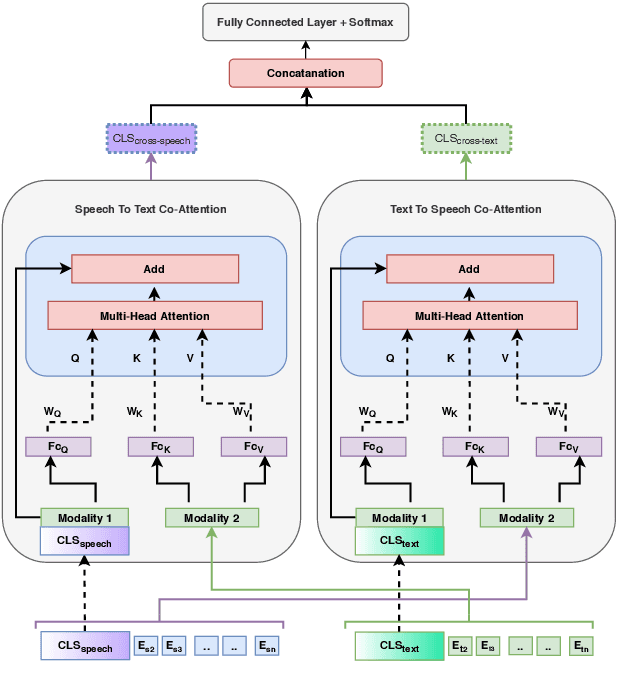
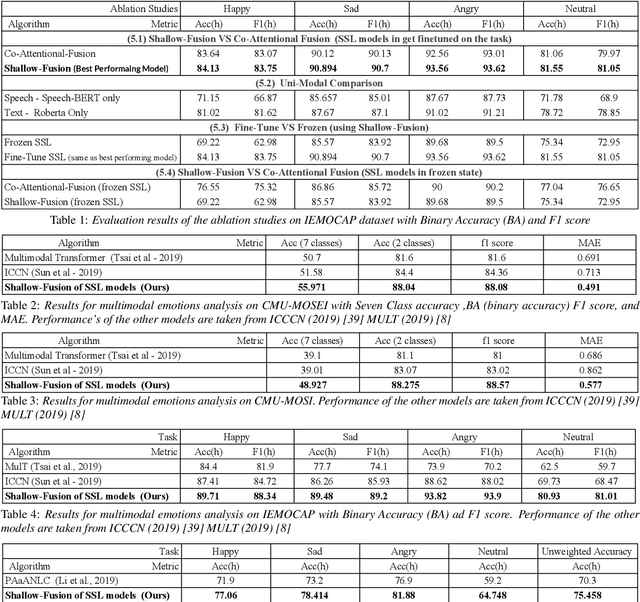
Multimodal emotion recognition from speech is an important area in affective computing. Fusing multiple data modalities and learning representations with limited amounts of labeled data is a challenging task. In this paper, we explore the use of modality-specific "BERT-like" pretrained Self Supervised Learning (SSL) architectures to represent both speech and text modalities for the task of multimodal speech emotion recognition. By conducting experiments on three publicly available datasets (IEMOCAP, CMU-MOSEI, and CMU-MOSI), we show that jointly fine-tuning "BERT-like" SSL architectures achieve state-of-the-art (SOTA) results. We also evaluate two methods of fusing speech and text modalities and show that a simple fusion mechanism can outperform more complex ones when using SSL models that have similar architectural properties to BERT.
Target Driven Visual Navigation with Hybrid Asynchronous Universal Successor Representations
Nov 27, 2018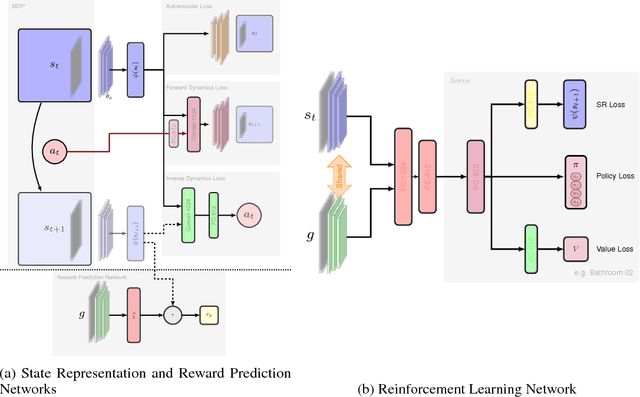


Being able to navigate to a target with minimal supervision and prior knowledge is critical to creating human-like assistive agents. Prior work on map-based and map-less approaches have limited generalizability. In this paper, we present a novel approach, Hybrid Asynchronous Universal Successor Representations (HAUSR), which overcomes the problem of generalizability to new goals by adapting recent work on Universal Successor Representations with Asynchronous Actor-Critic Agents. We show that the agent was able to successfully reach novel goals and we were able to quickly fine-tune the network for adapting to new scenes. This opens up novel application scenarios where intelligent agents could learn from and adapt to a wide range of environments with minimal human input.