 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeJointly Fine-Tuning "BERT-like" Self Supervised Models to Improve Multimodal Speech Emotion Recognition
Paper and Code
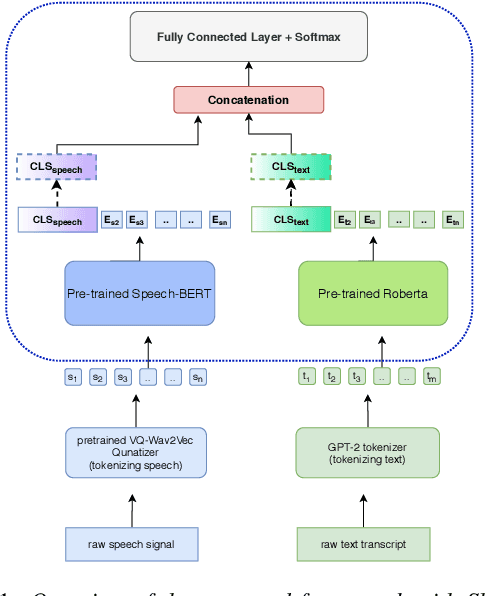
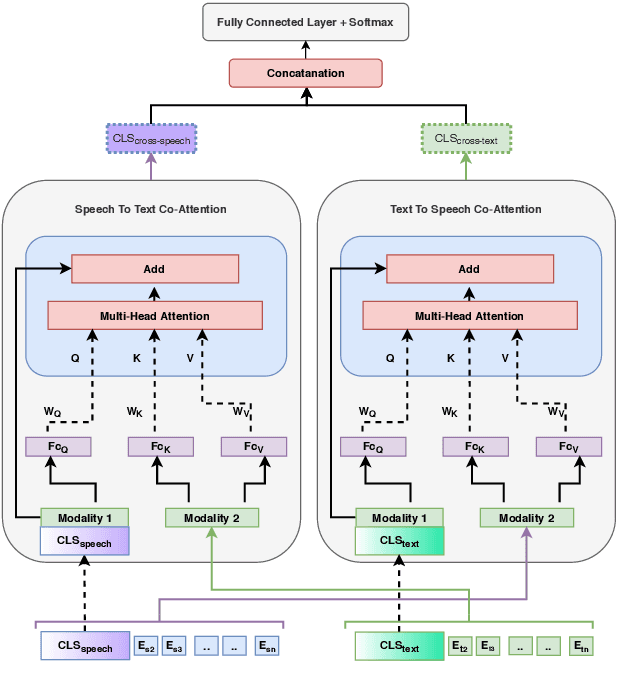
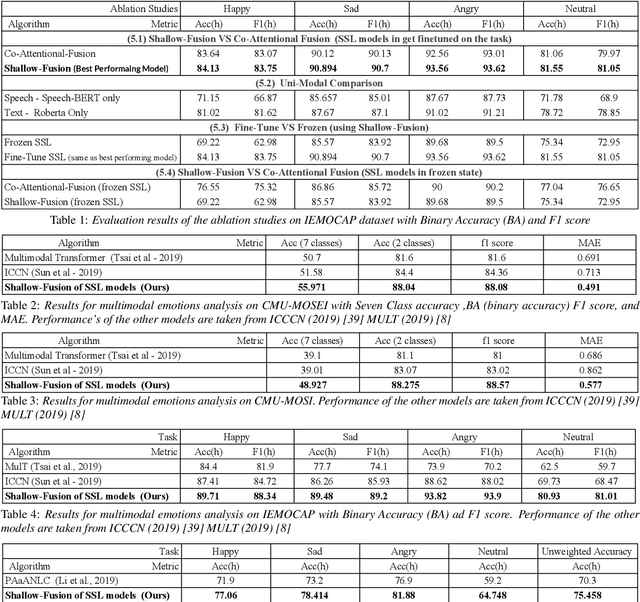
Multimodal emotion recognition from speech is an important area in affective computing. Fusing multiple data modalities and learning representations with limited amounts of labeled data is a challenging task. In this paper, we explore the use of modality-specific "BERT-like" pretrained Self Supervised Learning (SSL) architectures to represent both speech and text modalities for the task of multimodal speech emotion recognition. By conducting experiments on three publicly available datasets (IEMOCAP, CMU-MOSEI, and CMU-MOSI), we show that jointly fine-tuning "BERT-like" SSL architectures achieve state-of-the-art (SOTA) results. We also evaluate two methods of fusing speech and text modalities and show that a simple fusion mechanism can outperform more complex ones when using SSL models that have similar architectural properties to BERT.