 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeBalancing Performance and Energy Consumption of Bagging Ensembles for the Classification of Data Streams in Edge Computing
Jan 17, 2022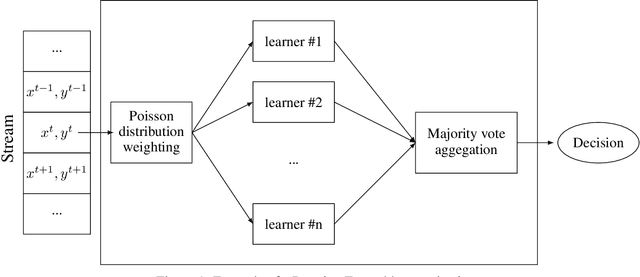
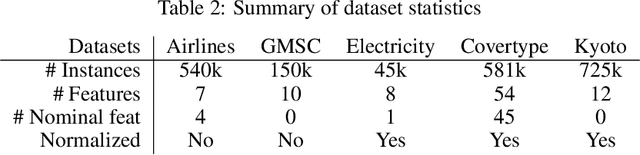
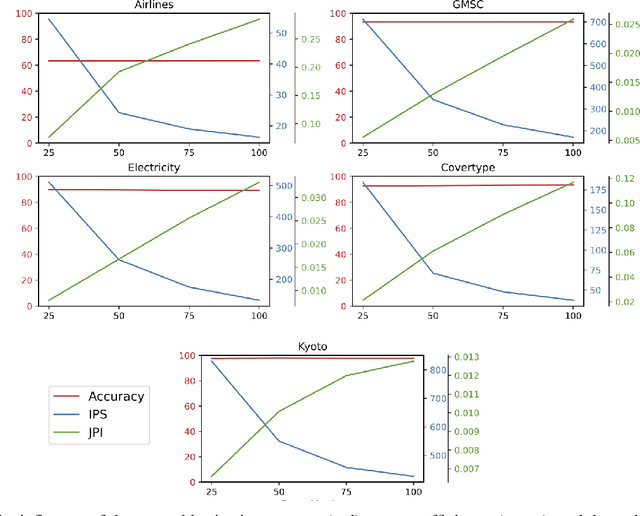
In recent years, the Edge Computing (EC) paradigm has emerged as an enabling factor for developing technologies like the Internet of Things (IoT) and 5G networks, bridging the gap between Cloud Computing services and end-users, supporting low latency, mobility, and location awareness to delay-sensitive applications. Most solutions in EC employ machine learning (ML) methods to perform data classification and other information processing tasks on continuous and evolving data streams. Usually, such solutions have to cope with vast amounts of data that come as data streams while balancing energy consumption, latency, and the predictive performance of the algorithms. Ensemble methods achieve remarkable predictive performance when applied to evolving data streams due to the combination of several models and the possibility of selective resets. This work investigates strategies for optimizing the performance (i.e., delay, throughput) and energy consumption of bagging ensembles to classify data streams. The experimental evaluation involved six state-of-art ensemble algorithms (OzaBag, OzaBag Adaptive Size Hoeffding Tree, Online Bagging ADWIN, Leveraging Bagging, Adaptive RandomForest, and Streaming Random Patches) applying five widely used machine learning benchmark datasets with varied characteristics on three computer platforms. Such strategies can significantly reduce energy consumption in 96% of the experimental scenarios evaluated. Despite the trade-offs, it is possible to balance them to avoid significant loss in predictive performance.
Improving the performance of bagging ensembles for data streams through mini-batching
Dec 18, 2021
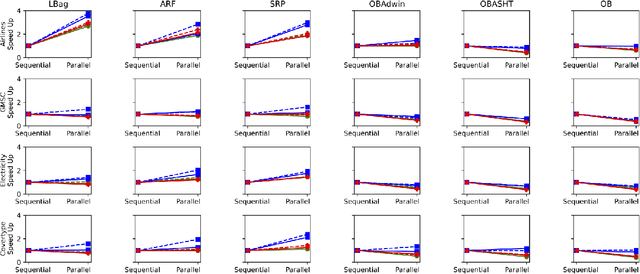


Often, machine learning applications have to cope with dynamic environments where data are collected in the form of continuous data streams with potentially infinite length and transient behavior. Compared to traditional (batch) data mining, stream processing algorithms have additional requirements regarding computational resources and adaptability to data evolution. They must process instances incrementally because the data's continuous flow prohibits storing data for multiple passes. Ensemble learning achieved remarkable predictive performance in this scenario. Implemented as a set of (several) individual classifiers, ensembles are naturally amendable for task parallelism. However, the incremental learning and dynamic data structures used to capture the concept drift increase the cache misses and hinder the benefit of parallelism. This paper proposes a mini-batching strategy that can improve memory access locality and performance of several ensemble algorithms for stream mining in multi-core environments. With the aid of a formal framework, we demonstrate that mini-batching can significantly decrease the reuse distance (and the number of cache misses). Experiments on six different state-of-the-art ensemble algorithms applying four benchmark datasets with varied characteristics show speedups of up to 5X on 8-core processors. These benefits come at the expense of a small reduction in predictive performance.
Modelling Energy Consumption based on Resource Utilization
Sep 15, 2017



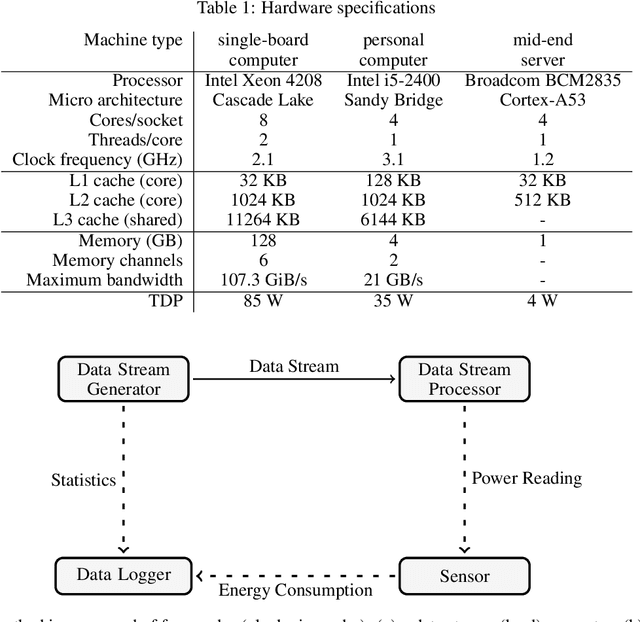
Power management is an expensive and important issue for large computational infrastructures such as datacenters, large clusters, and computational grids. However, measuring energy consumption of scalable systems may be impractical due to both cost and complexity for deploying power metering devices on a large number of machines. In this paper, we propose the use of information about resource utilization (e.g. processor, memory, disk operations, and network traffic) as proxies for estimating power consumption. We employ machine learning techniques to estimate power consumption using such information which are provided by common operating systems. Experiments with linear regression, regression tree, and multilayer perceptron on data from different hardware resulted into a model with 99.94\% of accuracy and 6.32 watts of error in the best case.