 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeBetter Self-training for Image Classification through Self-supervision
Sep 09, 2021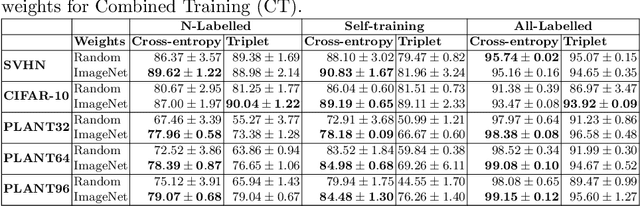
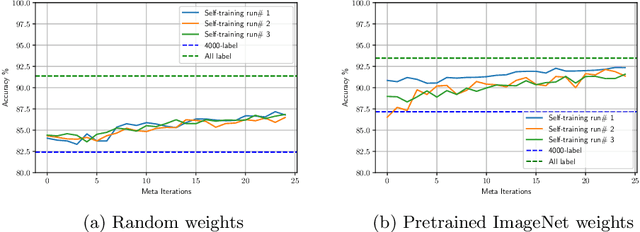
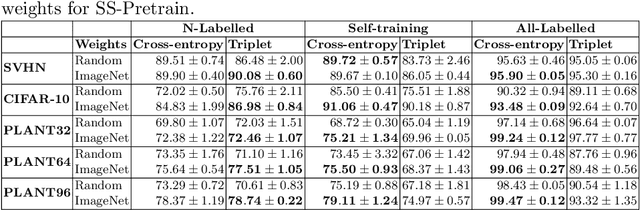
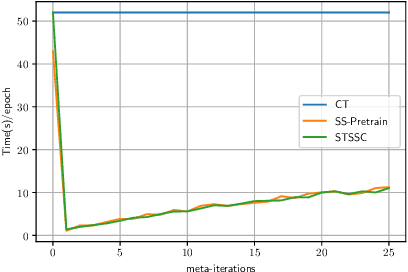
Self-training is a simple semi-supervised learning approach: Unlabelled examples that attract high-confidence predictions are labelled with their predictions and added to the training set, with this process being repeated multiple times. Recently, self-supervision -- learning without manual supervision by solving an automatically-generated pretext task -- has gained prominence in deep learning. This paper investigates three different ways of incorporating self-supervision into self-training to improve accuracy in image classification: self-supervision as pretraining only, self-supervision performed exclusively in the first iteration of self-training, and self-supervision added to every iteration of self-training. Empirical results on the SVHN, CIFAR-10, and PlantVillage datasets, using both training from scratch, and Imagenet-pretrained weights, show that applying self-supervision only in the first iteration of self-training can greatly improve accuracy, for a modest increase in computation time.
Transfer of Pretrained Model Weights Substantially Improves Semi-Supervised Image Classification
Sep 09, 2021
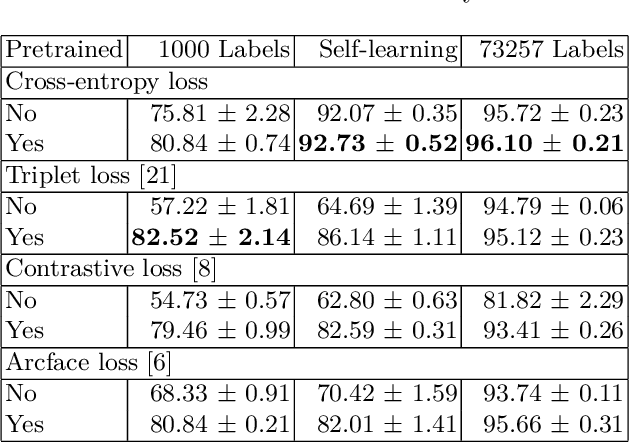
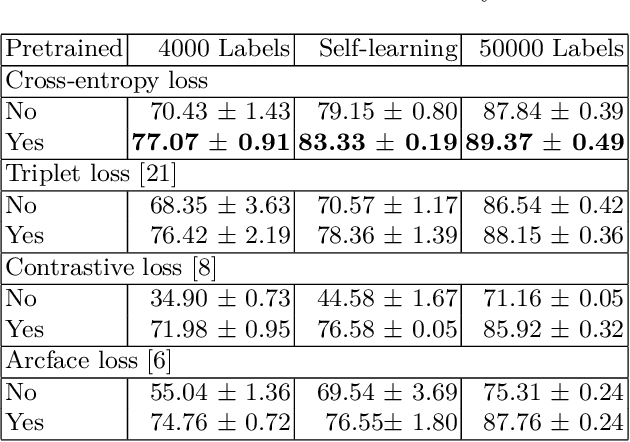

Deep neural networks produce state-of-the-art results when trained on a large number of labeled examples but tend to overfit when small amounts of labeled examples are used for training. Creating a large number of labeled examples requires considerable resources, time, and effort. If labeling new data is not feasible, so-called semi-supervised learning can achieve better generalisation than purely supervised learning by employing unlabeled instances as well as labeled ones. The work presented in this paper is motivated by the observation that transfer learning provides the opportunity to potentially further improve performance by exploiting models pretrained on a similar domain. More specifically, we explore the use of transfer learning when performing semi-supervised learning using self-learning. The main contribution is an empirical evaluation of transfer learning using different combinations of similarity metric learning methods and label propagation algorithms in semi-supervised learning. We find that transfer learning always substantially improves the model's accuracy when few labeled examples are available, regardless of the type of loss used for training the neural network. This finding is obtained by performing extensive experiments on the SVHN, CIFAR10, and Plant Village image classification datasets and applying pretrained weights from Imagenet for transfer learning.
* added link to code and data repo
Semi-Supervised Learning using Siamese Networks
Sep 09, 2021



Neural networks have been successfully used as classification models yielding state-of-the-art results when trained on a large number of labeled samples. These models, however, are more difficult to train successfully for semi-supervised problems where small amounts of labeled instances are available along with a large number of unlabeled instances. This work explores a new training method for semi-supervised learning that is based on similarity function learning using a Siamese network to obtain a suitable embedding. The learned representations are discriminative in Euclidean space, and hence can be used for labeling unlabeled instances using a nearest-neighbor classifier. Confident predictions of unlabeled instances are used as true labels for retraining the Siamese network on the expanded training set. This process is applied iteratively. We perform an empirical study of this iterative self-training algorithm. For improving unlabeled predictions, local learning with global consistency [22] is also evaluated.
* added link of GitHub repository