 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeRobust Anomaly Detection for Particle Physics Using Multi-Background Representation Learning
Jan 16, 2024Anomaly, or out-of-distribution, detection is a promising tool for aiding discoveries of new particles or processes in particle physics. In this work, we identify and address two overlooked opportunities to improve anomaly detection for high-energy physics. First, rather than train a generative model on the single most dominant background process, we build detection algorithms using representation learning from multiple background types, thus taking advantage of more information to improve estimation of what is relevant for detection. Second, we generalize decorrelation to the multi-background setting, thus directly enforcing a more complete definition of robustness for anomaly detection. We demonstrate the benefit of the proposed robust multi-background anomaly detection algorithms on a high-dimensional dataset of particle decays at the Large Hadron Collider.
Don't blame Dataset Shift! Shortcut Learning due to Gradients and Cross Entropy
Aug 24, 2023



Common explanations for shortcut learning assume that the shortcut improves prediction under the training distribution but not in the test distribution. Thus, models trained via the typical gradient-based optimization of cross-entropy, which we call default-ERM, utilize the shortcut. However, even when the stable feature determines the label in the training distribution and the shortcut does not provide any additional information, like in perception tasks, default-ERM still exhibits shortcut learning. Why are such solutions preferred when the loss for default-ERM can be driven to zero using the stable feature alone? By studying a linear perception task, we show that default-ERM's preference for maximizing the margin leads to models that depend more on the shortcut than the stable feature, even without overparameterization. This insight suggests that default-ERM's implicit inductive bias towards max-margin is unsuitable for perception tasks. Instead, we develop an inductive bias toward uniform margins and show that this bias guarantees dependence only on the perfect stable feature in the linear perception task. We develop loss functions that encourage uniform-margin solutions, called margin control (MARG-CTRL). MARG-CTRL mitigates shortcut learning on a variety of vision and language tasks, showing that better inductive biases can remove the need for expensive two-stage shortcut-mitigating methods in perception tasks.
When More is Less: Incorporating Additional Datasets Can Hurt Performance By Introducing Spurious Correlations
Aug 08, 2023



In machine learning, incorporating more data is often seen as a reliable strategy for improving model performance; this work challenges that notion by demonstrating that the addition of external datasets in many cases can hurt the resulting model's performance. In a large-scale empirical study across combinations of four different open-source chest x-ray datasets and 9 different labels, we demonstrate that in 43% of settings, a model trained on data from two hospitals has poorer worst group accuracy over both hospitals than a model trained on just a single hospital's data. This surprising result occurs even though the added hospital makes the training distribution more similar to the test distribution. We explain that this phenomenon arises from the spurious correlation that emerges between the disease and hospital, due to hospital-specific image artifacts. We highlight the trade-off one encounters when training on multiple datasets, between the obvious benefit of additional data and insidious cost of the introduced spurious correlation. In some cases, balancing the dataset can remove the spurious correlation and improve performance, but it is not always an effective strategy. We contextualize our results within the literature on spurious correlations to help explain these outcomes. Our experiments underscore the importance of exercising caution when selecting training data for machine learning models, especially in settings where there is a risk of spurious correlations such as with medical imaging. The risks outlined highlight the need for careful data selection and model evaluation in future research and practice.
Doc2Dict: Information Extraction as Text Generation
May 16, 2021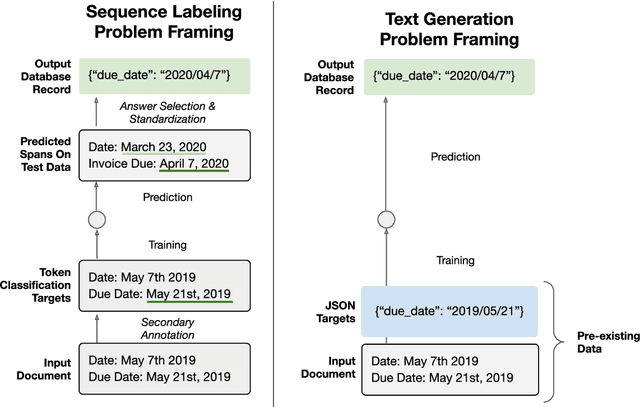
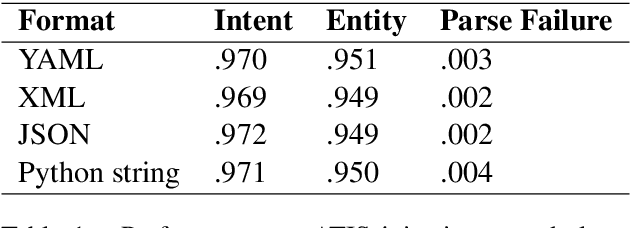
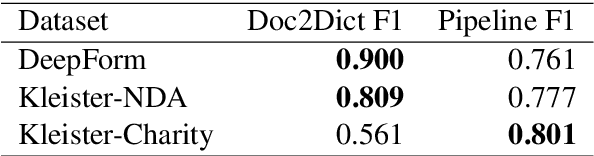
Typically, information extraction (IE) requires a pipeline approach: first, a sequence labeling model is trained on manually annotated documents to extract relevant spans; then, when a new document arrives, a model predicts spans which are then post-processed and standardized to convert the information into a database entry. We replace this labor-intensive workflow with a transformer language model trained on existing database records to directly generate structured JSON. Our solution removes the workload associated with producing token-level annotations and takes advantage of a data source which is generally quite plentiful (e.g. database records). As long documents are common in information extraction tasks, we use gradient checkpointing and chunked encoding to apply our method to sequences of up to 32,000 tokens on a single GPU. Our Doc2Dict approach is competitive with more complex, hand-engineered pipelines and offers a simple but effective baseline for document-level information extraction. We release our Doc2Dict model and code to reproduce our experiments and facilitate future work.