 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeBottom-Up and Top-Down Attention for Image Captioning and Visual Question Answering
Mar 14, 2018



Top-down visual attention mechanisms have been used extensively in image captioning and visual question answering (VQA) to enable deeper image understanding through fine-grained analysis and even multiple steps of reasoning. In this work, we propose a combined bottom-up and top-down attention mechanism that enables attention to be calculated at the level of objects and other salient image regions. This is the natural basis for attention to be considered. Within our approach, the bottom-up mechanism (based on Faster R-CNN) proposes image regions, each with an associated feature vector, while the top-down mechanism determines feature weightings. Applying this approach to image captioning, our results on the MSCOCO test server establish a new state-of-the-art for the task, achieving CIDEr / SPICE / BLEU-4 scores of 117.9, 21.5 and 36.9, respectively. Demonstrating the broad applicability of the method, applying the same approach to VQA we obtain first place in the 2017 VQA Challenge.
Semantic-driven Generation of Hyperlapse from $360^\circ$ Video
Oct 10, 2017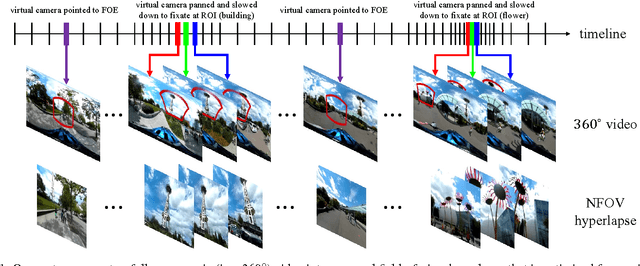

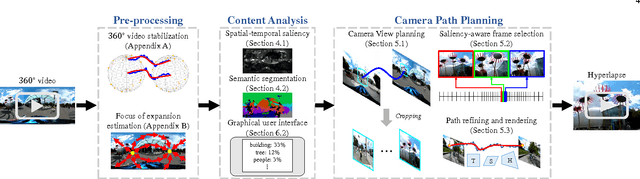
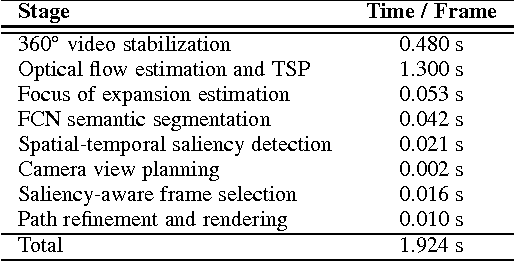
We present a system for converting a fully panoramic ($360^\circ$) video into a normal field-of-view (NFOV) hyperlapse for an optimal viewing experience. Our system exploits visual saliency and semantics to non-uniformly sample in space and time for generating hyperlapses. In addition, users can optionally choose objects of interest for customizing the hyperlapses. We first stabilize an input $360^\circ$ video by smoothing the rotation between adjacent frames and then compute regions of interest and saliency scores. An initial hyperlapse is generated by optimizing the saliency and motion smoothness followed by the saliency-aware frame selection. We further smooth the result using an efficient 2D video stabilization approach that adaptively selects the motion model to generate the final hyperlapse. We validate the design of our system by showing results for a variety of scenes and comparing against the state-of-the-art method through a user study.
Rich Image Captioning in the Wild
Mar 31, 2016
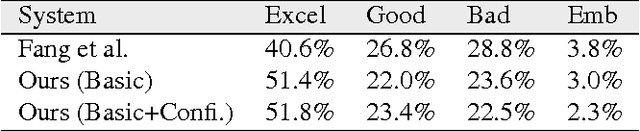
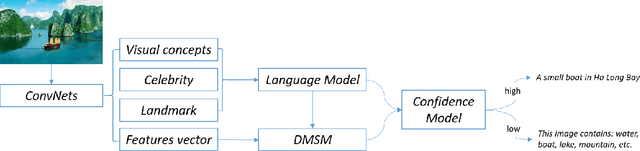
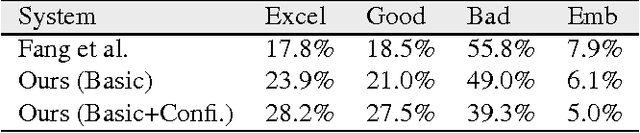
We present an image caption system that addresses new challenges of automatically describing images in the wild. The challenges include high quality caption quality with respect to human judgments, out-of-domain data handling, and low latency required in many applications. Built on top of a state-of-the-art framework, we developed a deep vision model that detects a broad range of visual concepts, an entity recognition model that identifies celebrities and landmarks, and a confidence model for the caption output. Experimental results show that our caption engine outperforms previous state-of-the-art systems significantly on both in-domain dataset (i.e. MS COCO) and out of-domain datasets.