Get our free extension to see links to code for papers anywhere online!Free add-on: code for papers everywhere!Free add-on: See code for papers anywhere!
 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeRich Image Captioning in the Wild
Paper and Code
Mar 31, 2016
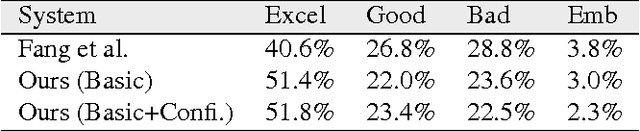
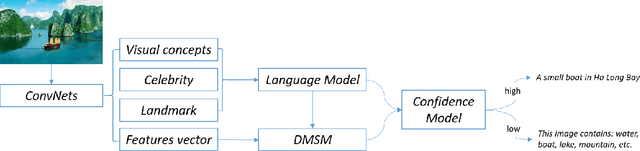
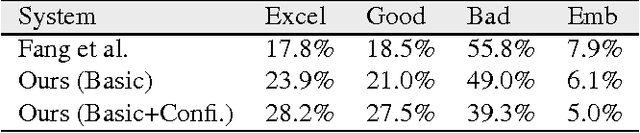
We present an image caption system that addresses new challenges of automatically describing images in the wild. The challenges include high quality caption quality with respect to human judgments, out-of-domain data handling, and low latency required in many applications. Built on top of a state-of-the-art framework, we developed a deep vision model that detects a broad range of visual concepts, an entity recognition model that identifies celebrities and landmarks, and a confidence model for the caption output. Experimental results show that our caption engine outperforms previous state-of-the-art systems significantly on both in-domain dataset (i.e. MS COCO) and out of-domain datasets.
View paper on