 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLearning Evidence Highlighting for Frozen LLMs
Apr 24, 2026Large Language Models (LLMs) can reason well, yet often miss decisive evidence when it is buried in long, noisy contexts. We introduce HiLight, an Evidence Emphasis framework that decouples evidence selection from reasoning for frozen LLM solvers. HiLight avoids compressing or rewriting the input, which can discard or distort evidence, by training a lightweight Emphasis Actor to insert minimal highlight tags around pivotal spans in the unaltered context. A frozen Solver then performs downstream reasoning on the emphasized input. We cast highlighting as a weakly supervised decision-making problem and optimize the Actor with reinforcement learning using only the Solver's task reward, requiring no evidence labels and no access to or modification of the Solver. Across sequential recommendation and long-context question answering, HiLight consistently improves performance over strong prompt-based and automated prompt-optimization baselines. The learned emphasis policy transfers zero-shot to both smaller and larger unseen Solver families, including an API-based Solver, suggesting that the Actor captures genuine, reusable evidence structure rather than overfitting to a single backbone.
Efficient Retrieval Scaling with Hierarchical Indexing for Large Scale Recommendation
Apr 14, 2026The increase in data volume, computational resources, and model parameters during training has led to the development of numerous large-scale industrial retrieval models for recommendation tasks. However, effectively and efficiently deploying these large-scale foundational retrieval models remains a critical challenge that has not been fully addressed. Common quick-win solutions for deploying these massive models include relying on offline computations (such as cached user dictionaries) or distilling large models into smaller ones. Yet, both approaches fall short of fully leveraging the representational and inference capabilities of foundational models. In this paper, we explore whether it is possible to learn a hierarchical organization over the memory of foundational retrieval models. Such a hierarchical structure would enable more efficient search by reducing retrieval costs while preserving exactness. To achieve this, we propose jointly learning a hierarchical index using cross-attention and residual quantization for large-scale retrieval models. We also present its real-world deployment at Meta, supporting daily advertisement recommendations for billions of Facebook and Instagram users. Interestingly, we discovered that the intermediate nodes in the learned index correspond to a small set of high-quality data. Fine-tuning the model on this set further improves inference performance, and concretize the concept of "test-time training" within the recommendation system domain. We demonstrate these findings using both internal and public datasets with strong baseline comparisons and hope they contribute to the community's efforts in developing the next generation of foundational retrieval models.
SOLARIS: Speculative Offloading of Latent-bAsed Representation for Inference Scaling
Apr 13, 2026Recent advances in recommendation scaling laws have led to foundation models of unprecedented complexity. While these models offer superior performance, their computational demands make real-time serving impractical, often forcing practitioners to rely on knowledge distillation-compromising serving quality for efficiency. To address this challenge, we present SOLARIS (Speculative Offloading of Latent-bAsed Representation for Inference Scaling), a novel framework inspired by speculative decoding. SOLARIS proactively precomputes user-item interaction embeddings by predicting which user-item pairs are likely to appear in future requests, and asynchronously generating their foundation model representations ahead of time. This approach decouples the costly foundation model inference from the latency-critical serving path, enabling real-time knowledge transfer from models previously considered too expensive for online use. Deployed across Meta's advertising system serving billions of daily requests, SOLARIS achieves 0.67% revenue-driving top-line metrics gain, demonstrating its effectiveness at scale.
Hierarchical Structured Neural Network for Retrieval
Aug 13, 2024



Embedding Based Retrieval (EBR) is a crucial component of the retrieval stage in (Ads) Recommendation System that utilizes Two Tower or Siamese Networks to learn embeddings for both users and items (ads). It then employs an Approximate Nearest Neighbor Search (ANN) to efficiently retrieve the most relevant ads for a specific user. Despite the recent rise to popularity in the industry, they have a couple of limitations. Firstly, Two Tower model architecture uses a single dot product interaction which despite their efficiency fail to capture the data distribution in practice. Secondly, the centroid representation and cluster assignment, which are components of ANN, occur after the training process has been completed. As a result, they do not take into account the optimization criteria used for retrieval model. In this paper, we present Hierarchical Structured Neural Network (HSNN), a deployed jointly optimized hierarchical clustering and neural network model that can take advantage of sophisticated interactions and model architectures that are more common in the ranking stages while maintaining a sub-linear inference cost. We achieve 6.5% improvement in offline evaluation and also demonstrate 1.22% online gains through A/B experiments. HSNN has been successfully deployed into the Ads Recommendation system and is currently handling major portion of the traffic. The paper shares our experience in developing this system, dealing with challenges like freshness, volatility, cold start recommendations, cluster collapse and lessons deploying the model in a large scale retrieval production system.
Continuous-Time Flows for Efficient Inference and Density Estimation
Aug 01, 2018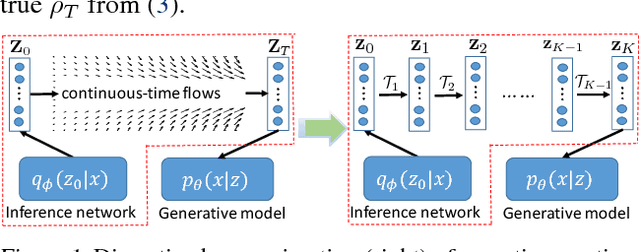

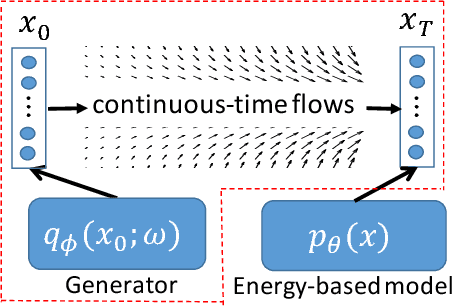
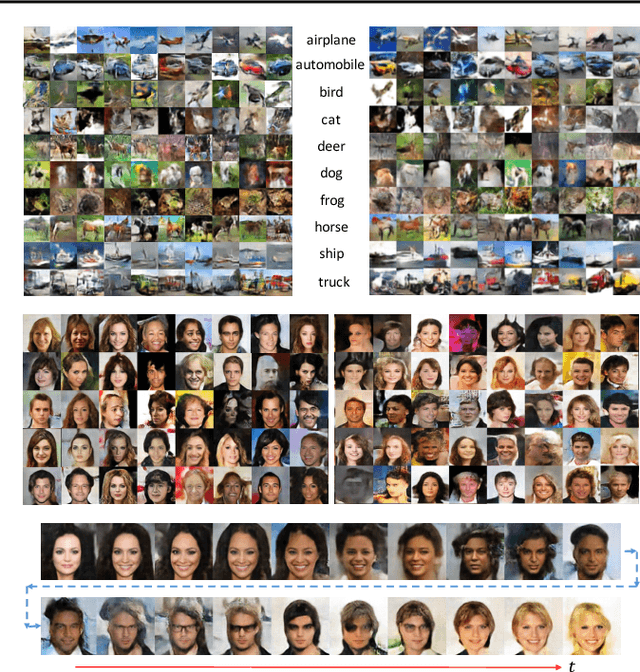
Two fundamental problems in unsupervised learning are efficient inference for latent-variable models and robust density estimation based on large amounts of unlabeled data. Algorithms for the two tasks, such as normalizing flows and generative adversarial networks (GANs), are often developed independently. In this paper, we propose the concept of {\em continuous-time flows} (CTFs), a family of diffusion-based methods that are able to asymptotically approach a target distribution. Distinct from normalizing flows and GANs, CTFs can be adopted to achieve the above two goals in one framework, with theoretical guarantees. Our framework includes distilling knowledge from a CTF for efficient inference, and learning an explicit energy-based distribution with CTFs for density estimation. Both tasks rely on a new technique for distribution matching within amortized learning. Experiments on various tasks demonstrate promising performance of the proposed CTF framework, compared to related techniques.
JointGAN: Multi-Domain Joint Distribution Learning with Generative Adversarial Nets
Jun 08, 2018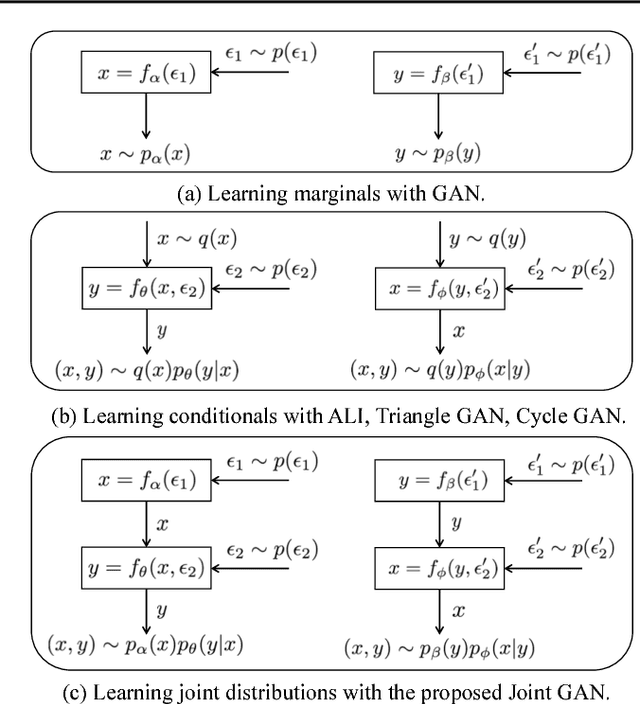
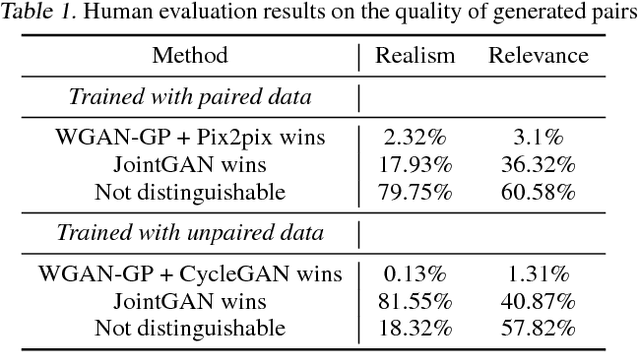
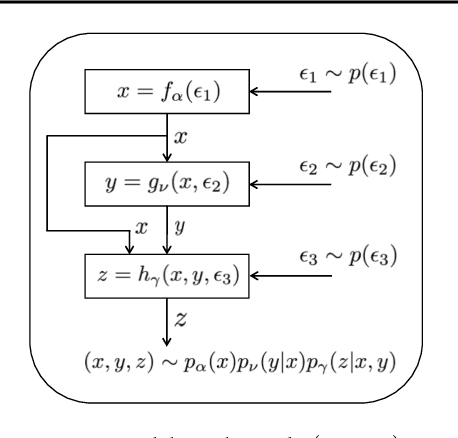
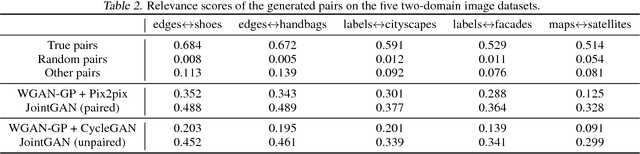
A new generative adversarial network is developed for joint distribution matching. Distinct from most existing approaches, that only learn conditional distributions, the proposed model aims to learn a joint distribution of multiple random variables (domains). This is achieved by learning to sample from conditional distributions between the domains, while simultaneously learning to sample from the marginals of each individual domain. The proposed framework consists of multiple generators and a single softmax-based critic, all jointly trained via adversarial learning. From a simple noise source, the proposed framework allows synthesis of draws from the marginals, conditional draws given observations from a subset of random variables, or complete draws from the full joint distribution. Most examples considered are for joint analysis of two domains, with examples for three domains also presented.
Zero-Shot Learning via Class-Conditioned Deep Generative Models
Nov 19, 2017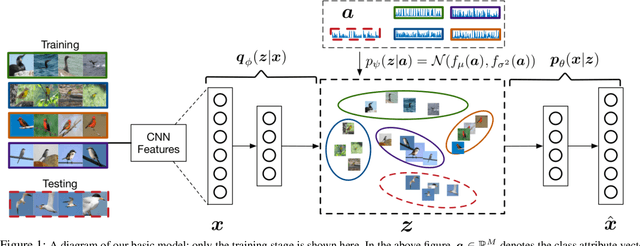
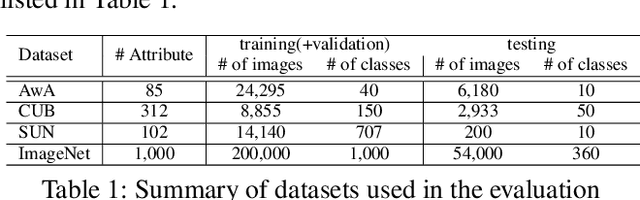
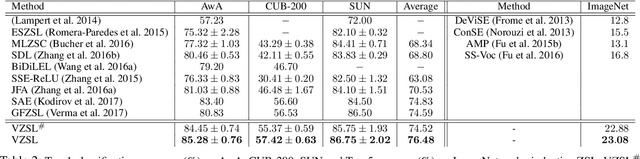
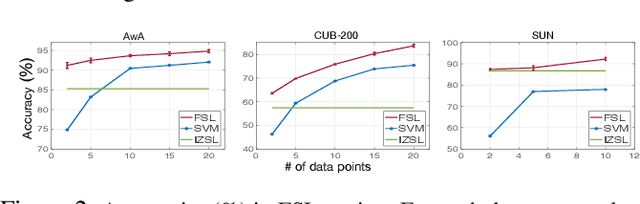
We present a deep generative model for learning to predict classes not seen at training time. Unlike most existing methods for this problem, that represent each class as a point (via a semantic embedding), we represent each seen/unseen class using a class-specific latent-space distribution, conditioned on class attributes. We use these latent-space distributions as a prior for a supervised variational autoencoder (VAE), which also facilitates learning highly discriminative feature representations for the inputs. The entire framework is learned end-to-end using only the seen-class training data. The model infers corresponding attributes of a test image by maximizing the VAE lower bound; the inferred attributes may be linked to labels not seen when training. We further extend our model to a (1) semi-supervised/transductive setting by leveraging unlabeled unseen-class data via an unsupervised learning module, and (2) few-shot learning where we also have a small number of labeled inputs from the unseen classes. We compare our model with several state-of-the-art methods through a comprehensive set of experiments on a variety of benchmark data sets.
Triangle Generative Adversarial Networks
Nov 18, 2017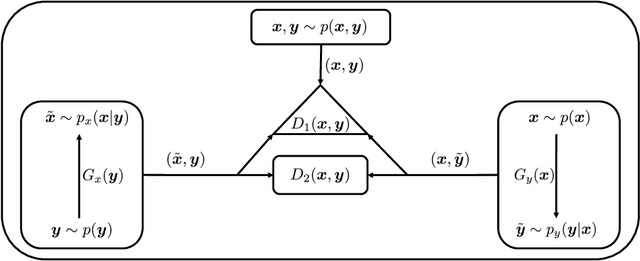
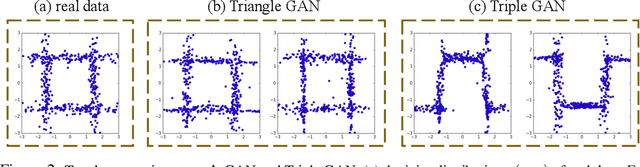
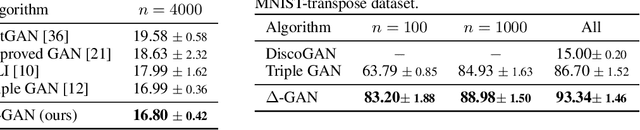

A Triangle Generative Adversarial Network ($\Delta$-GAN) is developed for semi-supervised cross-domain joint distribution matching, where the training data consists of samples from each domain, and supervision of domain correspondence is provided by only a few paired samples. $\Delta$-GAN consists of four neural networks, two generators and two discriminators. The generators are designed to learn the two-way conditional distributions between the two domains, while the discriminators implicitly define a ternary discriminative function, which is trained to distinguish real data pairs and two kinds of fake data pairs. The generators and discriminators are trained together using adversarial learning. Under mild assumptions, in theory the joint distributions characterized by the two generators concentrate to the data distribution. In experiments, three different kinds of domain pairs are considered, image-label, image-image and image-attribute pairs. Experiments on semi-supervised image classification, image-to-image translation and attribute-based image generation demonstrate the superiority of the proposed approach.
Adversarial Symmetric Variational Autoencoder
Nov 18, 2017
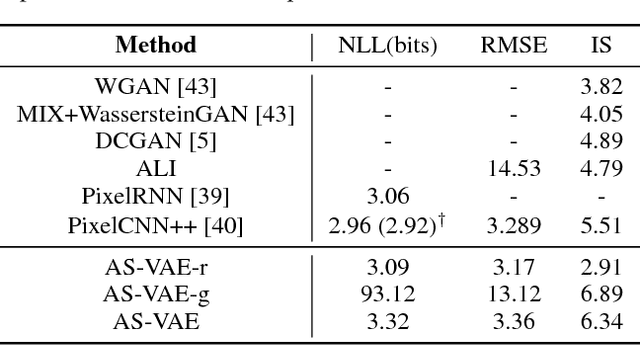

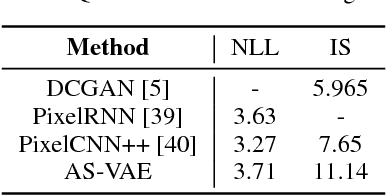
A new form of variational autoencoder (VAE) is developed, in which the joint distribution of data and codes is considered in two (symmetric) forms: ($i$) from observed data fed through the encoder to yield codes, and ($ii$) from latent codes drawn from a simple prior and propagated through the decoder to manifest data. Lower bounds are learned for marginal log-likelihood fits observed data and latent codes. When learning with the variational bound, one seeks to minimize the symmetric Kullback-Leibler divergence of joint density functions from ($i$) and ($ii$), while simultaneously seeking to maximize the two marginal log-likelihoods. To facilitate learning, a new form of adversarial training is developed. An extensive set of experiments is performed, in which we demonstrate state-of-the-art data reconstruction and generation on several image benchmark datasets.
VAE Learning via Stein Variational Gradient Descent
Nov 17, 2017


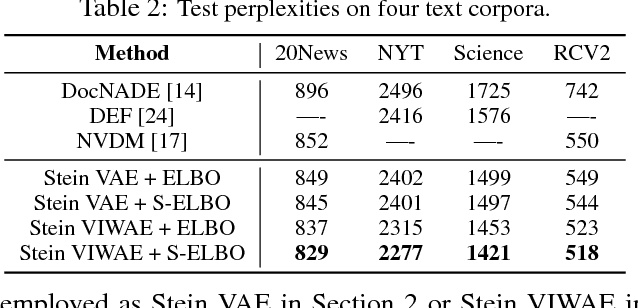
A new method for learning variational autoencoders (VAEs) is developed, based on Stein variational gradient descent. A key advantage of this approach is that one need not make parametric assumptions about the form of the encoder distribution. Performance is further enhanced by integrating the proposed encoder with importance sampling. Excellent performance is demonstrated across multiple unsupervised and semi-supervised problems, including semi-supervised analysis of the ImageNet data, demonstrating the scalability of the model to large datasets.