 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeGrounDial: Human-norm Grounded Safe Dialog Response Generation
Feb 14, 2024



Current conversational AI systems based on large language models (LLMs) are known to generate unsafe responses, agreeing to offensive user input or including toxic content. Previous research aimed to alleviate the toxicity, by fine-tuning LLM with manually annotated safe dialogue histories. However, the dependency on additional tuning requires substantial costs. To remove the dependency, we propose GrounDial, where response safety is achieved by grounding responses to commonsense social rules without requiring fine-tuning. A hybrid approach of in-context learning and human-norm-guided decoding of GrounDial enables the response to be quantitatively and qualitatively safer even without additional data or tuning.
CLUB: A Contrastive Log-ratio Upper Bound of Mutual Information
Jul 14, 2020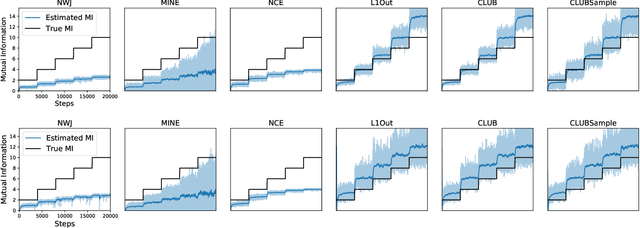
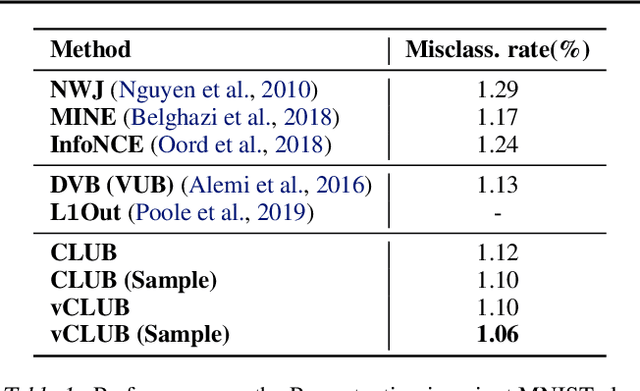

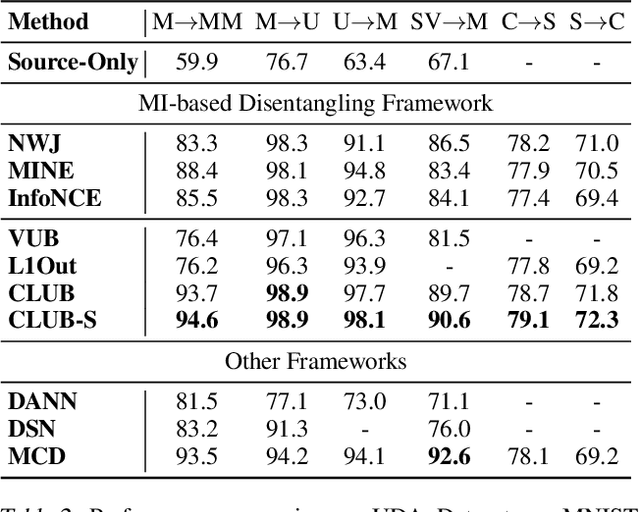
Mutual information (MI) minimization has gained considerable interests in various machine learning tasks. However, estimating and minimizing MI in high-dimensional spaces remains a challenging problem, especially when only samples, rather than distribution forms, are accessible. Previous works mainly focus on MI lower bound approximation, which is not applicable to MI minimization problems. In this paper, we propose a novel Contrastive Log-ratio Upper Bound (CLUB) of mutual information. We provide a theoretical analysis of the properties of CLUB and its variational approximation. Based on this upper bound, we introduce an accelerated MI minimization training scheme, which bridges MI minimization with negative sampling. Simulation studies on Gaussian distributions show the reliable estimation ability of CLUB. Real-world MI minimization experiments, including domain adaptation and information bottleneck, further demonstrate the effectiveness of the proposed method. The code is at https://github.com/Linear95/CLUB.
Bridging Maximum Likelihood and Adversarial Learning via $α$-Divergence
Jul 13, 2020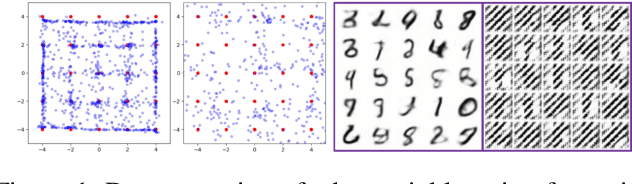

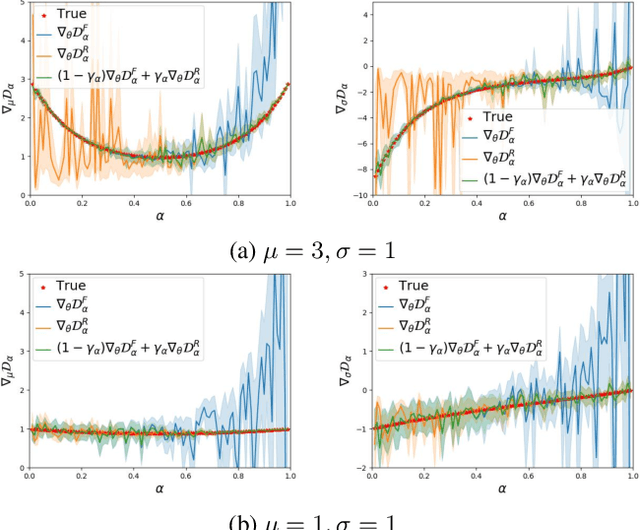

Maximum likelihood (ML) and adversarial learning are two popular approaches for training generative models, and from many perspectives these techniques are complementary. ML learning encourages the capture of all data modes, and it is typically characterized by stable training. However, ML learning tends to distribute probability mass diffusely over the data space, $e.g.$, yielding blurry synthetic images. Adversarial learning is well known to synthesize highly realistic natural images, despite practical challenges like mode dropping and delicate training. We propose an $\alpha$-Bridge to unify the advantages of ML and adversarial learning, enabling the smooth transfer from one to the other via the $\alpha$-divergence. We reveal that generalizations of the $\alpha$-Bridge are closely related to approaches developed recently to regularize adversarial learning, providing insights into that prior work, and further understanding of why the $\alpha$-Bridge performs well in practice.
APo-VAE: Text Generation in Hyperbolic Space
Apr 30, 2020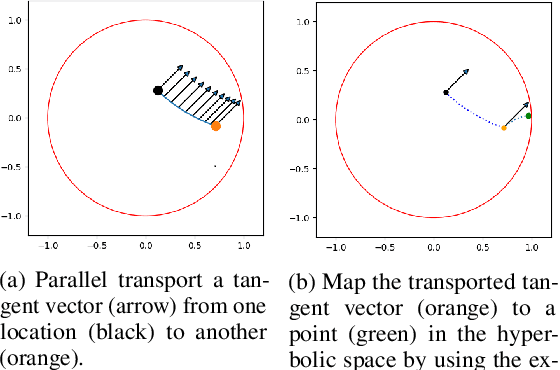
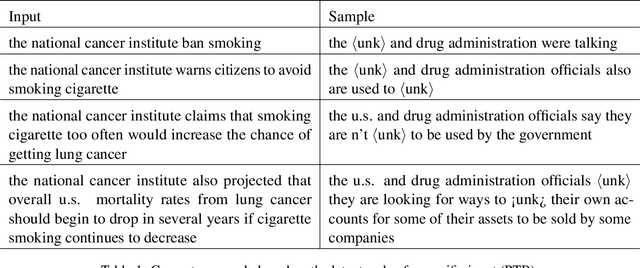
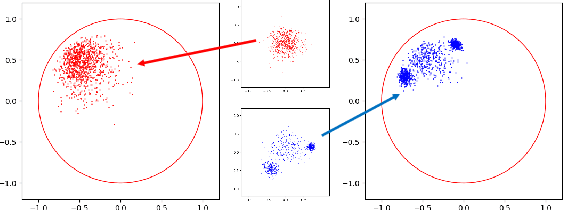
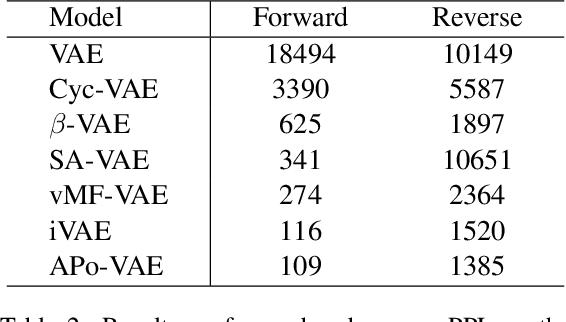
Natural language often exhibits inherent hierarchical structure ingrained with complex syntax and semantics. However, most state-of-the-art deep generative models learn embeddings only in Euclidean vector space, without accounting for this structural property of language. In this paper, we investigate text generation in a hyperbolic latent space to learn continuous hierarchical representations. An Adversarial Poincare Variational Autoencoder (APo-VAE) is presented, where both the prior and variational posterior of latent variables are defined over a Poincare ball via wrapped normal distributions. By adopting the primal-dual formulation of KL divergence, an adversarial learning procedure is introduced to empower robust model training. Extensive experiments in language modeling and dialog-response generation tasks demonstrate the winning effectiveness of the proposed APo-VAE model over VAEs in Euclidean latent space, thanks to its superb capabilities in capturing latent language hierarchies in hyperbolic space.
Contrastively Smoothed Class Alignment for Unsupervised Domain Adaptation
Sep 13, 2019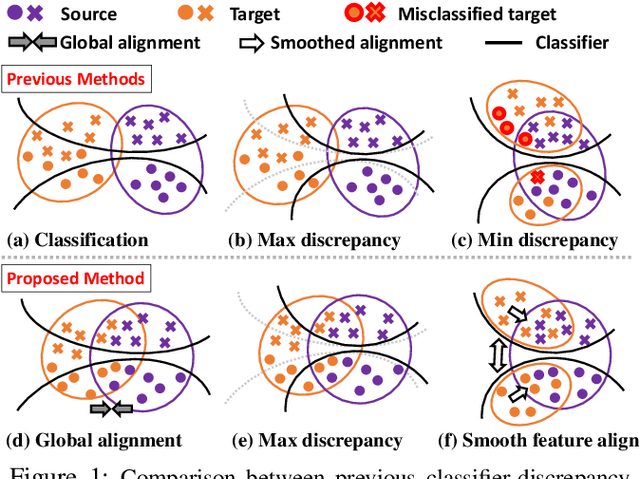
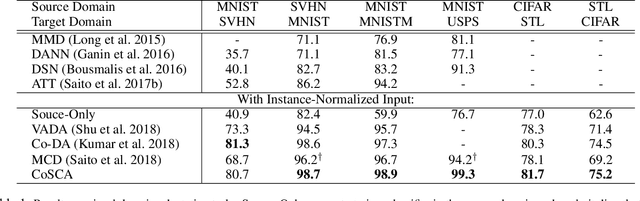
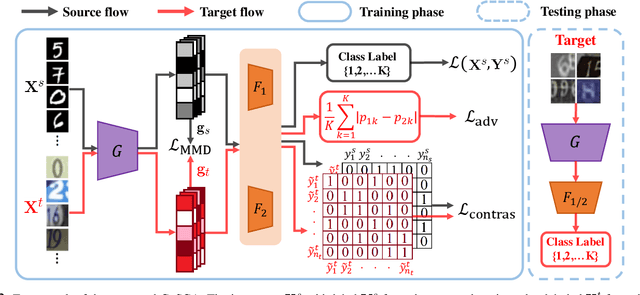
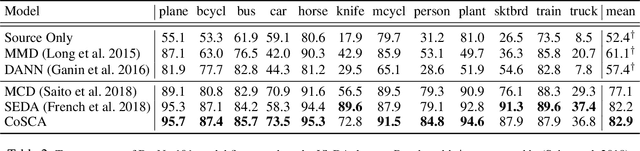
Recent unsupervised approaches to domain adaptation primarily focus on minimizing the gap between the source and the target domains through refining the feature generator, in order to learn a better alignment between the two domains. This minimization can be achieved via a domain classifier to detect target-domain features that are divergent from source-domain features. However, by optimizing via such domain classification discrepancy, ambiguous target samples that are not smoothly distributed on the low-dimensional data manifold are often missed. To solve this issue, we propose a novel Contrastively Smoothed Class Alignment (CoSCA) model, that explicitly incorporates both intra- and inter-class domain discrepancy to better align ambiguous target samples with the source domain. CoSCA estimates the underlying label hypothesis of target samples, and simultaneously adapts their feature representations by optimizing a proposed contrastive loss. In addition, Maximum Mean Discrepancy (MMD) is utilized to directly match features between source and target samples for better global alignment. Experiments on several benchmark datasets demonstrate that CoSCA can outperform state-of-the-art approaches for unsupervised domain adaptation by producing more discriminative features.
Adaptation Across Extreme Variations using Unlabeled Domain Bridges
Jun 05, 2019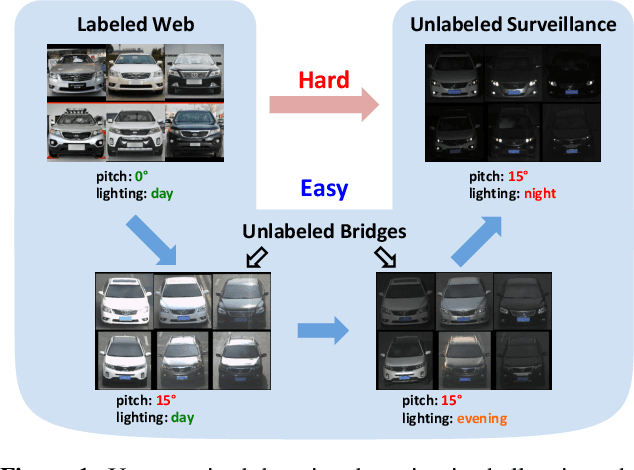

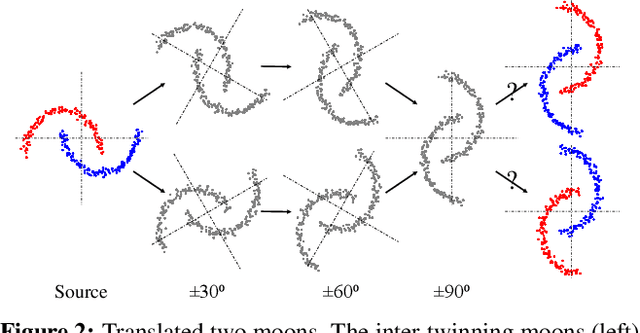

We tackle an unsupervised domain adaptation problem for which the domain discrepancy between labeled source and unlabeled target domains is large, due to many factors of inter and intra-domain variation. While deep domain adaptation methods have been realized by reducing the domain discrepancy, these are difficult to apply when domains are significantly unalike. In this work, we propose to decompose domain discrepancy into multiple but smaller, and thus easier to minimize, discrepancies by introducing unlabeled bridging domains that connect the source and target domains. We realize our proposal through an extension of the domain adversarial neural network with multiple discriminators, each of which accounts for reducing discrepancies between unlabeled (bridge, target) domains and a mix of all precedent domains including source. We validate the effectiveness of our method on several adaptation tasks including object recognition and semantic segmentation.
Adversarial Text Generation via Feature-Mover's Distance
Sep 17, 2018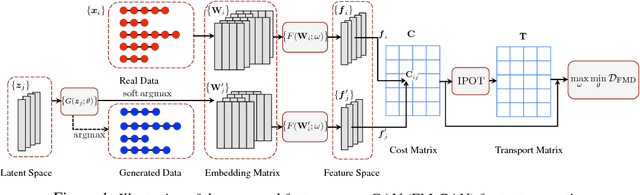

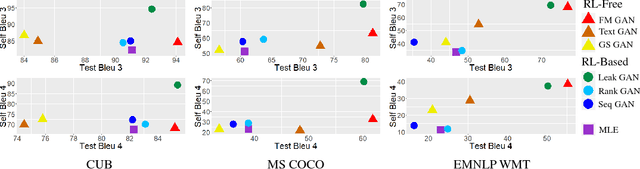

Generative adversarial networks (GANs) have achieved significant success in generating real-valued data. However, the discrete nature of text hinders the application of GAN to text-generation tasks. Instead of using the standard GAN objective, we propose to improve text-generation GAN via a novel approach inspired by optimal transport. Specifically, we consider matching the latent feature distributions of real and synthetic sentences using a novel metric, termed the feature-mover's distance (FMD). This formulation leads to a highly discriminative critic and easy-to-optimize objective, overcoming the mode-collapsing and brittle-training problems in existing methods. Extensive experiments are conducted on a variety of tasks to evaluate the proposed model empirically, including unconditional text generation, style transfer from non-parallel text, and unsupervised cipher cracking. The proposed model yields superior performance, demonstrating wide applicability and effectiveness.
JointGAN: Multi-Domain Joint Distribution Learning with Generative Adversarial Nets
Jun 08, 2018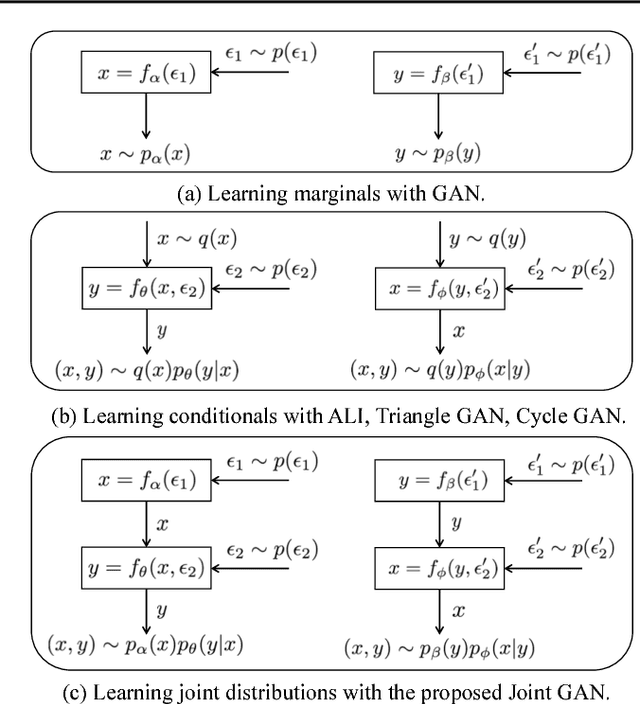
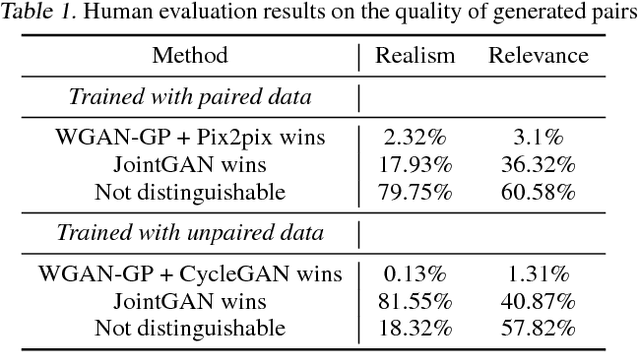
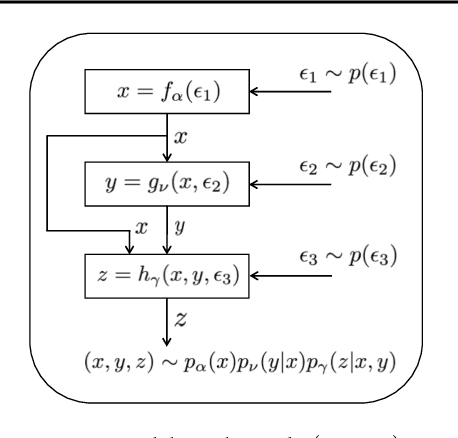
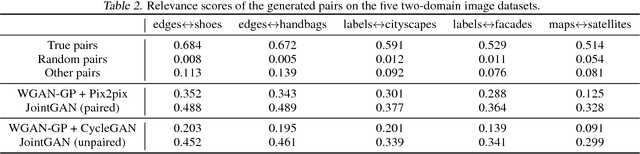
A new generative adversarial network is developed for joint distribution matching. Distinct from most existing approaches, that only learn conditional distributions, the proposed model aims to learn a joint distribution of multiple random variables (domains). This is achieved by learning to sample from conditional distributions between the domains, while simultaneously learning to sample from the marginals of each individual domain. The proposed framework consists of multiple generators and a single softmax-based critic, all jointly trained via adversarial learning. From a simple noise source, the proposed framework allows synthesis of draws from the marginals, conditional draws given observations from a subset of random variables, or complete draws from the full joint distribution. Most examples considered are for joint analysis of two domains, with examples for three domains also presented.
Symmetric Variational Autoencoder and Connections to Adversarial Learning
Oct 19, 2017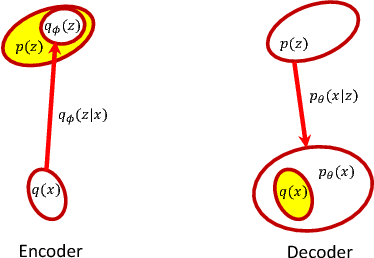
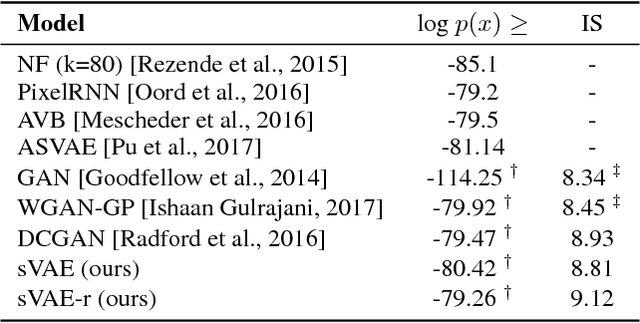
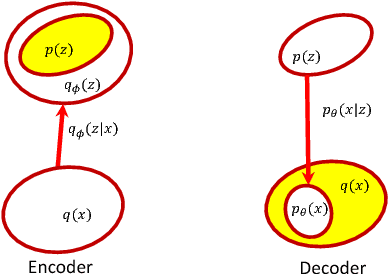
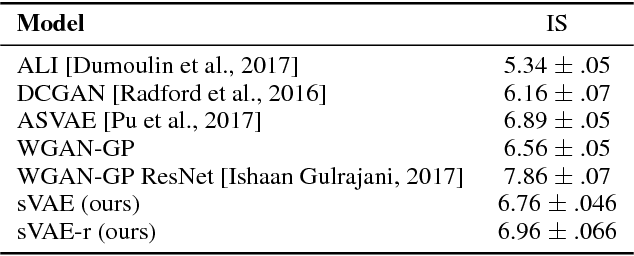
A new form of the variational autoencoder (VAE) is proposed, based on the symmetric Kullback-Leibler divergence. It is demonstrated that learning of the resulting symmetric VAE (sVAE) has close connections to previously developed adversarial-learning methods. This relationship helps unify the previously distinct techniques of VAE and adversarially learning, and provides insights that allow us to ameliorate shortcomings with some previously developed adversarial methods. In addition to an analysis that motivates and explains the sVAE, an extensive set of experiments validate the utility of the approach.