 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMelodia: Training-Free Music Editing Guided by Attention Probing in Diffusion Models
Nov 18, 2025



Text-to-music generation technology is progressing rapidly, creating new opportunities for musical composition and editing. However, existing music editing methods often fail to preserve the source music's temporal structure, including melody and rhythm, when altering particular attributes like instrument, genre, and mood. To address this challenge, this paper conducts an in-depth probing analysis on attention maps within AudioLDM 2, a diffusion-based model commonly used as the backbone for existing music editing methods. We reveal a key finding: cross-attention maps encompass details regarding distinct musical characteristics, and interventions on these maps frequently result in ineffective modifications. In contrast, self-attention maps are essential for preserving the temporal structure of the source music during its conversion into the target music. Building upon this understanding, we present Melodia, a training-free technique that selectively manipulates self-attention maps in particular layers during the denoising process and leverages an attention repository to store source music information, achieving accurate modification of musical characteristics while preserving the original structure without requiring textual descriptions of the source music. Additionally, we propose two novel metrics to better evaluate music editing methods. Both objective and subjective experiments demonstrate that our approach achieves superior results in terms of textual adherence and structural integrity across various datasets. This research enhances comprehension of internal mechanisms within music generation models and provides improved control for music creation.
A Physics-Informed Blur Learning Framework for Imaging Systems
Feb 17, 2025Accurate blur estimation is essential for high-performance imaging across various applications. Blur is typically represented by the point spread function (PSF). In this paper, we propose a physics-informed PSF learning framework for imaging systems, consisting of a simple calibration followed by a learning process. Our framework could achieve both high accuracy and universal applicability. Inspired by the Seidel PSF model for representing spatially varying PSF, we identify its limitations in optimization and introduce a novel wavefront-based PSF model accompanied by an optimization strategy, both reducing optimization complexity and improving estimation accuracy. Moreover, our wavefront-based PSF model is independent of lens parameters, eliminate the need for prior knowledge of the lens. To validate our approach, we compare it with recent PSF estimation methods (Degradation Transfer and Fast Two-step) through a deblurring task, where all the estimated PSFs are used to train state-of-the-art deblurring algorithms. Our approach demonstrates improvements in image quality in simulation and also showcases noticeable visual quality improvements on real captured images.
Tolerance-Aware Deep Optics
Feb 07, 2025Deep optics has emerged as a promising approach by co-designing optical elements with deep learning algorithms. However, current research typically overlooks the analysis and optimization of manufacturing and assembly tolerances. This oversight creates a significant performance gap between designed and fabricated optical systems. To address this challenge, we present the first end-to-end tolerance-aware optimization framework that incorporates multiple tolerance types into the deep optics design pipeline. Our method combines physics-informed modelling with data-driven training to enhance optical design by accounting for and compensating for structural deviations in manufacturing and assembly. We validate our approach through computational imaging applications, demonstrating results in both simulations and real-world experiments. We further examine how our proposed solution improves the robustness of optical systems and vision algorithms against tolerances through qualitative and quantitative analyses. Code and additional visual results are available at openimaginglab.github.io/LensTolerance.
DriveEditor: A Unified 3D Information-Guided Framework for Controllable Object Editing in Driving Scenes
Dec 27, 2024
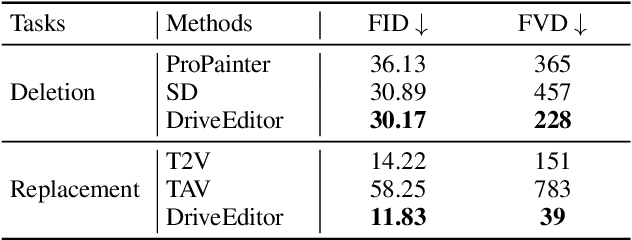
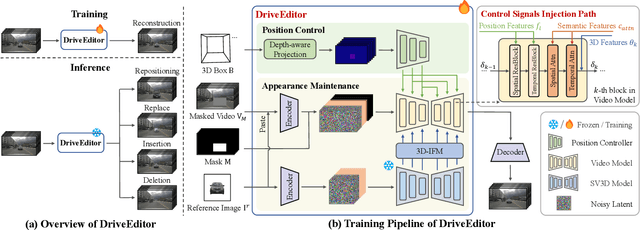
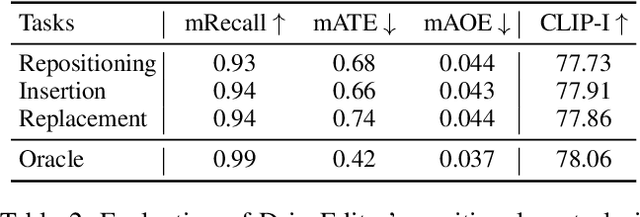
Vision-centric autonomous driving systems require diverse data for robust training and evaluation, which can be augmented by manipulating object positions and appearances within existing scene captures. While recent advancements in diffusion models have shown promise in video editing, their application to object manipulation in driving scenarios remains challenging due to imprecise positional control and difficulties in preserving high-fidelity object appearances. To address these challenges in position and appearance control, we introduce DriveEditor, a diffusion-based framework for object editing in driving videos. DriveEditor offers a unified framework for comprehensive object editing operations, including repositioning, replacement, deletion, and insertion. These diverse manipulations are all achieved through a shared set of varying inputs, processed by identical position control and appearance maintenance modules. The position control module projects the given 3D bounding box while preserving depth information and hierarchically injects it into the diffusion process, enabling precise control over object position and orientation. The appearance maintenance module preserves consistent attributes with a single reference image by employing a three-tiered approach: low-level detail preservation, high-level semantic maintenance, and the integration of 3D priors from a novel view synthesis model. Extensive qualitative and quantitative evaluations on the nuScenes dataset demonstrate DriveEditor's exceptional fidelity and controllability in generating diverse driving scene edits, as well as its remarkable ability to facilitate downstream tasks.
Perceptual-Distortion Balanced Image Super-Resolution is a Multi-Objective Optimization Problem
Sep 05, 2024Training Single-Image Super-Resolution (SISR) models using pixel-based regression losses can achieve high distortion metrics scores (e.g., PSNR and SSIM), but often results in blurry images due to insufficient recovery of high-frequency details. Conversely, using GAN or perceptual losses can produce sharp images with high perceptual metric scores (e.g., LPIPS), but may introduce artifacts and incorrect textures. Balancing these two types of losses can help achieve a trade-off between distortion and perception, but the challenge lies in tuning the loss function weights. To address this issue, we propose a novel method that incorporates Multi-Objective Optimization (MOO) into the training process of SISR models to balance perceptual quality and distortion. We conceptualize the relationship between loss weights and image quality assessment (IQA) metrics as black-box objective functions to be optimized within our Multi-Objective Bayesian Optimization Super-Resolution (MOBOSR) framework. This approach automates the hyperparameter tuning process, reduces overall computational cost, and enables the use of numerous loss functions simultaneously. Extensive experiments demonstrate that MOBOSR outperforms state-of-the-art methods in terms of both perceptual quality and distortion, significantly advancing the perception-distortion Pareto frontier. Our work points towards a new direction for future research on balancing perceptual quality and fidelity in nearly all image restoration tasks. The source code and pretrained models are available at: https://github.com/ZhuKeven/MOBOSR.
Powerful Lossy Compression for Noisy Images
Mar 26, 2024Image compression and denoising represent fundamental challenges in image processing with many real-world applications. To address practical demands, current solutions can be categorized into two main strategies: 1) sequential method; and 2) joint method. However, sequential methods have the disadvantage of error accumulation as there is information loss between multiple individual models. Recently, the academic community began to make some attempts to tackle this problem through end-to-end joint methods. Most of them ignore that different regions of noisy images have different characteristics. To solve these problems, in this paper, our proposed signal-to-noise ratio~(SNR) aware joint solution exploits local and non-local features for image compression and denoising simultaneously. We design an end-to-end trainable network, which includes the main encoder branch, the guidance branch, and the signal-to-noise ratio~(SNR) aware branch. We conducted extensive experiments on both synthetic and real-world datasets, demonstrating that our joint solution outperforms existing state-of-the-art methods.
Jointly Optimizing Image Compression with Low-light Image Enhancement
May 24, 2023
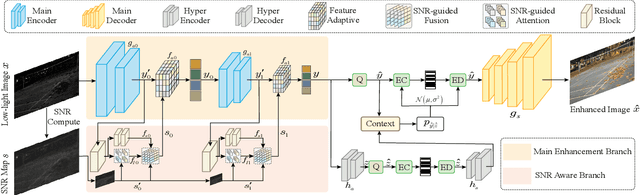
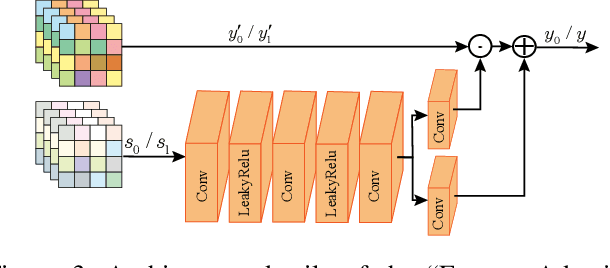
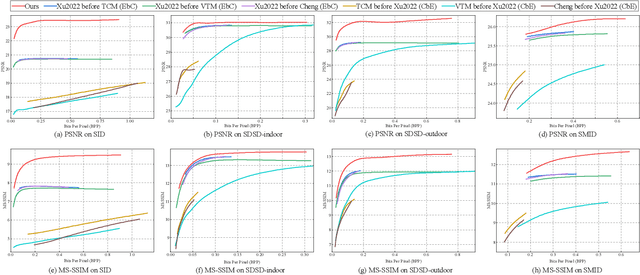
Learning-based image compression methods have made great progress. Most of them are designed for generic natural images. In fact, low-light images frequently occur due to unavoidable environmental influences or technical limitations, such as insufficient lighting or limited exposure time. %When general-purpose image compression algorithms compress low-light images, useful detail information is lost, resulting in a dramatic decrease in image enhancement. Once low-light images are compressed by existing general image compression approaches, useful information(e.g., texture details) would be lost resulting in a dramatic performance decrease in low-light image enhancement. To simultaneously achieve a higher compression rate and better enhancement performance for low-light images, we propose a novel image compression framework with joint optimization of low-light image enhancement. We design an end-to-end trainable two-branch architecture with lower computational cost, which includes the main enhancement branch and the signal-to-noise ratio~(SNR) aware branch. Experimental results show that our proposed joint optimization framework achieves a significant improvement over existing ``Compress before Enhance" or ``Enhance before Compress" sequential solutions for low-light images. Source codes are included in the supplementary material.
Understanding and Constructing Latent Modality Structures in Multi-modal Representation Learning
Mar 10, 2023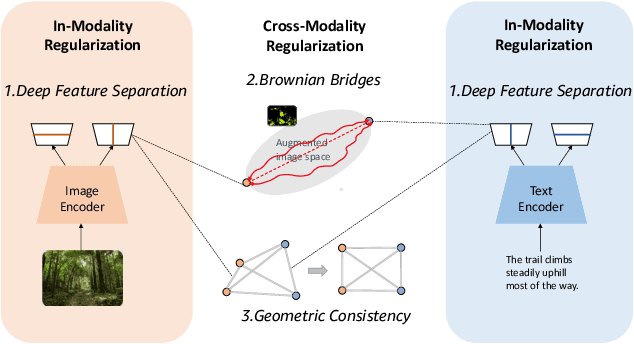
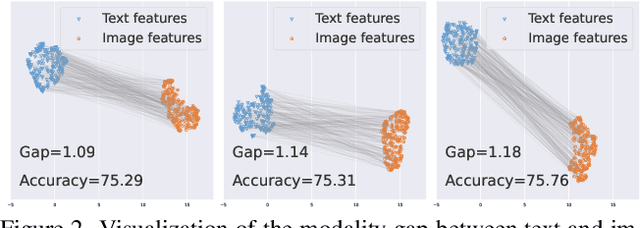
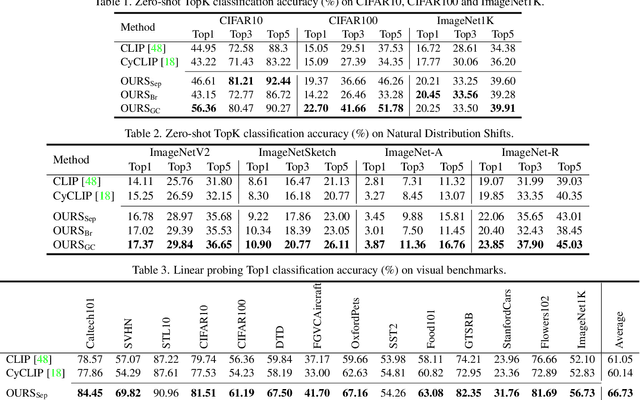
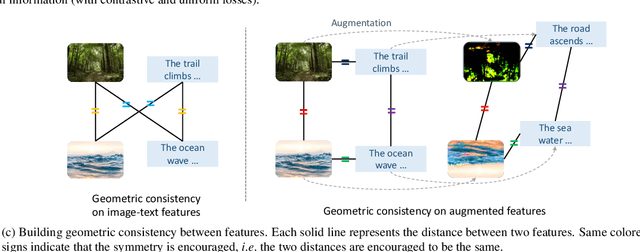
Contrastive loss has been increasingly used in learning representations from multiple modalities. In the limit, the nature of the contrastive loss encourages modalities to exactly match each other in the latent space. Yet it remains an open question how the modality alignment affects the downstream task performance. In this paper, based on an information-theoretic argument, we first prove that exact modality alignment is sub-optimal in general for downstream prediction tasks. Hence we advocate that the key of better performance lies in meaningful latent modality structures instead of perfect modality alignment. To this end, we propose three general approaches to construct latent modality structures. Specifically, we design 1) a deep feature separation loss for intra-modality regularization; 2) a Brownian-bridge loss for inter-modality regularization; and 3) a geometric consistency loss for both intra- and inter-modality regularization. Extensive experiments are conducted on two popular multi-modal representation learning frameworks: the CLIP-based two-tower model and the ALBEF-based fusion model. We test our model on a variety of tasks including zero/few-shot image classification, image-text retrieval, visual question answering, visual reasoning, and visual entailment. Our method achieves consistent improvements over existing methods, demonstrating the effectiveness and generalizability of our proposed approach on latent modality structure regularization.
High-Fidelity Variable-Rate Image Compression via Invertible Activation Transformation
Sep 12, 2022
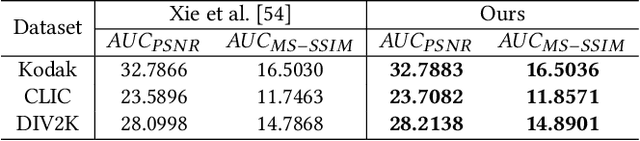
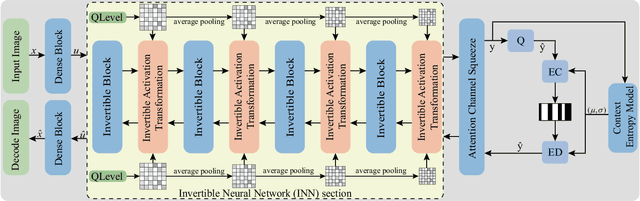
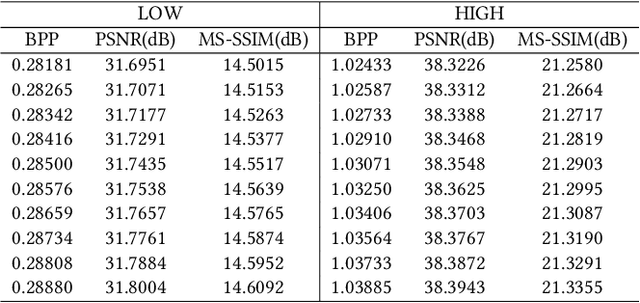
Learning-based methods have effectively promoted the community of image compression. Meanwhile, variational autoencoder (VAE) based variable-rate approaches have recently gained much attention to avoid the usage of a set of different networks for various compression rates. Despite the remarkable performance that has been achieved, these approaches would be readily corrupted once multiple compression/decompression operations are executed, resulting in the fact that image quality would be tremendously dropped and strong artifacts would appear. Thus, we try to tackle the issue of high-fidelity fine variable-rate image compression and propose the Invertible Activation Transformation (IAT) module. We implement the IAT in a mathematical invertible manner on a single rate Invertible Neural Network (INN) based model and the quality level (QLevel) would be fed into the IAT to generate scaling and bias tensors. IAT and QLevel together give the image compression model the ability of fine variable-rate control while better maintaining the image fidelity. Extensive experiments demonstrate that the single rate image compression model equipped with our IAT module has the ability to achieve variable-rate control without any compromise. And our IAT-embedded model obtains comparable rate-distortion performance with recent learning-based image compression methods. Furthermore, our method outperforms the state-of-the-art variable-rate image compression method by a large margin, especially after multiple re-encodings.
Vision-Language Pre-Training with Triple Contrastive Learning
Mar 28, 2022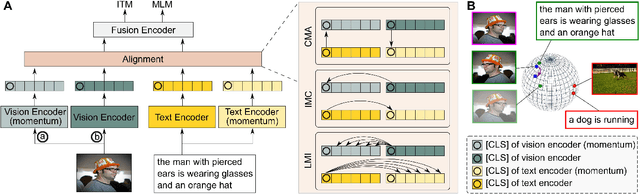

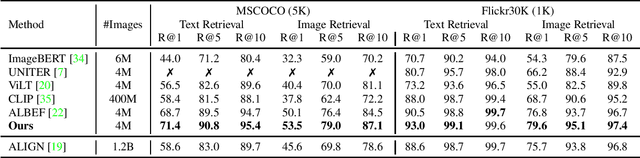
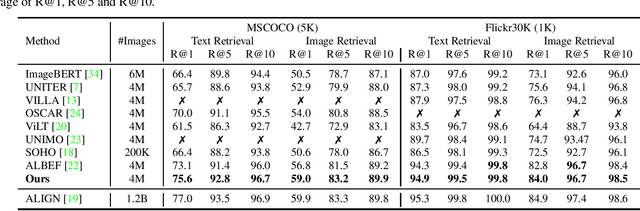
Vision-language representation learning largely benefits from image-text alignment through contrastive losses (e.g., InfoNCE loss). The success of this alignment strategy is attributed to its capability in maximizing the mutual information (MI) between an image and its matched text. However, simply performing cross-modal alignment (CMA) ignores data potential within each modality, which may result in degraded representations. For instance, although CMA-based models are able to map image-text pairs close together in the embedding space, they fail to ensure that similar inputs from the same modality stay close by. This problem can get even worse when the pre-training data is noisy. In this paper, we propose triple contrastive learning (TCL) for vision-language pre-training by leveraging both cross-modal and intra-modal self-supervision. Besides CMA, TCL introduces an intra-modal contrastive objective to provide complementary benefits in representation learning. To take advantage of localized and structural information from image and text input, TCL further maximizes the average MI between local regions of image/text and their global summary. To the best of our knowledge, ours is the first work that takes into account local structure information for multi-modality representation learning. Experimental evaluations show that our approach is competitive and achieves the new state of the art on various common down-stream vision-language tasks such as image-text retrieval and visual question answering.