 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeVision-Language Pre-Training with Triple Contrastive Learning
Mar 28, 2022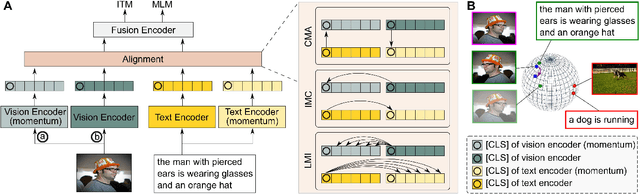

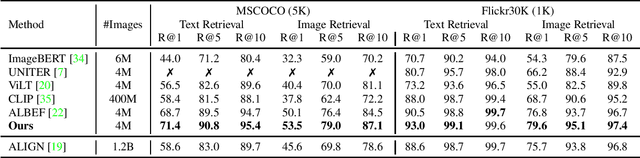
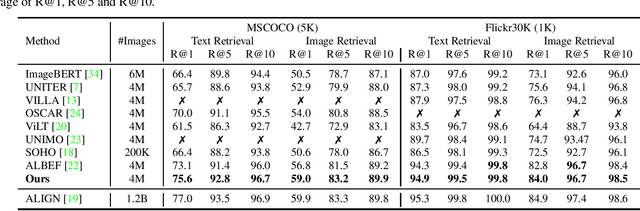
Vision-language representation learning largely benefits from image-text alignment through contrastive losses (e.g., InfoNCE loss). The success of this alignment strategy is attributed to its capability in maximizing the mutual information (MI) between an image and its matched text. However, simply performing cross-modal alignment (CMA) ignores data potential within each modality, which may result in degraded representations. For instance, although CMA-based models are able to map image-text pairs close together in the embedding space, they fail to ensure that similar inputs from the same modality stay close by. This problem can get even worse when the pre-training data is noisy. In this paper, we propose triple contrastive learning (TCL) for vision-language pre-training by leveraging both cross-modal and intra-modal self-supervision. Besides CMA, TCL introduces an intra-modal contrastive objective to provide complementary benefits in representation learning. To take advantage of localized and structural information from image and text input, TCL further maximizes the average MI between local regions of image/text and their global summary. To the best of our knowledge, ours is the first work that takes into account local structure information for multi-modality representation learning. Experimental evaluations show that our approach is competitive and achieves the new state of the art on various common down-stream vision-language tasks such as image-text retrieval and visual question answering.
Improving Apparel Detection with Category Grouping and Multi-grained Branches
Jan 17, 2021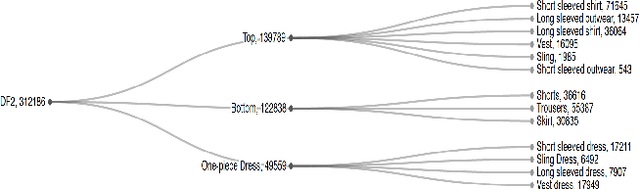
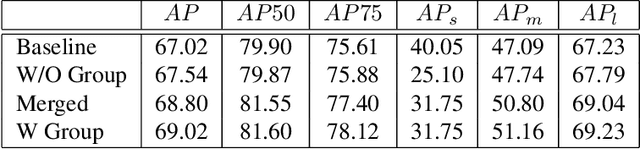
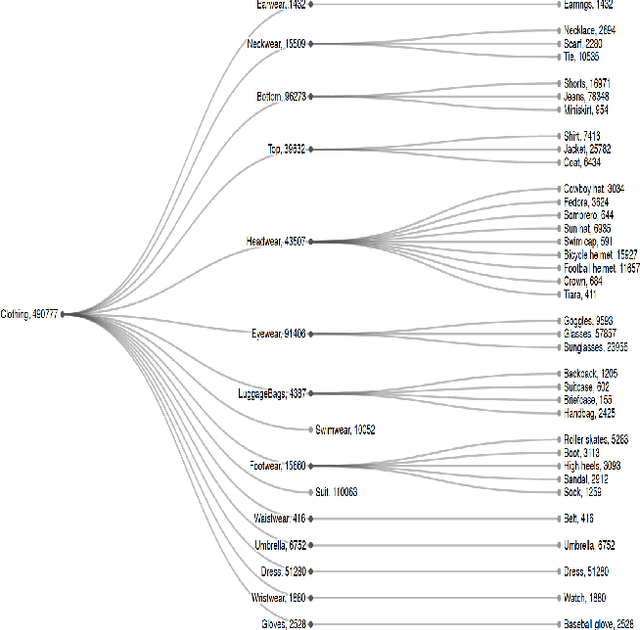
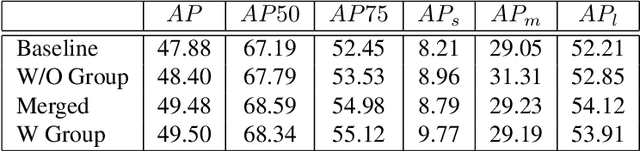
Training an accurate object detector is expensive and time-consuming. One main reason lies in the laborious labeling process, i.e., annotating category and bounding box information for all instances in every image. In this paper, we examine ways to improve performance of deep object detectors without extra labeling. We first explore to group existing categories of high visual and semantic similarities together as one super category (or, a superclass). Then, we study how this knowledge of hierarchical categories can be exploited to better detect object using multi-grained RCNN top branches. Experimental results on DeepFashion2 and OpenImagesV4-Clothing reveal that the proposed detection heads with multi-grained branches can boost the overall performance by 2.3 mAP for DeepFashion2 and 2.5 mAP for OpenImagesV4-Clothing with no additional time-consuming annotations. More importantly, classes that have fewer training samples tend to benefit more from the proposed multi-grained heads with superclass grouping. In particular, we improve the mAP for last 30% categories (in terms of training sample number) by 2.6 and 4.6 for DeepFashion2 and OpenImagesV4-Clothing, respectively.
Searching for Apparel Products from Images in the Wild
Jul 04, 2019

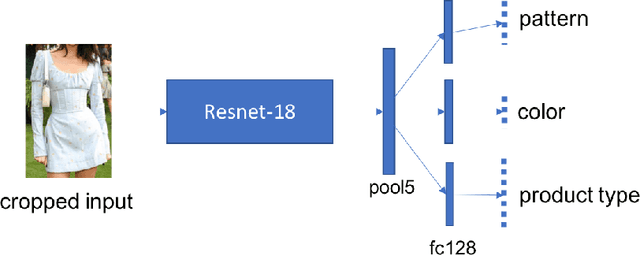
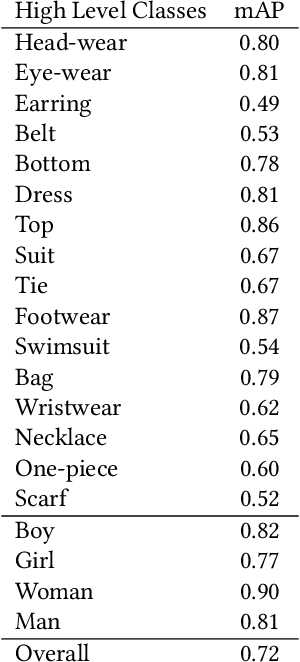
In this age of social media, people often look at what others are wearing. In particular, Instagram and Twitter influencers often provide images of themselves wearing different outfits and their followers are often inspired to buy similar clothes.We propose a system to automatically find the closest visually similar clothes in the online Catalog (street-to-shop searching). The problem is challenging since the original images are taken under different pose and lighting conditions. The system initially localizes high-level descriptive regions (top, bottom, wristwear. . . ) using multiple CNN detectors such as YOLO and SSD that are trained specifically for apparel domain. It then classifies these regions into more specific regions such as t-shirts, tunic or dresses. Finally, a feature embedding learned using a multi-task function is recovered for every item and then compared with corresponding items in the online Catalog database and ranked according to distance. We validate our approach component-wise using benchmark datasets and end-to-end using human evaluation.