 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMulti-modal Alignment using Representation Codebook
Paper and Code
Mar 28, 2022
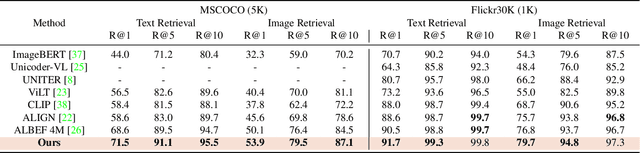

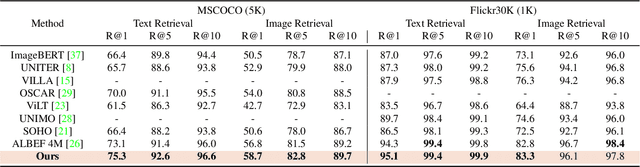
Aligning signals from different modalities is an important step in vision-language representation learning as it affects the performance of later stages such as cross-modality fusion. Since image and text typically reside in different regions of the feature space, directly aligning them at instance level is challenging especially when features are still evolving during training. In this paper, we propose to align at a higher and more stable level using cluster representation. Specifically, we treat image and text as two "views" of the same entity, and encode them into a joint vision-language coding space spanned by a dictionary of cluster centers (codebook). We contrast positive and negative samples via their cluster assignments while simultaneously optimizing the cluster centers. To further smooth out the learning process, we adopt a teacher-student distillation paradigm, where the momentum teacher of one view guides the student learning of the other. We evaluated our approach on common vision language benchmarks and obtain new SoTA on zero-shot cross modality retrieval while being competitive on various other transfer tasks.