 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTextAlign: Preference Alignment for Text Rendering with Hierarchical Rewards
May 19, 2026Faithful text rendering remains a persistent weakness of large text-to-image generative models, as it requires both semantic instruction following and fine-grained glyph-level structure. Prior methods often improve this ability through architecture-specific modules or encoder modifications, which complicate deployment across foundation models. We study text rendering as a post-training preference-alignment problem and propose TextAlign, a non-invasive framework that keeps the generator architecture unchanged. The key component is a hierarchical vision-language model (VLM)-based reward that decomposes rendering errors into global, word, and glyph levels, then converts binary defect judgments into a scalar preference signal. The resulting signal supports both Group Relative Policy Optimization (GRPO) and Direct Preference Optimization (DPO). Experiments on FLUX.1-dev and Z-Image-Turbo show consistent gains in OCR-based text accuracy without degrading general generation quality. Compared with strong foundation and text-rendering baselines, including SD3.5, Qwen-Image, AnyText, and TextDiffuser, these results indicate that reward design offers a scalable alternative to model redesign for improving text rendering.
OmniFood8K: Single-Image Nutrition Estimation via Hierarchical Frequency-Aligned Fusion
Apr 14, 2026Accurate estimation of food nutrition plays a vital role in promoting healthy dietary habits and personalized diet management. Most existing food datasets primarily focus on Western cuisines and lack sufficient coverage of Chinese dishes, which restricts accurate nutritional estimation for Chinese meals. Moreover, many state-of-the-art nutrition prediction methods rely on depth sensors, restricting their applicability in daily scenarios. To address these limitations, we introduce OmniFood8K, a comprehensive multimodal dataset comprising 8,036 food samples, each with detailed nutritional annotations and multi-view images. In addition, to enhance models' capability in nutritional prediction, we construct NutritionSynth-115K, a large-scale synthetic dataset that introduces compositional variations while preserving precise nutritional labels. Moreover, we propose an end-to-end framework for nutritional prediction from a single RGB image. First, we predict a depth map from a single RGB image and design the Scale-Shift Residual Adapter (SSRA) to refine it for global scale consistency and local structural preservation. Second, we propose the Frequency-Aligned Fusion Module (FAFM) to hierarchically align and fuse RGB and depth features in the frequency domain. Finally, we design a Mask-based Prediction Head (MPH) to emphasize key ingredient regions via dynamic channel selection for more accurate prediction. Extensive experiments on multiple datasets demonstrate the superiority of our method over existing approaches. Project homepage: https://yudongjian.github.io/OmniFood8K-food/
Intern-S1-Pro: Scientific Multimodal Foundation Model at Trillion Scale
Mar 26, 2026We introduce Intern-S1-Pro, the first one-trillion-parameter scientific multimodal foundation model. Scaling to this unprecedented size, the model delivers a comprehensive enhancement across both general and scientific domains. Beyond stronger reasoning and image-text understanding capabilities, its intelligence is augmented with advanced agent capabilities. Simultaneously, its scientific expertise has been vastly expanded to master over 100 specialized tasks across critical science fields, including chemistry, materials, life sciences, and earth sciences. Achieving this massive scale is made possible by the robust infrastructure support of XTuner and LMDeploy, which facilitates highly efficient Reinforcement Learning (RL) training at the 1-trillion parameter level while ensuring strict precision consistency between training and inference. By seamlessly integrating these advancements, Intern-S1-Pro further fortifies the fusion of general and specialized intelligence, working as a Specializable Generalist, demonstrating its position in the top tier of open-source models for general capabilities, while outperforming proprietary models in the depth of specialized scientific tasks.
RynnBrain: Open Embodied Foundation Models
Feb 13, 2026Despite rapid progress in multimodal foundation models, embodied intelligence community still lacks a unified, physically grounded foundation model that integrates perception, reasoning, and planning within real-world spatial-temporal dynamics. We introduce RynnBrain, an open-source spatiotemporal foundation model for embodied intelligence. RynnBrain strengthens four core capabilities in a unified framework: comprehensive egocentric understanding, diverse spatiotemporal localization, physically grounded reasoning, and physics-aware planning. The RynnBrain family comprises three foundation model scales (2B, 8B, and 30B-A3B MoE) and four post-trained variants tailored for downstream embodied tasks (i.e., RynnBrain-Nav, RynnBrain-Plan, and RynnBrain-VLA) or complex spatial reasoning tasks (i.e., RynnBrain-CoP). In terms of extensive evaluations on 20 embodied benchmarks and 8 general vision understanding benchmarks, our RynnBrain foundation models largely outperform existing embodied foundation models by a significant margin. The post-trained model suite further substantiates two key potentials of the RynnBrain foundation model: (i) enabling physically grounded reasoning and planning, and (ii) serving as a strong pretrained backbone that can be efficiently adapted to diverse embodied tasks.
ManipLVM-R1: Reinforcement Learning for Reasoning in Embodied Manipulation with Large Vision-Language Models
May 22, 2025Large Vision-Language Models (LVLMs) have recently advanced robotic manipulation by leveraging vision for scene perception and language for instruction following. However, existing methods rely heavily on costly human-annotated training datasets, which limits their generalization and causes them to struggle in out-of-domain (OOD) scenarios, reducing real-world adaptability. To address these challenges, we propose ManipLVM-R1, a novel reinforcement learning framework that replaces traditional supervision with Reinforcement Learning using Verifiable Rewards (RLVR). By directly optimizing for task-aligned outcomes, our method enhances generalization and physical reasoning while removing the dependence on costly annotations. Specifically, we design two rule-based reward functions targeting key robotic manipulation subtasks: an Affordance Perception Reward to enhance localization of interaction regions, and a Trajectory Match Reward to ensure the physical plausibility of action paths. These rewards provide immediate feedback and impose spatial-logical constraints, encouraging the model to go beyond shallow pattern matching and instead learn deeper, more systematic reasoning about physical interactions.
Audio Jailbreak: An Open Comprehensive Benchmark for Jailbreaking Large Audio-Language Models
May 21, 2025



The rise of Large Audio Language Models (LAMs) brings both potential and risks, as their audio outputs may contain harmful or unethical content. However, current research lacks a systematic, quantitative evaluation of LAM safety especially against jailbreak attacks, which are challenging due to the temporal and semantic nature of speech. To bridge this gap, we introduce AJailBench, the first benchmark specifically designed to evaluate jailbreak vulnerabilities in LAMs. We begin by constructing AJailBench-Base, a dataset of 1,495 adversarial audio prompts spanning 10 policy-violating categories, converted from textual jailbreak attacks using realistic text to speech synthesis. Using this dataset, we evaluate several state-of-the-art LAMs and reveal that none exhibit consistent robustness across attacks. To further strengthen jailbreak testing and simulate more realistic attack conditions, we propose a method to generate dynamic adversarial variants. Our Audio Perturbation Toolkit (APT) applies targeted distortions across time, frequency, and amplitude domains. To preserve the original jailbreak intent, we enforce a semantic consistency constraint and employ Bayesian optimization to efficiently search for perturbations that are both subtle and highly effective. This results in AJailBench-APT, an extended dataset of optimized adversarial audio samples. Our findings demonstrate that even small, semantically preserved perturbations can significantly reduce the safety performance of leading LAMs, underscoring the need for more robust and semantically aware defense mechanisms.
A Haptic-Based Proximity Sensing System for Buried Object in Granular Material
Nov 26, 2024



The proximity perception of objects in granular materials is significant, especially for applications like minesweeping. However, due to particles' opacity and complex properties, existing proximity sensors suffer from high costs from sophisticated hardware and high user-cost from unintuitive results. In this paper, we propose a simple yet effective proximity sensing system for underground stuff based on the haptic feedback of the sensor-granules interaction. We study and employ the unique characteristic of particles -- failure wedge zone, and combine the machine learning method -- Gaussian process regression, to identify the force signal changes induced by the proximity of objects, so as to achieve near-field perception. Furthermore, we design a novel trajectory to control the probe searching in granules for a wide range of perception. Also, our proximity sensing system can adaptively determine optimal parameters for robustness operation in different particles. Experiments demonstrate our system can perceive underground objects over 0.5 to 7 cm in advance among various materials.
Federated Recommendation via Hybrid Retrieval Augmented Generation
Mar 07, 2024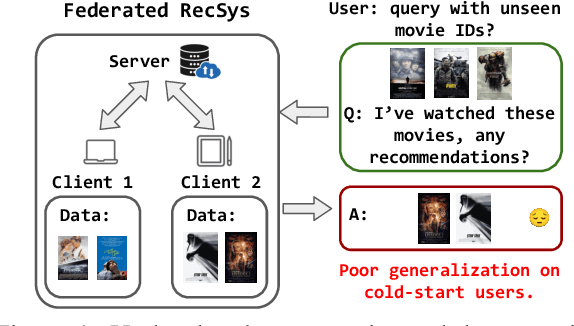
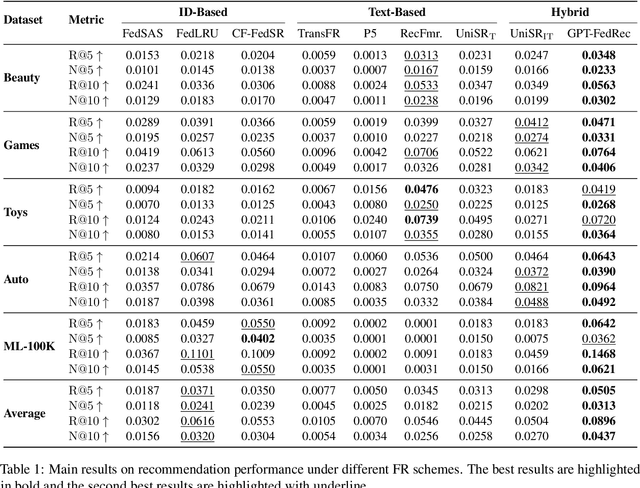
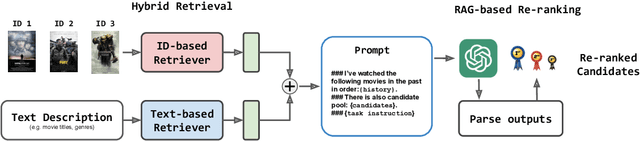
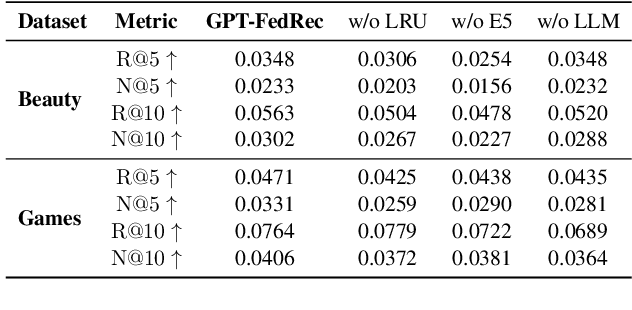
Federated Recommendation (FR) emerges as a novel paradigm that enables privacy-preserving recommendations. However, traditional FR systems usually represent users/items with discrete identities (IDs), suffering from performance degradation due to the data sparsity and heterogeneity in FR. On the other hand, Large Language Models (LLMs) as recommenders have proven effective across various recommendation scenarios. Yet, LLM-based recommenders encounter challenges such as low inference efficiency and potential hallucination, compromising their performance in real-world scenarios. To this end, we propose GPT-FedRec, a federated recommendation framework leveraging ChatGPT and a novel hybrid Retrieval Augmented Generation (RAG) mechanism. GPT-FedRec is a two-stage solution. The first stage is a hybrid retrieval process, mining ID-based user patterns and text-based item features. Next, the retrieved results are converted into text prompts and fed into GPT for re-ranking. Our proposed hybrid retrieval mechanism and LLM-based re-rank aims to extract generalized features from data and exploit pretrained knowledge within LLM, overcoming data sparsity and heterogeneity in FR. In addition, the RAG approach also prevents LLM hallucination, improving the recommendation performance for real-world users. Experimental results on diverse benchmark datasets demonstrate the superior performance of GPT-FedRec against state-of-the-art baseline methods.
GRAINS: Proximity Sensing of Objects in Granular Materials
Jul 18, 2023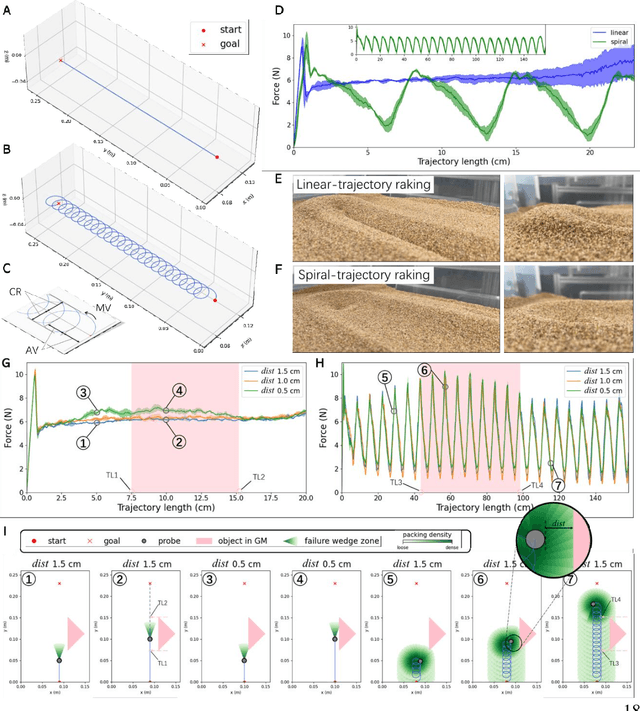
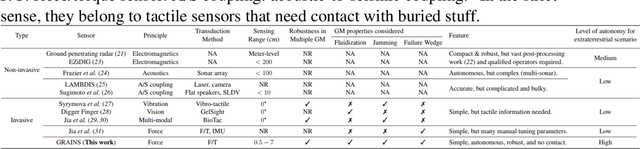
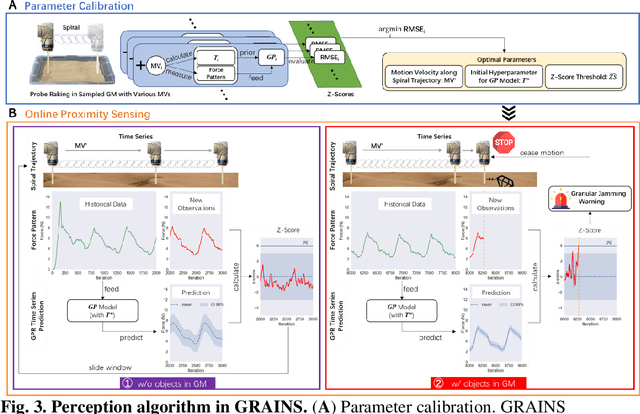
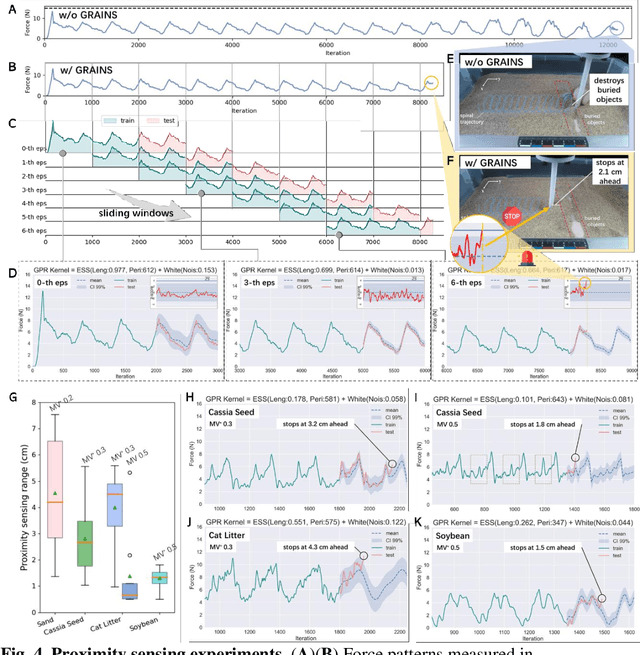
Proximity sensing detects an object's presence without contact. However, research has rarely explored proximity sensing in granular materials (GM) due to GM's lack of visual and complex properties. In this paper, we propose a granular-material-embedded autonomous proximity sensing system (GRAINS) based on three granular phenomena (fluidization, jamming, and failure wedge zone). GRAINS can automatically sense buried objects beneath GM in real-time manner (at least ~20 hertz) and perceive them 0.5 ~ 7 centimeters ahead in different granules without the use of vision or touch. We introduce a new spiral trajectory for the probe raking in GM, combining linear and circular motions, inspired by a common granular fluidization technique. Based on the observation of force-raising when granular jamming occurs in the failure wedge zone in front of the probe during its raking, we employ Gaussian process regression to constantly learn and predict the force patterns and detect the force anomaly resulting from granular jamming to identify the proximity sensing of buried objects. Finally, we apply GRAINS to a Bayesian-optimization-algorithm-guided exploration strategy to successfully localize underground objects and outline their distribution using proximity sensing without contact or digging. This work offers a simple yet reliable method with potential for safe operation in building habitation infrastructure on an alien planet without human intervention.
Understanding and Constructing Latent Modality Structures in Multi-modal Representation Learning
Mar 10, 2023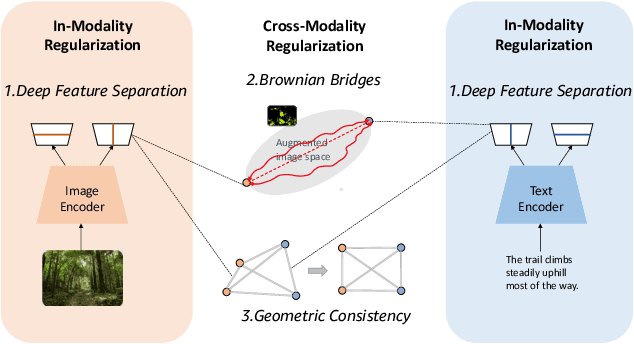
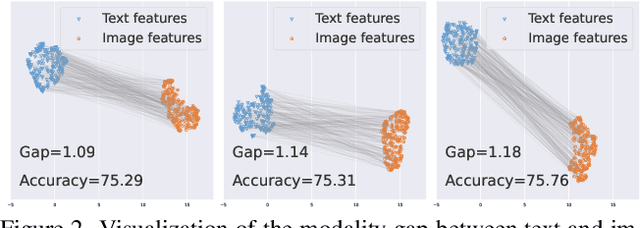
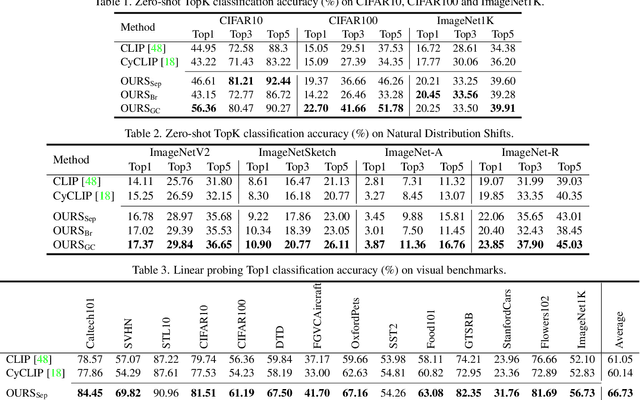
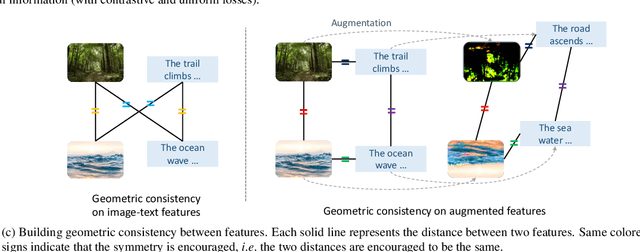
Contrastive loss has been increasingly used in learning representations from multiple modalities. In the limit, the nature of the contrastive loss encourages modalities to exactly match each other in the latent space. Yet it remains an open question how the modality alignment affects the downstream task performance. In this paper, based on an information-theoretic argument, we first prove that exact modality alignment is sub-optimal in general for downstream prediction tasks. Hence we advocate that the key of better performance lies in meaningful latent modality structures instead of perfect modality alignment. To this end, we propose three general approaches to construct latent modality structures. Specifically, we design 1) a deep feature separation loss for intra-modality regularization; 2) a Brownian-bridge loss for inter-modality regularization; and 3) a geometric consistency loss for both intra- and inter-modality regularization. Extensive experiments are conducted on two popular multi-modal representation learning frameworks: the CLIP-based two-tower model and the ALBEF-based fusion model. We test our model on a variety of tasks including zero/few-shot image classification, image-text retrieval, visual question answering, visual reasoning, and visual entailment. Our method achieves consistent improvements over existing methods, demonstrating the effectiveness and generalizability of our proposed approach on latent modality structure regularization.