 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSwarm Learning: A Survey of Concepts, Applications, and Trends
May 01, 2024



Deep learning models have raised privacy and security concerns due to their reliance on large datasets on central servers. As the number of Internet of Things (IoT) devices increases, artificial intelligence (AI) will be crucial for resource management, data processing, and knowledge acquisition. To address those issues, federated learning (FL) has introduced a novel approach to building a versatile, large-scale machine learning framework that operates in a decentralized and hardware-agnostic manner. However, FL faces network bandwidth limitations and data breaches. To reduce the central dependency in FL and increase scalability, swarm learning (SL) has been proposed in collaboration with Hewlett Packard Enterprise (HPE). SL represents a decentralized machine learning framework that leverages blockchain technology for secure, scalable, and private data management. A blockchain-based network enables the exchange and aggregation of model parameters among participants, thus mitigating the risk of a single point of failure and eliminating communication bottlenecks. To the best of our knowledge, this survey is the first to introduce the principles of Swarm Learning, its architectural design, and its fields of application. In addition, it highlights numerous research avenues that require further exploration by academic and industry communities to unlock the full potential and applications of SL.
Evaluating Open-Domain Dialogues in Latent Space with Next Sentence Prediction and Mutual Information
Jun 10, 2023The long-standing one-to-many issue of the open-domain dialogues poses significant challenges for automatic evaluation methods, i.e., there may be multiple suitable responses which differ in semantics for a given conversational context. To tackle this challenge, we propose a novel learning-based automatic evaluation metric (CMN), which can robustly evaluate open-domain dialogues by augmenting Conditional Variational Autoencoders (CVAEs) with a Next Sentence Prediction (NSP) objective and employing Mutual Information (MI) to model the semantic similarity of text in the latent space. Experimental results on two open-domain dialogue datasets demonstrate the superiority of our method compared with a wide range of baselines, especially in handling responses which are distant to the golden reference responses in semantics.
MC-LCR: Multi-modal contrastive classification by locally correlated representations for effective face forgery detection
Oct 07, 2021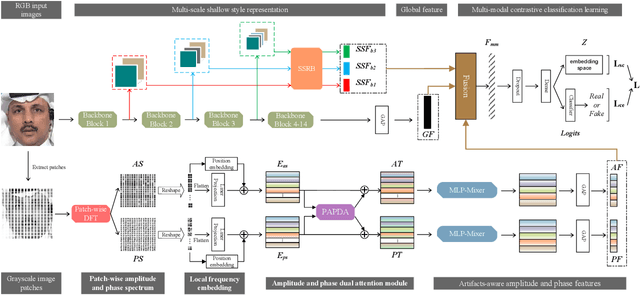

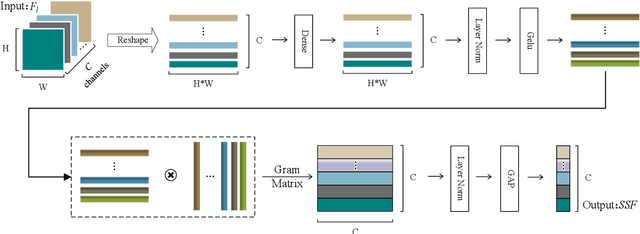
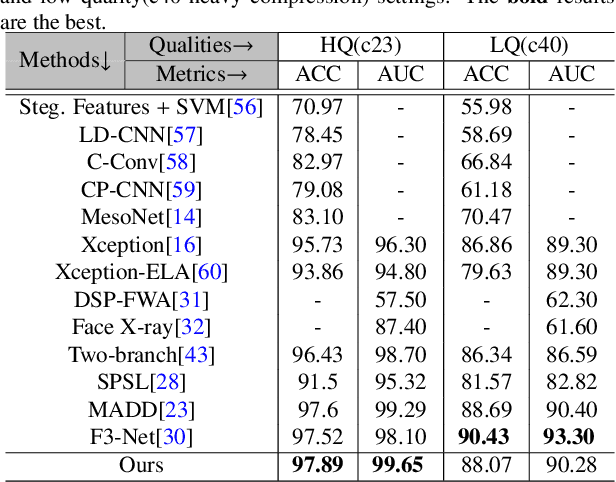
As the remarkable development of facial manipulation technologies is accompanied by severe security concerns, face forgery detection has become a recent research hotspot. Most existing detection methods train a binary classifier under global supervision to judge real or fake. However, advanced manipulations only perform small-scale tampering, posing challenges to comprehensively capture subtle and local forgery artifacts, especially in high compression settings and cross-dataset scenarios. To address such limitations, we propose a novel framework named Multi-modal Contrastive Classification by Locally Correlated Representations(MC-LCR), for effective face forgery detection. Instead of specific appearance features, our MC-LCR aims to amplify implicit local discrepancies between authentic and forged faces from both spatial and frequency domains. Specifically, we design the shallow style representation block that measures the pairwise correlation of shallow feature maps, which encodes local style information to extract more discriminative features in the spatial domain. Moreover, we make a key observation that subtle forgery artifacts can be further exposed in the patch-wise phase and amplitude spectrum and exhibit different clues. According to the complementarity of amplitude and phase information, we develop a patch-wise amplitude and phase dual attention module to capture locally correlated inconsistencies with each other in the frequency domain. Besides the above two modules, we further introduce the collaboration of supervised contrastive loss with cross-entropy loss. It helps the network learn more discriminative and generalized representations. Through extensive experiments and comprehensive studies, we achieve state-of-the-art performance and demonstrate the robustness and generalization of our method.
FFR_FD: Effective and Fast Detection of DeepFakes Based on Feature Point Defects
Jul 05, 2021
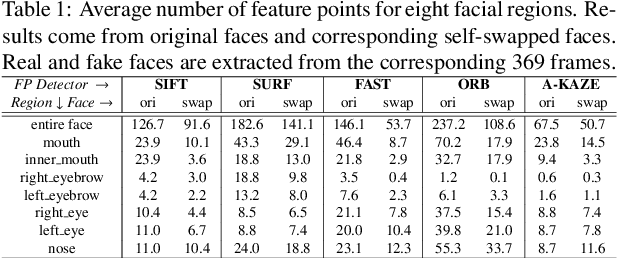
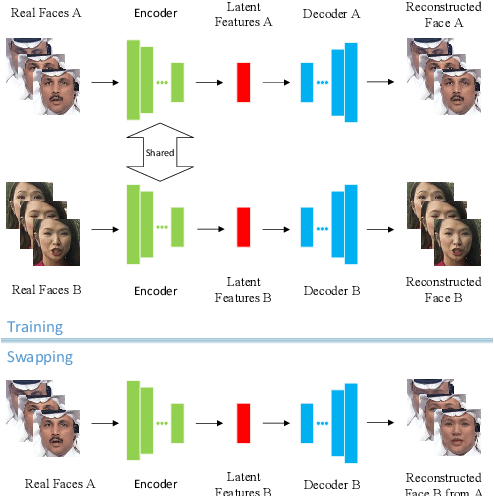
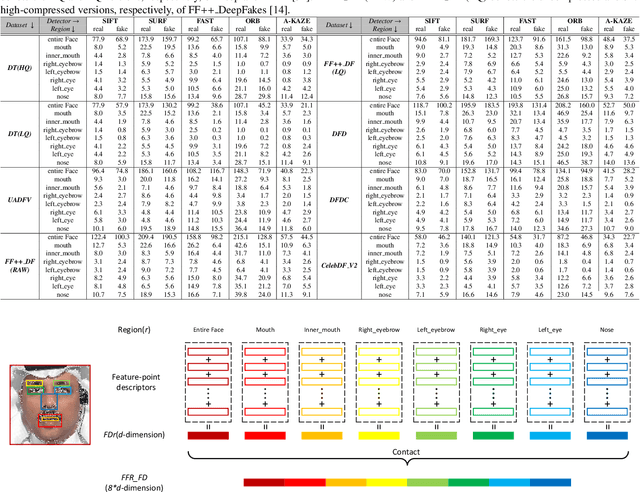
The internet is filled with fake face images and videos synthesized by deep generative models. These realistic DeepFakes pose a challenge to determine the authenticity of multimedia content. As countermeasures, artifact-based detection methods suffer from insufficiently fine-grained features that lead to limited detection performance. DNN-based detection methods are not efficient enough, given that a DeepFake can be created easily by mobile apps and DNN-based models require high computational resources. We show that DeepFake faces have fewer feature points than real ones, especially in certain facial regions. Inspired by feature point detector-descriptors to extract discriminative features at the pixel level, we propose the Fused Facial Region_Feature Descriptor (FFR_FD) for effective and fast DeepFake detection. FFR_FD is only a vector extracted from the face, and it can be constructed from any feature point detector-descriptors. We train a random forest classifier with FFR_FD and conduct extensive experiments on six large-scale DeepFake datasets, whose results demonstrate that our method is superior to most state of the art DNN-based models.