 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFSFM: A Generalizable Face Security Foundation Model via Self-Supervised Facial Representation Learning
Dec 16, 2024This work asks: with abundant, unlabeled real faces, how to learn a robust and transferable facial representation that boosts various face security tasks with respect to generalization performance? We make the first attempt and propose a self-supervised pretraining framework to learn fundamental representations of real face images, FSFM, that leverages the synergy between masked image modeling (MIM) and instance discrimination (ID). We explore various facial masking strategies for MIM and present a simple yet powerful CRFR-P masking, which explicitly forces the model to capture meaningful intra-region consistency and challenging inter-region coherency. Furthermore, we devise the ID network that naturally couples with MIM to establish underlying local-to-global correspondence via tailored self-distillation. These three learning objectives, namely 3C, empower encoding both local features and global semantics of real faces. After pretraining, a vanilla ViT serves as a universal vision foundation model for downstream face security tasks: cross-dataset deepfake detection, cross-domain face anti-spoofing, and unseen diffusion facial forgery detection. Extensive experiments on 10 public datasets demonstrate that our model transfers better than supervised pretraining, visual and facial self-supervised learning arts, and even outperforms task-specialized SOTA methods.
MC-LCR: Multi-modal contrastive classification by locally correlated representations for effective face forgery detection
Oct 07, 2021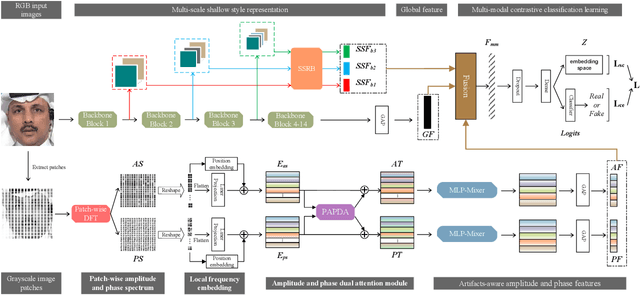

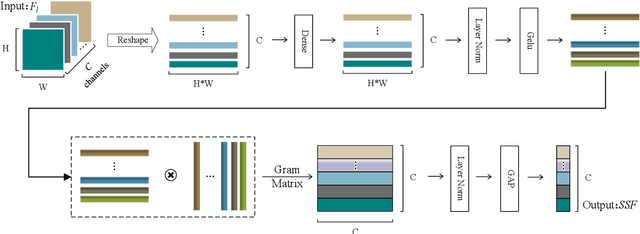
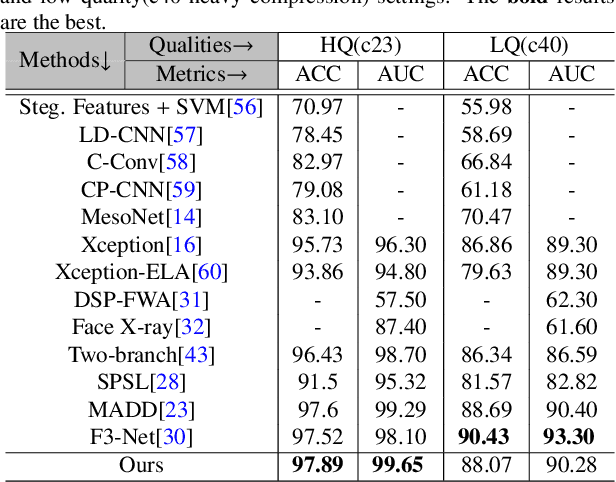
As the remarkable development of facial manipulation technologies is accompanied by severe security concerns, face forgery detection has become a recent research hotspot. Most existing detection methods train a binary classifier under global supervision to judge real or fake. However, advanced manipulations only perform small-scale tampering, posing challenges to comprehensively capture subtle and local forgery artifacts, especially in high compression settings and cross-dataset scenarios. To address such limitations, we propose a novel framework named Multi-modal Contrastive Classification by Locally Correlated Representations(MC-LCR), for effective face forgery detection. Instead of specific appearance features, our MC-LCR aims to amplify implicit local discrepancies between authentic and forged faces from both spatial and frequency domains. Specifically, we design the shallow style representation block that measures the pairwise correlation of shallow feature maps, which encodes local style information to extract more discriminative features in the spatial domain. Moreover, we make a key observation that subtle forgery artifacts can be further exposed in the patch-wise phase and amplitude spectrum and exhibit different clues. According to the complementarity of amplitude and phase information, we develop a patch-wise amplitude and phase dual attention module to capture locally correlated inconsistencies with each other in the frequency domain. Besides the above two modules, we further introduce the collaboration of supervised contrastive loss with cross-entropy loss. It helps the network learn more discriminative and generalized representations. Through extensive experiments and comprehensive studies, we achieve state-of-the-art performance and demonstrate the robustness and generalization of our method.
FFR_FD: Effective and Fast Detection of DeepFakes Based on Feature Point Defects
Jul 05, 2021
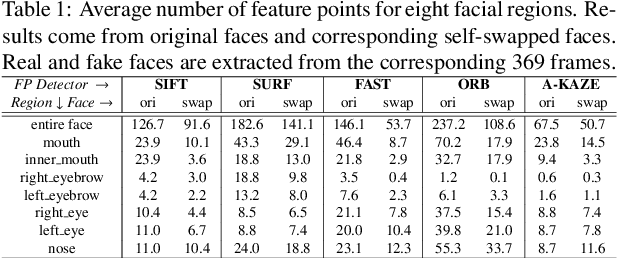
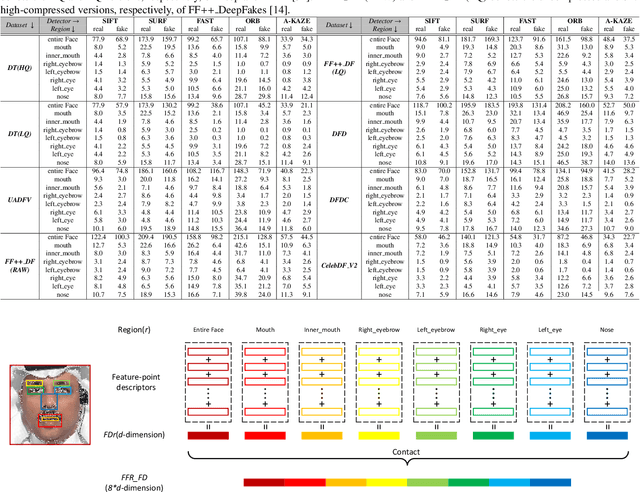
The internet is filled with fake face images and videos synthesized by deep generative models. These realistic DeepFakes pose a challenge to determine the authenticity of multimedia content. As countermeasures, artifact-based detection methods suffer from insufficiently fine-grained features that lead to limited detection performance. DNN-based detection methods are not efficient enough, given that a DeepFake can be created easily by mobile apps and DNN-based models require high computational resources. We show that DeepFake faces have fewer feature points than real ones, especially in certain facial regions. Inspired by feature point detector-descriptors to extract discriminative features at the pixel level, we propose the Fused Facial Region_Feature Descriptor (FFR_FD) for effective and fast DeepFake detection. FFR_FD is only a vector extracted from the face, and it can be constructed from any feature point detector-descriptors. We train a random forest classifier with FFR_FD and conduct extensive experiments on six large-scale DeepFake datasets, whose results demonstrate that our method is superior to most state of the art DNN-based models.