 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMDN: Mamba-Driven Dualstream Network For Medical Hyperspectral Image Segmentation
Feb 24, 2025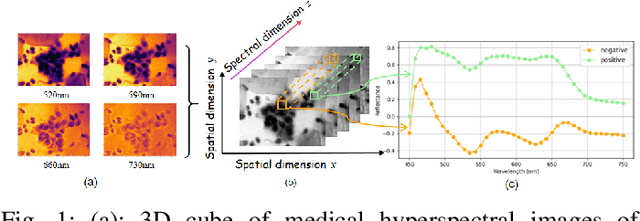
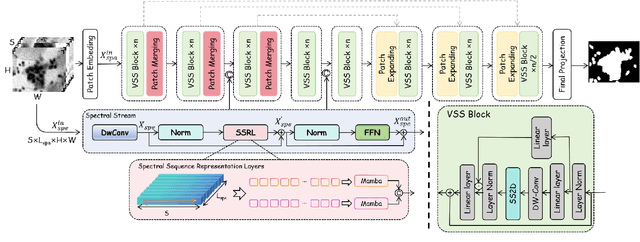
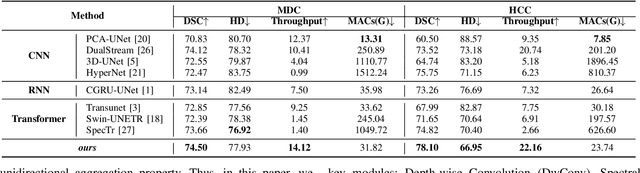
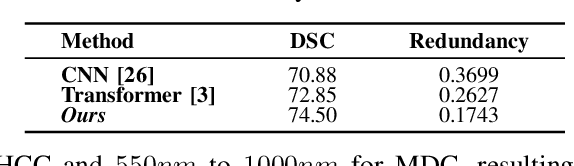
Medical Hyperspectral Imaging (MHSI) offers potential for computational pathology and precision medicine. However, existing CNN and Transformer struggle to balance segmentation accuracy and speed due to high spatial-spectral dimensionality. In this study, we leverage Mamba's global context modeling to propose a dual-stream architecture for joint spatial-spectral feature extraction. To address the limitation of Mamba's unidirectional aggregation, we introduce a recurrent spectral sequence representation to capture low-redundancy global spectral features. Experiments on a public Multi-Dimensional Choledoch dataset and a private Cervical Cancer dataset show that our method outperforms state-of-the-art approaches in segmentation accuracy while minimizing resource usage and achieving the fastest inference speed. Our code will be available at https://github.com/DeepMed-Lab-ECNU/MDN.
A Haptic-Based Proximity Sensing System for Buried Object in Granular Material
Nov 26, 2024



The proximity perception of objects in granular materials is significant, especially for applications like minesweeping. However, due to particles' opacity and complex properties, existing proximity sensors suffer from high costs from sophisticated hardware and high user-cost from unintuitive results. In this paper, we propose a simple yet effective proximity sensing system for underground stuff based on the haptic feedback of the sensor-granules interaction. We study and employ the unique characteristic of particles -- failure wedge zone, and combine the machine learning method -- Gaussian process regression, to identify the force signal changes induced by the proximity of objects, so as to achieve near-field perception. Furthermore, we design a novel trajectory to control the probe searching in granules for a wide range of perception. Also, our proximity sensing system can adaptively determine optimal parameters for robustness operation in different particles. Experiments demonstrate our system can perceive underground objects over 0.5 to 7 cm in advance among various materials.
EROAM: Event-based Camera Rotational Odometry and Mapping in Real-time
Nov 17, 2024This paper presents EROAM, a novel event-based rotational odometry and mapping system that achieves real-time, accurate camera rotation estimation. Unlike existing approaches that rely on event generation models or contrast maximization, EROAM employs a spherical event representation by projecting events onto a unit sphere and introduces Event Spherical Iterative Closest Point (ES-ICP), a novel geometric optimization framework designed specifically for event camera data. The spherical representation simplifies rotational motion formulation while enabling continuous mapping for enhanced spatial resolution. Combined with parallel point-to-line optimization, EROAM achieves efficient computation without compromising accuracy. Extensive experiments on both synthetic and real-world datasets show that EROAM significantly outperforms state-of-the-art methods in terms of accuracy, robustness, and computational efficiency. Our method maintains consistent performance under challenging conditions, including high angular velocities and extended sequences, where other methods often fail or show significant drift. Additionally, EROAM produces high-quality panoramic reconstructions with preserved fine structural details.
NetTrack: Tracking Highly Dynamic Objects with a Net
Mar 17, 2024



The complex dynamicity of open-world objects presents non-negligible challenges for multi-object tracking (MOT), often manifested as severe deformations, fast motion, and occlusions. Most methods that solely depend on coarse-grained object cues, such as boxes and the overall appearance of the object, are susceptible to degradation due to distorted internal relationships of dynamic objects. To address this problem, this work proposes NetTrack, an efficient, generic, and affordable tracking framework to introduce fine-grained learning that is robust to dynamicity. Specifically, NetTrack constructs a dynamicity-aware association with a fine-grained Net, leveraging point-level visual cues. Correspondingly, a fine-grained sampler and matching method have been incorporated. Furthermore, NetTrack learns object-text correspondence for fine-grained localization. To evaluate MOT in extremely dynamic open-world scenarios, a bird flock tracking (BFT) dataset is constructed, which exhibits high dynamicity with diverse species and open-world scenarios. Comprehensive evaluation on BFT validates the effectiveness of fine-grained learning on object dynamicity, and thorough transfer experiments on challenging open-world benchmarks, i.e., TAO, TAO-OW, AnimalTrack, and GMOT-40, validate the strong generalization ability of NetTrack even without finetuning. Project page: https://george-zhuang.github.io/nettrack/.
NeuPAN: Direct Point Robot Navigation with End-to-End Model-based Learning
Mar 11, 2024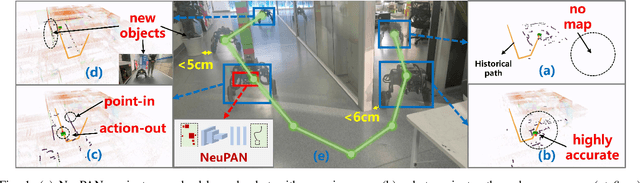

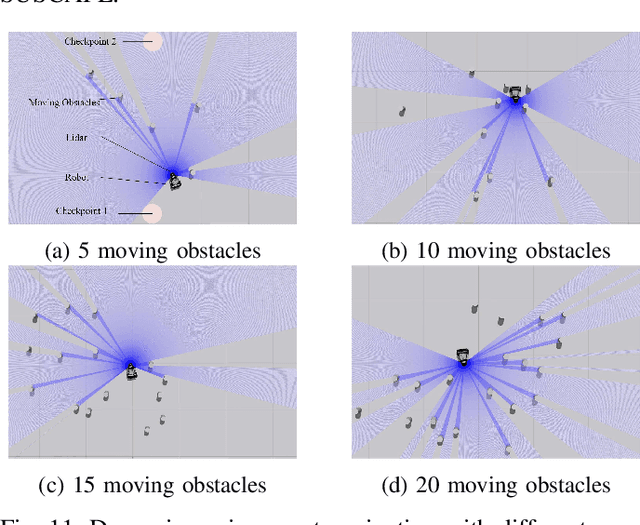
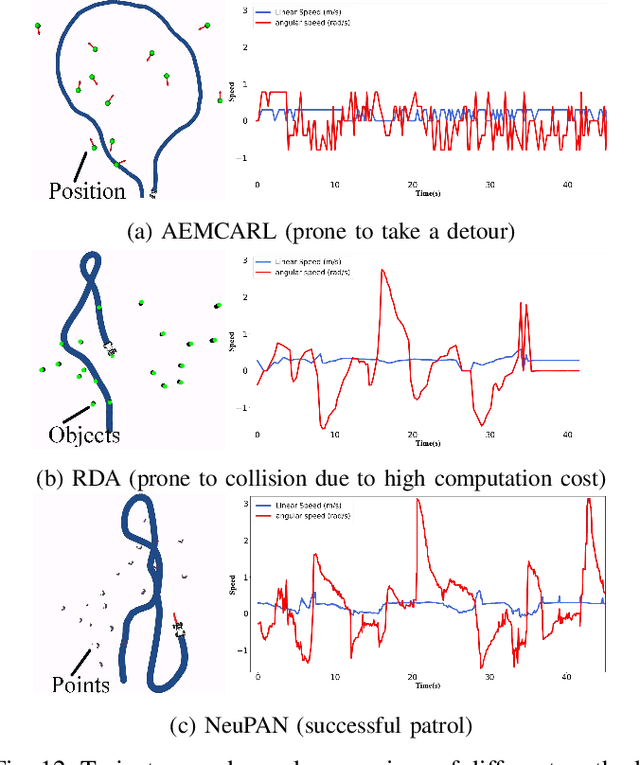
Navigating a nonholonomic robot in a cluttered environment requires extremely accurate perception and locomotion for collision avoidance. This paper presents NeuPAN: a real-time, highly-accurate, map-free, robot-agnostic, and environment-invariant robot navigation solution. Leveraging a tightly-coupled perception-locomotion framework, NeuPAN has two key innovations compared to existing approaches: 1) it directly maps raw points to a learned multi-frame distance space, avoiding error propagation from perception to control; 2) it is interpretable from an end-to-end model-based learning perspective, enabling provable convergence. The crux of NeuPAN is to solve a high-dimensional end-to-end mathematical model with various point-level constraints using the plug-and-play (PnP) proximal alternating-minimization network (PAN) with neurons in the loop. This allows NeuPAN to generate real-time, end-to-end, physically-interpretable motions directly from point clouds, which seamlessly integrates data- and knowledge-engines, where its network parameters are adjusted via back propagation. We evaluate NeuPAN on car-like robot, wheel-legged robot, and passenger autonomous vehicle, in both simulated and real-world environments. Experiments demonstrate that NeuPAN outperforms various benchmarks, in terms of accuracy, efficiency, robustness, and generalization capability across various environments, including the cluttered sandbox, office, corridor, and parking lot. We show that NeuPAN works well in unstructured environments with arbitrary-shape undetectable objects, making impassable ways passable.
Neuromorphic Synergy for Video Binarization
Feb 20, 2024Bimodal objects, such as the checkerboard pattern used in camera calibration, markers for object tracking, and text on road signs, to name a few, are prevalent in our daily lives and serve as a visual form to embed information that can be easily recognized by vision systems. While binarization from intensity images is crucial for extracting the embedded information in the bimodal objects, few previous works consider the task of binarization of blurry images due to the relative motion between the vision sensor and the environment. The blurry images can result in a loss in the binarization quality and thus degrade the downstream applications where the vision system is in motion. Recently, neuromorphic cameras offer new capabilities for alleviating motion blur, but it is non-trivial to first deblur and then binarize the images in a real-time manner. In this work, we propose an event-based binary reconstruction method that leverages the prior knowledge of the bimodal target's properties to perform inference independently in both event space and image space and merge the results from both domains to generate a sharp binary image. We also develop an efficient integration method to propagate this binary image to high frame rate binary video. Finally, we develop a novel method to naturally fuse events and images for unsupervised threshold identification. The proposed method is evaluated in publicly available and our collected data sequence, and shows the proposed method can outperform the SOTA methods to generate high frame rate binary video in real-time on CPU-only devices.
Simultaneous Synchronization and Calibration for Wide-baseline Stereo Event Cameras
Sep 29, 2023Event-based cameras are increasingly utilized in various applications, owing to their high temporal resolution and low power consumption. However, a fundamental challenge arises when deploying multiple such cameras: they operate on independent time systems, leading to temporal misalignment. This misalignment can significantly degrade performance in downstream applications. Traditional solutions, which often rely on hardware-based synchronization, face limitations in compatibility and are impractical for long-distance setups. To address these challenges, we propose a novel algorithm that exploits the motion of objects in the shared field of view to achieve millisecond-level synchronization among multiple event-based cameras. Our method also concurrently estimates extrinsic parameters. We validate our approach in both simulated and real-world indoor/outdoor scenarios, demonstrating successful synchronization and accurate extrinsic parameters estimation.
GRAINS: Proximity Sensing of Objects in Granular Materials
Jul 18, 2023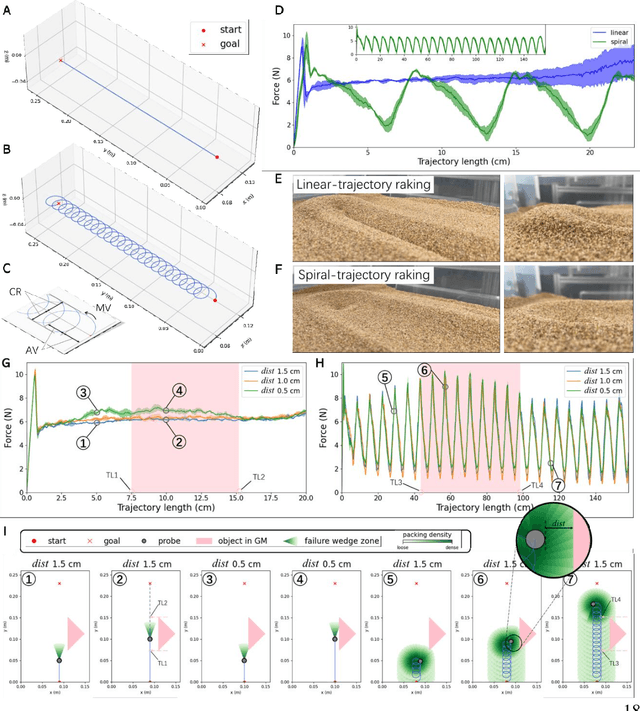
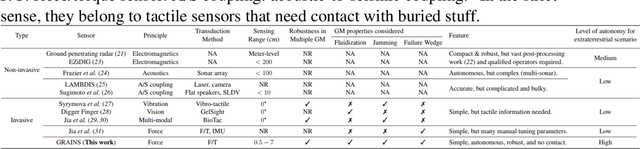
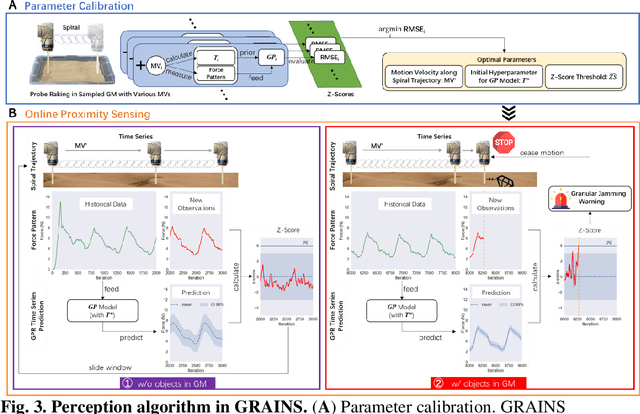
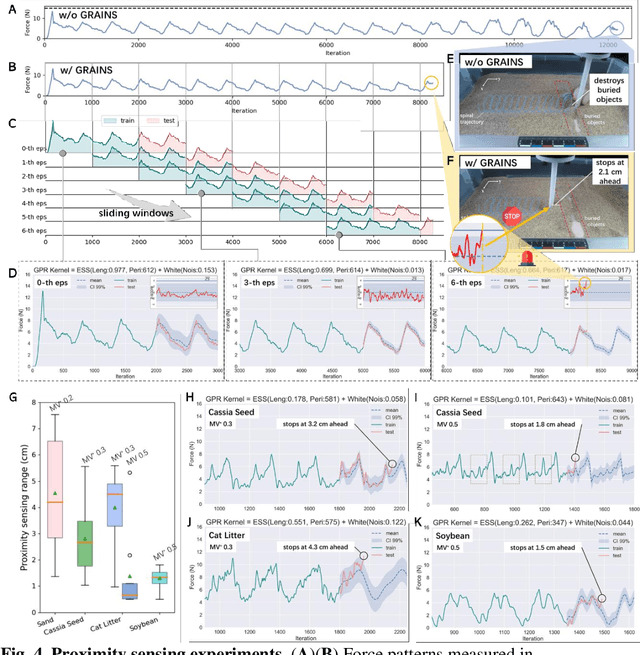
Proximity sensing detects an object's presence without contact. However, research has rarely explored proximity sensing in granular materials (GM) due to GM's lack of visual and complex properties. In this paper, we propose a granular-material-embedded autonomous proximity sensing system (GRAINS) based on three granular phenomena (fluidization, jamming, and failure wedge zone). GRAINS can automatically sense buried objects beneath GM in real-time manner (at least ~20 hertz) and perceive them 0.5 ~ 7 centimeters ahead in different granules without the use of vision or touch. We introduce a new spiral trajectory for the probe raking in GM, combining linear and circular motions, inspired by a common granular fluidization technique. Based on the observation of force-raising when granular jamming occurs in the failure wedge zone in front of the probe during its raking, we employ Gaussian process regression to constantly learn and predict the force patterns and detect the force anomaly resulting from granular jamming to identify the proximity sensing of buried objects. Finally, we apply GRAINS to a Bayesian-optimization-algorithm-guided exploration strategy to successfully localize underground objects and outline their distribution using proximity sensing without contact or digging. This work offers a simple yet reliable method with potential for safe operation in building habitation infrastructure on an alien planet without human intervention.
Fast Event-based Double Integral for Real-time Robotics
May 10, 2023Motion deblurring is a critical ill-posed problem that is important in many vision-based robotics applications. The recently proposed event-based double integral (EDI) provides a theoretical framework for solving the deblurring problem with the event camera and generating clear images at high frame-rate. However, the original EDI is mainly designed for offline computation and does not support real-time requirement in many robotics applications. In this paper, we propose the fast EDI, an efficient implementation of EDI that can achieve real-time online computation on single-core CPU devices, which is common for physical robotic platforms used in practice. In experiments, our method can handle event rates at as high as 13 million event per second in a wide variety of challenging lighting conditions. We demonstrate the benefit on multiple downstream real-time applications, including localization, visual tag detection, and feature matching.
Target-free Extrinsic Calibration of Event-LiDAR Dyad using Edge Correspondences
May 06, 2023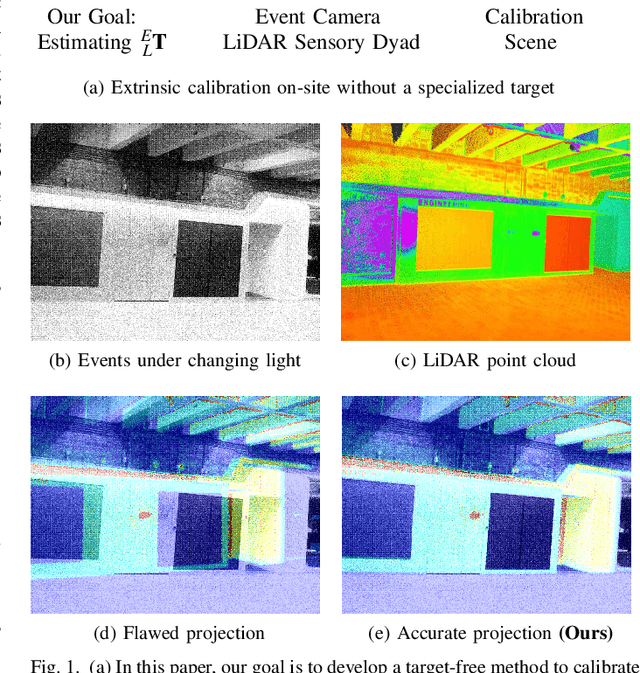
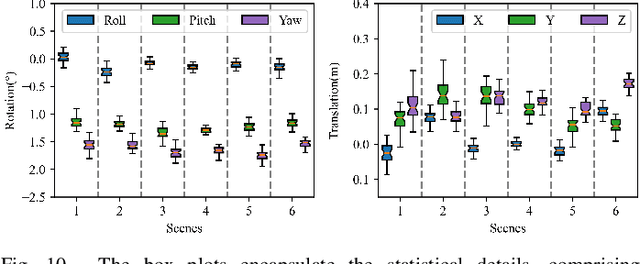
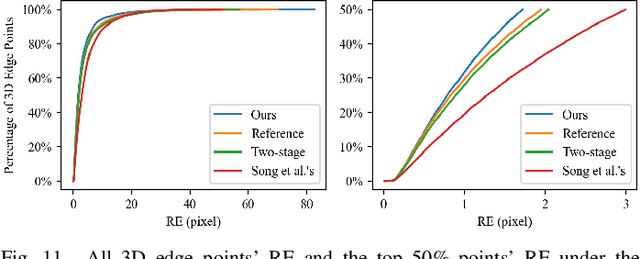

Calibrating the extrinsic parameters of sensory devices is crucial for fusing multi-modal data. Recently, event cameras have emerged as a promising type of neuromorphic sensors, with many potential applications in fields such as mobile robotics and autonomous driving. When combined with LiDAR, they can provide more comprehensive information about the surrounding environment. Nonetheless, due to the distinctive representation of event cameras compared to traditional frame-based cameras, calibrating them with LiDAR presents a significant challenge. In this paper, we propose a novel method to calibrate the extrinsic parameters between a dyad of an event camera and a LiDAR without the need for a calibration board or other equipment. Our approach takes advantage of the fact that when an event camera is in motion, changes in reflectivity and geometric edges in the environment trigger numerous events, which can also be captured by LiDAR. Our proposed method leverages the edges extracted from events and point clouds and correlates them to estimate extrinsic parameters. Experimental results demonstrate that our proposed method is highly robust and effective in various scenes.