 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeNeuPAN: Direct Point Robot Navigation with End-to-End Model-based Learning
Mar 11, 2024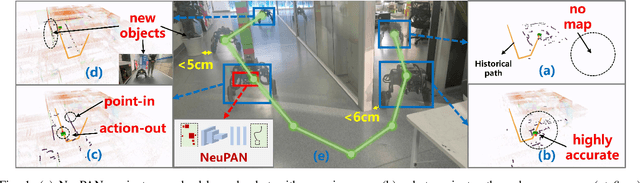

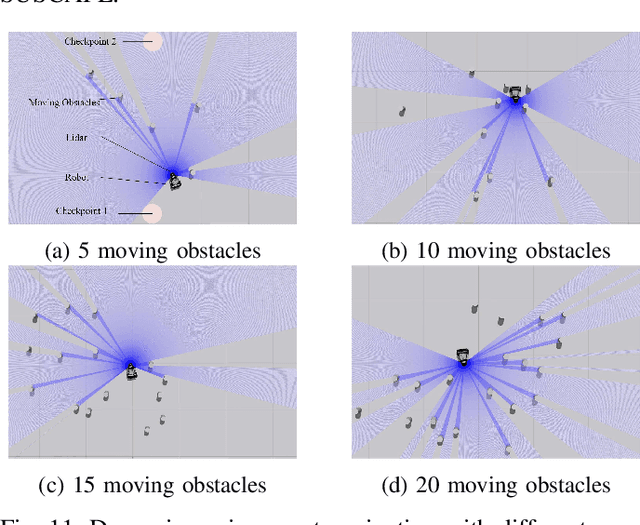
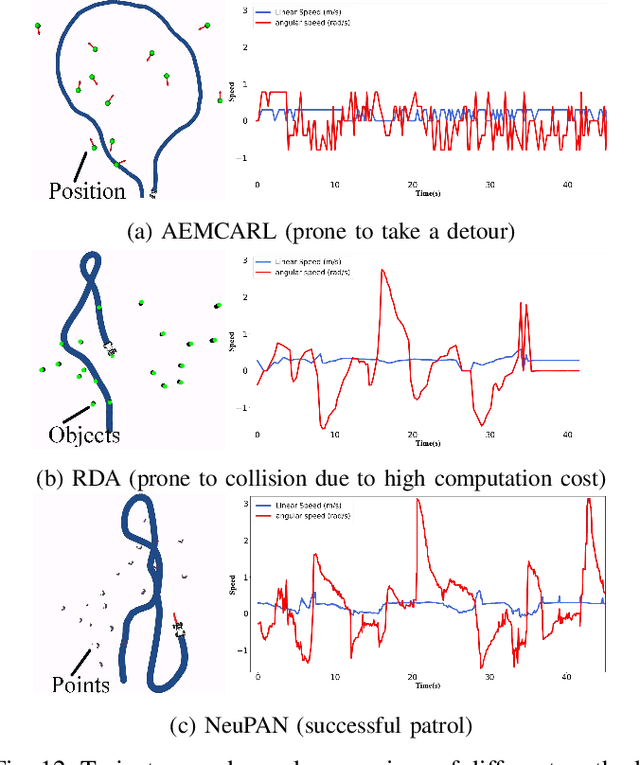
Navigating a nonholonomic robot in a cluttered environment requires extremely accurate perception and locomotion for collision avoidance. This paper presents NeuPAN: a real-time, highly-accurate, map-free, robot-agnostic, and environment-invariant robot navigation solution. Leveraging a tightly-coupled perception-locomotion framework, NeuPAN has two key innovations compared to existing approaches: 1) it directly maps raw points to a learned multi-frame distance space, avoiding error propagation from perception to control; 2) it is interpretable from an end-to-end model-based learning perspective, enabling provable convergence. The crux of NeuPAN is to solve a high-dimensional end-to-end mathematical model with various point-level constraints using the plug-and-play (PnP) proximal alternating-minimization network (PAN) with neurons in the loop. This allows NeuPAN to generate real-time, end-to-end, physically-interpretable motions directly from point clouds, which seamlessly integrates data- and knowledge-engines, where its network parameters are adjusted via back propagation. We evaluate NeuPAN on car-like robot, wheel-legged robot, and passenger autonomous vehicle, in both simulated and real-world environments. Experiments demonstrate that NeuPAN outperforms various benchmarks, in terms of accuracy, efficiency, robustness, and generalization capability across various environments, including the cluttered sandbox, office, corridor, and parking lot. We show that NeuPAN works well in unstructured environments with arbitrary-shape undetectable objects, making impassable ways passable.
RDA: An Accelerated Collision-free Motion Planner for Autonomous Navigation in Cluttered Environments
Oct 01, 2022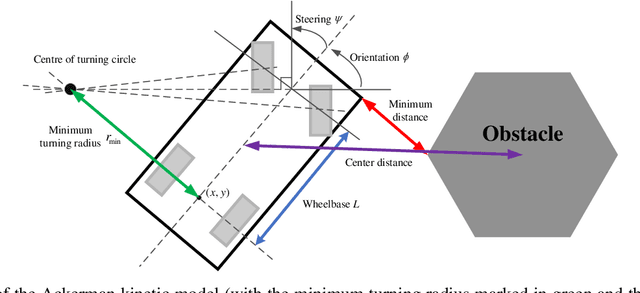

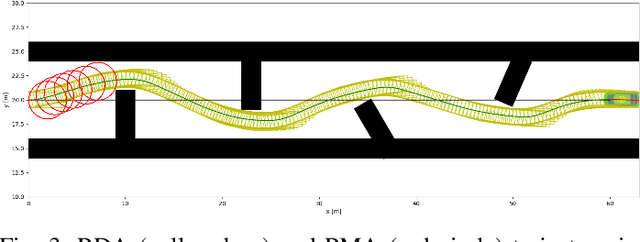

Motion planning is challenging for autonomous systems in multi-obstacle environments due to nonconvex collision avoidance constraints. Directly applying numerical solvers to these nonconvex formulations fails to exploit the constraint structures, resulting in excessive computation time. In this paper, we present an accelerated collision-free motion planner, namely regularized dual alternating direction method of multipliers (RDADMM or RDA for short), for the model predictive control (MPC) based motion planning problem. The proposed RDA addresses nonconvex motion planning via solving a smooth biconvex reformulation via duality and allows the collision avoidance constraints to be computed in parallel for each obstacle to reduce computation time significantly. We validate the performance of the RDA planner through path-tracking experiments with car-like robots in simulation and real world setting. Experimental results show that the proposed methods can generate smooth collision-free trajectories with less computation time compared with other benchmarks and perform robustly in cluttered environments.
Reinforcement Learned Distributed Multi-Robot Navigation with Reciprocal Velocity Obstacle Shaped Rewards
Mar 19, 2022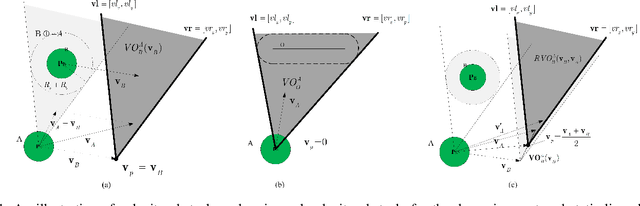
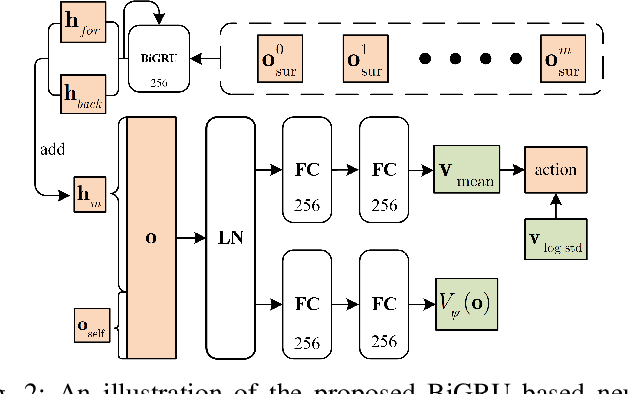
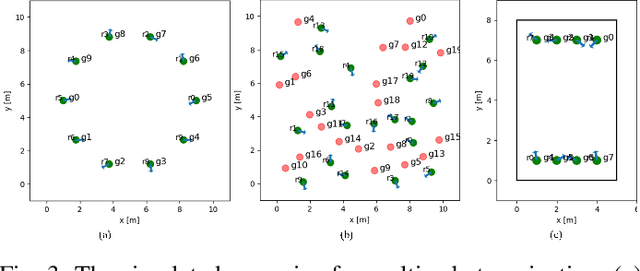
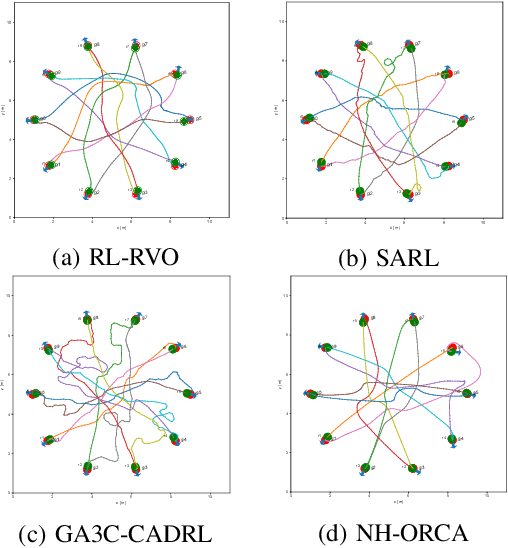
The challenges to solving the collision avoidance problem lie in adaptively choosing optimal robot velocities in complex scenarios full of interactive obstacles. In this paper, we propose a distributed approach for multi-robot navigation which combines the concept of reciprocal velocity obstacle (RVO) and the scheme of deep reinforcement learning (DRL) to solve the reciprocal collision avoidance problem under limited information. The novelty of this work is threefold: (1) using a set of sequential VO and RVO vectors to represent the interactive environmental states of static and dynamic obstacles, respectively; (2) developing a bidirectional recurrent module based neural network, which maps the states of a varying number of surrounding obstacles to the actions directly; (3) developing a RVO area and expected collision time based reward function to encourage reciprocal collision avoidance behaviors and trade off between collision risk and travel time. The proposed policy is trained through simulated scenarios and updated by the actor-critic based DRL algorithm. We validate the policy in complex environments with various numbers of differential drive robots and obstacles. The experiment results demonstrate that our approach outperforms the state-of-art methods and other learning based approaches in terms of the success rate, travel time, and average speed. Source code of this approach is available at https://github.com/hanruihua/rl_rvo_nav.
Adaptive Environment Modeling Based Reinforcement Learning for Collision Avoidance in Complex Scenes
Mar 15, 2022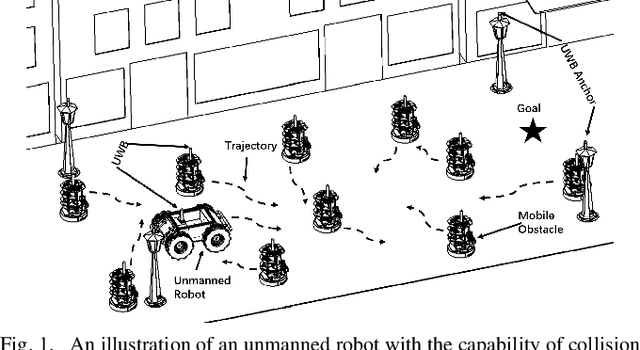
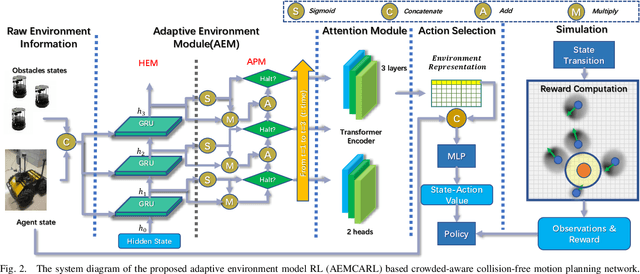
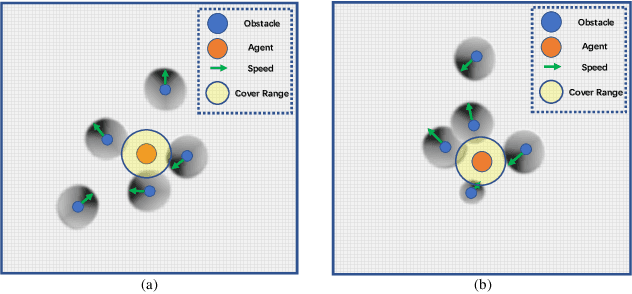
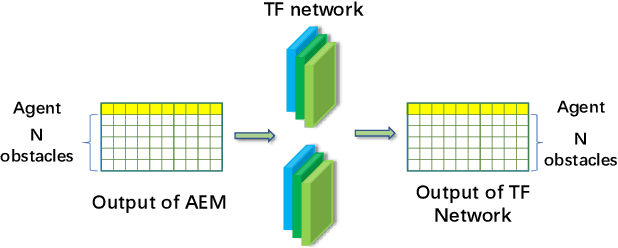
The major challenges of collision avoidance for robot navigation in crowded scenes lie in accurate environment modeling, fast perceptions, and trustworthy motion planning policies. This paper presents a novel adaptive environment model based collision avoidance reinforcement learning (i.e., AEMCARL) framework for an unmanned robot to achieve collision-free motions in challenging navigation scenarios. The novelty of this work is threefold: (1) developing a hierarchical network of gated-recurrent-unit (GRU) for environment modeling; (2) developing an adaptive perception mechanism with an attention module; (3) developing an adaptive reward function for the reinforcement learning (RL) framework to jointly train the environment model, perception function and motion planning policy. The proposed method is tested with the Gym-Gazebo simulator and a group of robots (Husky and Turtlebot) under various crowded scenes. Both simulation and experimental results have demonstrated the superior performance of the proposed method over baseline methods.