 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeReinforcement Learned Distributed Multi-Robot Navigation with Reciprocal Velocity Obstacle Shaped Rewards
Mar 19, 2022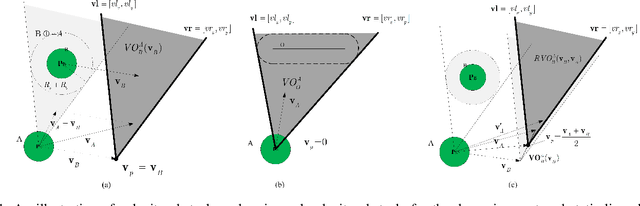
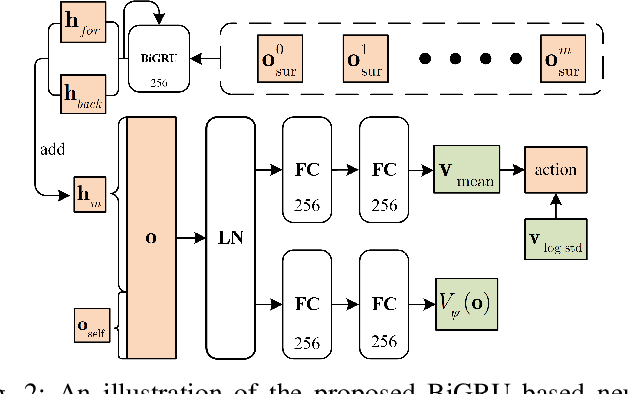
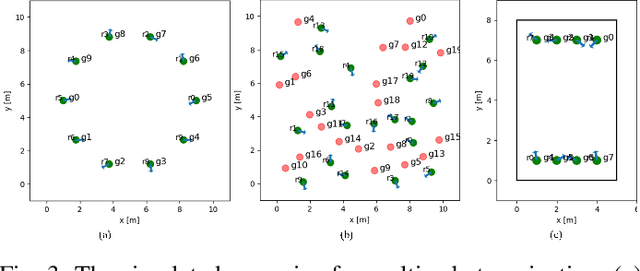
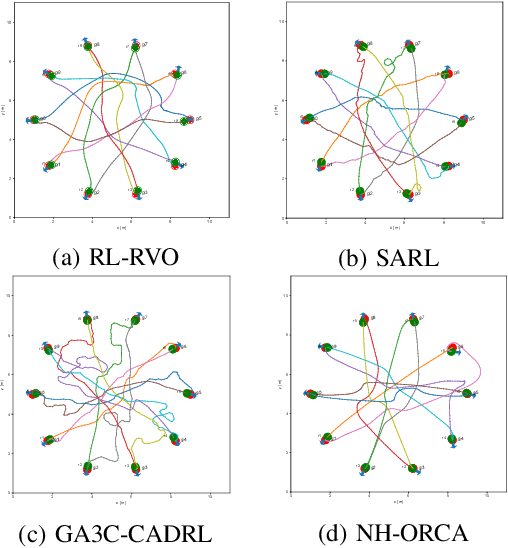
The challenges to solving the collision avoidance problem lie in adaptively choosing optimal robot velocities in complex scenarios full of interactive obstacles. In this paper, we propose a distributed approach for multi-robot navigation which combines the concept of reciprocal velocity obstacle (RVO) and the scheme of deep reinforcement learning (DRL) to solve the reciprocal collision avoidance problem under limited information. The novelty of this work is threefold: (1) using a set of sequential VO and RVO vectors to represent the interactive environmental states of static and dynamic obstacles, respectively; (2) developing a bidirectional recurrent module based neural network, which maps the states of a varying number of surrounding obstacles to the actions directly; (3) developing a RVO area and expected collision time based reward function to encourage reciprocal collision avoidance behaviors and trade off between collision risk and travel time. The proposed policy is trained through simulated scenarios and updated by the actor-critic based DRL algorithm. We validate the policy in complex environments with various numbers of differential drive robots and obstacles. The experiment results demonstrate that our approach outperforms the state-of-art methods and other learning based approaches in terms of the success rate, travel time, and average speed. Source code of this approach is available at https://github.com/hanruihua/rl_rvo_nav.
Adaptive Environment Modeling Based Reinforcement Learning for Collision Avoidance in Complex Scenes
Mar 15, 2022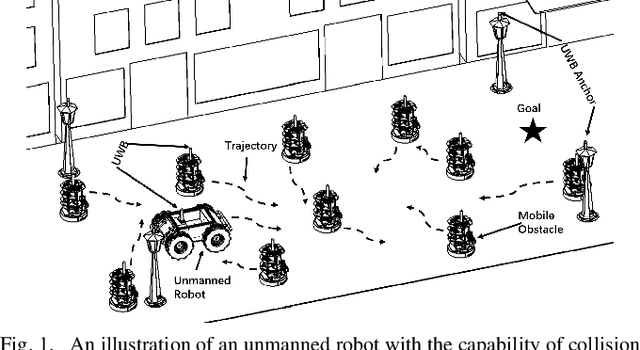
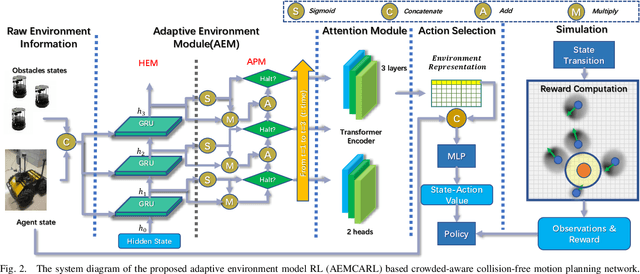
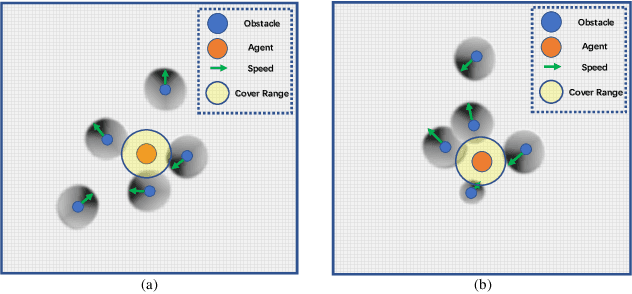
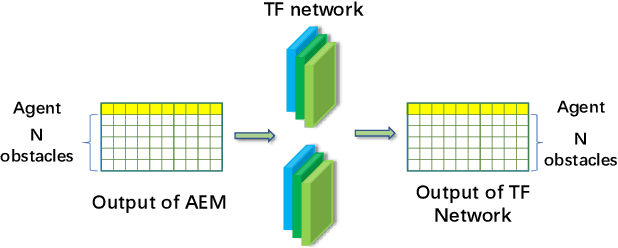
The major challenges of collision avoidance for robot navigation in crowded scenes lie in accurate environment modeling, fast perceptions, and trustworthy motion planning policies. This paper presents a novel adaptive environment model based collision avoidance reinforcement learning (i.e., AEMCARL) framework for an unmanned robot to achieve collision-free motions in challenging navigation scenarios. The novelty of this work is threefold: (1) developing a hierarchical network of gated-recurrent-unit (GRU) for environment modeling; (2) developing an adaptive perception mechanism with an attention module; (3) developing an adaptive reward function for the reinforcement learning (RL) framework to jointly train the environment model, perception function and motion planning policy. The proposed method is tested with the Gym-Gazebo simulator and a group of robots (Husky and Turtlebot) under various crowded scenes. Both simulation and experimental results have demonstrated the superior performance of the proposed method over baseline methods.
Runtime Safety Assurance for Learning-enabled Control of Autonomous Driving Vehicles
Sep 28, 2021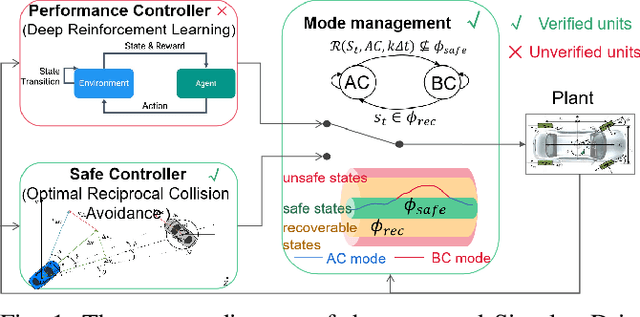
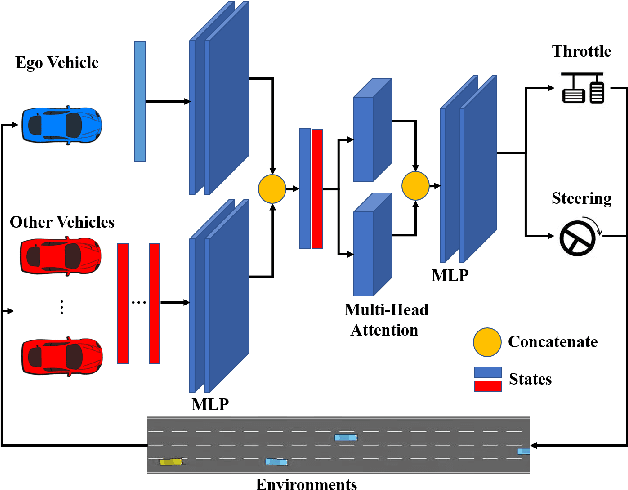

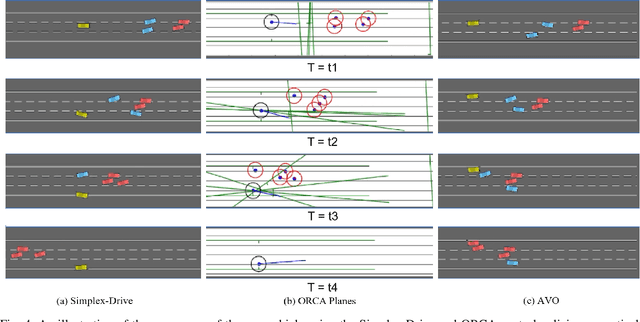
Providing safety guarantees for Autonomous Vehicle (AV) systems with machine-learning-based controllers remains a challenging issue. In this work, we propose Simplex-Drive, a framework that can achieve runtime safety assurance for machine-learning enabled controllers of AVs. The proposed Simplex-Drive consists of an unverified Deep Reinforcement Learning (DRL)-based advanced controller (AC) that achieves desirable performance in complex scenarios, a Velocity-Obstacle (VO) based baseline safe controller (BC) with provably safety guarantees, and a verified mode management unit that monitors the operation status and switches the control authority between AC and BC based on safety-related conditions. We provide a formal correctness proof of Simplex-Drive and conduct a lane-changing case study in dense traffic scenarios. The simulation experiment results demonstrate that Simplex-Drive can always ensure operation safety without sacrificing control performance, even if the DRL policy may lead to deviations from the safe status.
Decentralized Cooperative Multi-Robot Localization with EKF
Nov 19, 2018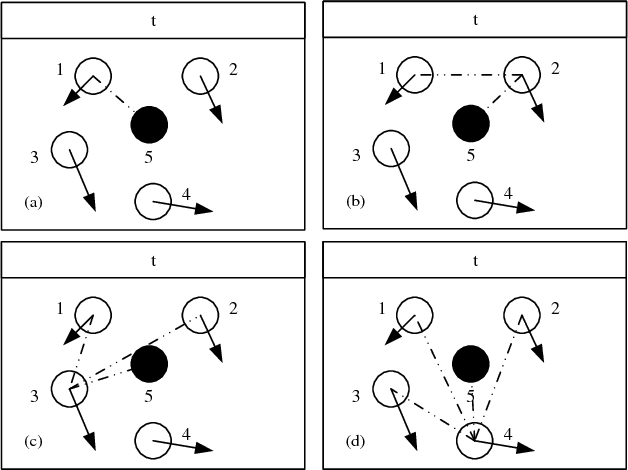
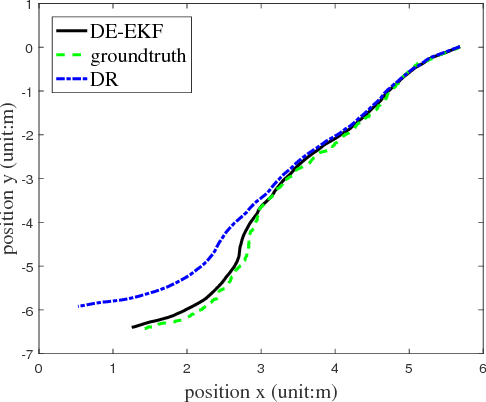

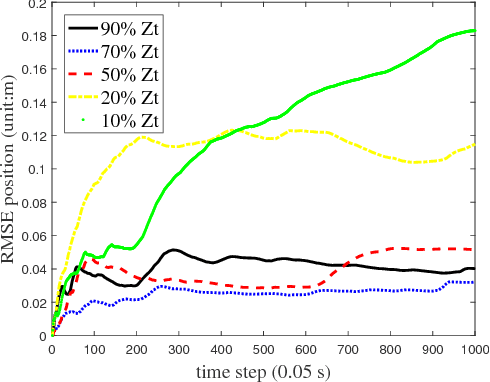
Multi-robot localization has been a critical problem for robots performing complex tasks cooperatively. In this paper, we propose a decentralized approach to localize a group of robots in a large featureless environment. The proposed approach only requires that at least one robot remains stationary as a temporary landmark during a certain period of time. The novelty of our approach is threefold: (1) developing a decentralized scheme that each robot calculates their own state and only stores the latest one to reduce storage and computational cost, (2) developing an efficient localization algorithm through the extended Kalman filter (EKF) that only uses observations of relative pose to estimate the robot positions, (3) developing a scheme has less requirements on landmarks and more robustness against insufficient observations. Various simulations and experiments using five robots equipped with relative pose-measurement sensors are performed to validate the superior performance of our approach.