 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePoint Cloud Registration for Fusion between SPECT MPI and CTA Images
Apr 27, 2026Clinical fusion of Single Photon Emission Computed Tomography Myocardial Perfusion Imaging (SPECT MPI) and Computed Tomography Angiography (CTA) remains limited by cross-modality misregistration and reliance on manual landmarks, which can hinder accurate ischemia localization and lesion-level functional assessment. To address this issue, we propose a registration and fusion framework for SPECT MPI and CTA that integrates functional and structural information for comprehensive cardiac evaluation. The proposed pipeline performs U-Net-based segmentation on both modalities. On SPECT MPI, only the left ventricle (LV) is extracted, and anatomical landmarks are automatically derived from characteristic LV structures. On CTA, both ventricles are segmented, and their spatial relationship is used to automatically define landmarks at the interventricular septal junction. Scale-space consistency preprocessing and landmark-driven coarse registration are applied to mitigate initial misalignment. Based on this initialization, multiple fine registration methods are evaluated on LV epicardial surface point clouds, including ICP, SICP, CPD, CluReg, FFD, and BCPD-plus-plus. The resulting transformations are then propagated to voxel-level resampling for high-precision SPECT-CTA fusion. In a retrospective cohort of 60 patients, the proposed framework preserved sub-millimeter coronary detail from CTA while accurately overlaying quantitative SPECT perfusion. Among the evaluated methods, BCPD-plus-plus achieved the highest accuracy with a mean point cloud distance of 1.7 mm. By combining robust initialization, comparative fine registration, and voxel-level fusion, the proposed approach provides a practical solution for myocardial ischemia localization and functional evaluation of coronary lesions, while remaining independent of any specific fine registration algorithm.
GazeVLA: Learning Human Intention for Robotic Manipulation
Apr 24, 2026Embodied foundation models have achieved significant breakthroughs in robotic manipulation, yet they still depend heavily on large-scale robot demonstrations. Although recent works have explored leveraging human data to alleviate this dependency, effectively extracting transferable knowledge remains a significant challenge due to the inherent embodiment gap between human and robot. We argue that the intention underlying human actions can serve as a powerful intermediate representation for bridging this gap. In this paper, we introduce a novel framework that explicitly learns and transfers human intention to facilitate robotic manipulation. Specifically, we model intention through gaze, as it naturally precedes physical actions and serves as an observable proxy for human intent. Our model is first pretrained on a large-scale egocentric human dataset to capture human intention and its synergy with action, followed by finetuning on a small set of robot and human data. During inference, the model adopts a Chain-of-Thought reasoning paradigm, sequentially predicting intention before executing the action. Extensive evaluations in simulation and real-world settings, across long-horizon and fine-grained tasks, and under few-shot and robustness benchmarks, show that our method consistently outperforms strong baselines, generalizes better, and achieves state-of-the-art performance.
Memory Centric Power Allocation for Multi-Agent Embodied Question Answering
Apr 20, 2026This paper considers multi-agent embodied question answering (MA-EQA), which aims to query robot teams on what they have seen over a long horizon. In contrast to existing edge resource management methods that emphasize sensing, communication, or computation performance metrics, MA-EQA emphasizes the memory qualities. To cope with this paradigm shift, we propose a quality of memory (QoM) model based on generative adversarial exam (GAE), which leverages forward simulation to assess memory retrieval and uses the resulting exam scores to compute QoM values. Then we propose memory centric power allocation (MCPA), which maximizes the QoM function under communication resource constraints. Through asymptotic analysis, it is found that the transmit powers are proportional to the GAE error probability, thus prioritizing towards high-QoM robots. Extensive experiments demonstrate that MCPA achieves significant improvements over extensive benchmarks in terms of diverse metrics in various scenarios.
Direct Contact-Tolerant Motion Planning With Vision Language Models
Mar 05, 2026Navigation in cluttered environments often requires robots to tolerate contact with movable or deformable objects to maintain efficiency. Existing contact-tolerant motion planning (CTMP) methods rely on indirect spatial representations (e.g., prebuilt map, obstacle set), resulting in inaccuracies and a lack of adaptiveness to environmental uncertainties. To address this issue, we propose a direct contact-tolerant (DCT) planner, which integrates vision-language models (VLMs) into direct point perception and navigation, including two key components. The first one is VLM point cloud partitioner (VPP), which performs contact-tolerance reasoning in image space using VLM, caches inference masks, propagates them across frames using odometry, and projects them onto the current scan to generate a contact-aware point cloud. The second innovation is VPP guided navigation (VGN), which formulates CTMP as a perception-to-control optimization problem under direct contact-aware point cloud constraints, which is further solved by a specialized deep neural network (DNN). We implement DCT in Isaac Sim and a real car-like robot, demonstrating that DCT achieves robust and efficient navigation in cluttered environments with movable obstacles, outperforming representative baselines across diverse metrics. The code is available at: https://github.com/ChrisLeeUM/DCT.
Agentic Self-Evolutionary Replanning for Embodied Navigation
Mar 03, 2026Failure is inevitable for embodied navigation in complex environments. To enhance the resilience, replanning (RP) is a viable option, where the robot is allowed to fail, but is capable of adjusting plan until success. However, existing RP approaches freeze the ego action model and miss the opportunities to explore better plans by upgrading the robot itself. To address this limitation, we propose Self-Evolutionary RePlanning, or SERP for short, which leads to a paradigm shift from frozen models towards evolving models by run-time learning from recent experiences. In contrast to existing model evolution approaches that often get stuck at predefined static parameters, we introduce agentic self-evolving action model that uses in-context learning with auto-differentiation (ILAD) for adaptive function adjustment and global parameter reset. To achieve token-efficient replanning for SERP, we also propose graph chain-of-thought (GCOT) replanning with large language model (LLM) inference over distilled graphs. Extensive simulation and real-world experiments demonstrate that SERP achieves higher success rate with lower token expenditure over various benchmarks, validating its superior robustness and efficiency across diverse environments.
HPTune: Hierarchical Proactive Tuning for Collision-Free Model Predictive Control
Jan 29, 2026Parameter tuning is a powerful approach to enhance adaptability in model predictive control (MPC) motion planners. However, existing methods typically operate in a myopic fashion that only evaluates executed actions, leading to inefficient parameter updates due to the sparsity of failure events (e.g., obstacle nearness or collision). To cope with this issue, we propose to extend evaluation from executed to non-executed actions, yielding a hierarchical proactive tuning (HPTune) framework that combines both a fast-level tuning and a slow-level tuning. The fast one adopts risk indicators of predictive closing speed and predictive proximity distance, and the slow one leverages an extended evaluation loss for closed-loop backpropagation. Additionally, we integrate HPTune with the Doppler LiDAR that provides obstacle velocities apart from position-only measurements for enhanced motion predictions, thus facilitating the implementation of HPTune. Extensive experiments on high-fidelity simulator demonstrate that HPTune achieves efficient MPC tuning and outperforms various baseline schemes in complex environments. It is found that HPTune enables situation-tailored motion planning by formulating a safe, agile collision avoidance strategy.
GenDet: Painting Colored Bounding Boxes on Images via Diffusion Model for Object Detection
Jan 12, 2026This paper presents GenDet, a novel framework that redefines object detection as an image generation task. In contrast to traditional approaches, GenDet adopts a pioneering approach by leveraging generative modeling: it conditions on the input image and directly generates bounding boxes with semantic annotations in the original image space. GenDet establishes a conditional generation architecture built upon the large-scale pre-trained Stable Diffusion model, formulating the detection task as semantic constraints within the latent space. It enables precise control over bounding box positions and category attributes, while preserving the flexibility of the generative model. This novel methodology effectively bridges the gap between generative models and discriminative tasks, providing a fresh perspective for constructing unified visual understanding systems. Systematic experiments demonstrate that GenDet achieves competitive accuracy compared to discriminative detectors, while retaining the flexibility characteristic of generative methods.
FaceRefiner: High-Fidelity Facial Texture Refinement with Differentiable Rendering-based Style Transfer
Jan 08, 2026Recent facial texture generation methods prefer to use deep networks to synthesize image content and then fill in the UV map, thus generating a compelling full texture from a single image. Nevertheless, the synthesized texture UV map usually comes from a space constructed by the training data or the 2D face generator, which limits the methods' generalization ability for in-the-wild input images. Consequently, their facial details, structures and identity may not be consistent with the input. In this paper, we address this issue by proposing a style transfer-based facial texture refinement method named FaceRefiner. FaceRefiner treats the 3D sampled texture as style and the output of a texture generation method as content. The photo-realistic style is then expected to be transferred from the style image to the content image. Different from current style transfer methods that only transfer high and middle level information to the result, our style transfer method integrates differentiable rendering to also transfer low level (or pixel level) information in the visible face regions. The main benefit of such multi-level information transfer is that, the details, structures and semantics in the input can thus be well preserved. The extensive experiments on Multi-PIE, CelebA and FFHQ datasets demonstrate that our refinement method can improve the texture quality and the face identity preserving ability, compared with state-of-the-arts.
C-DGPA: Class-Centric Dual-Alignment Generative Prompt Adaptation
Dec 18, 2025Unsupervised Domain Adaptation transfers knowledge from a labeled source domain to an unlabeled target domain. Directly deploying Vision-Language Models (VLMs) with prompt tuning in downstream UDA tasks faces the signifi cant challenge of mitigating domain discrepancies. Existing prompt-tuning strategies primarily align marginal distribu tion, but neglect conditional distribution discrepancies, lead ing to critical issues such as class prototype misalignment and degraded semantic discriminability. To address these lim itations, the work proposes C-DGPA: Class-Centric Dual Alignment Generative Prompt Adaptation. C-DGPA syner gistically optimizes marginal distribution alignment and con ditional distribution alignment through a novel dual-branch architecture. The marginal distribution alignment branch em ploys a dynamic adversarial training framework to bridge marginal distribution discrepancies. Simultaneously, the con ditional distribution alignment branch introduces a Class Mapping Mechanism (CMM) to align conditional distribu tion discrepancies by standardizing semantic prompt under standing and preventing source domain over-reliance. This dual alignment strategy effectively integrates domain knowl edge into prompt learning via synergistic optimization, ensur ing domain-invariant and semantically discriminative repre sentations. Extensive experiments on OfficeHome, Office31, and VisDA-2017 validate the superiority of C-DGPA. It achieves new state-of-the-art results on all benchmarks.
Myocardial Region-guided Feature Aggregation Net for Automatic Coronary artery Segmentation and Stenosis Assessment using Coronary Computed Tomography Angiography
Apr 27, 2025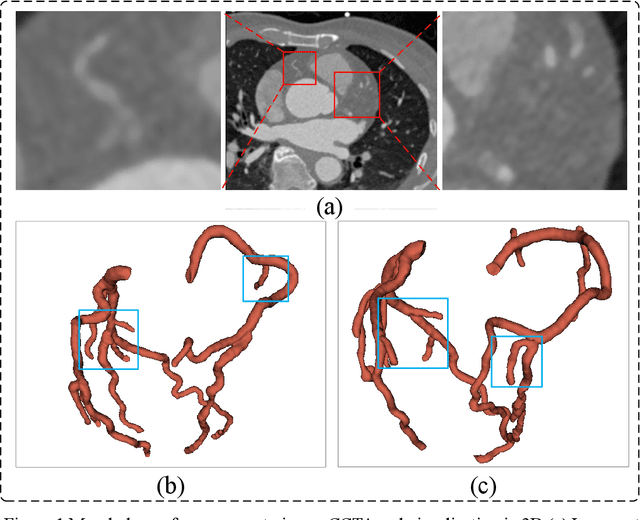
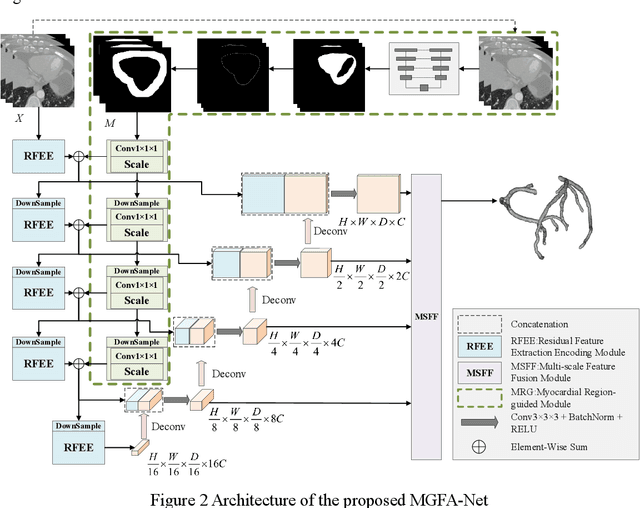
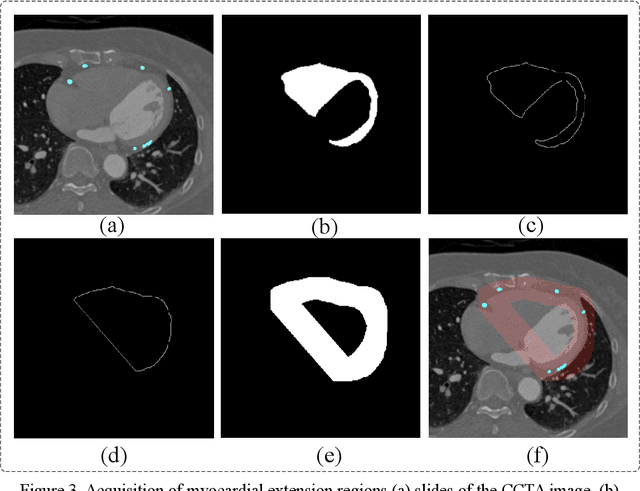
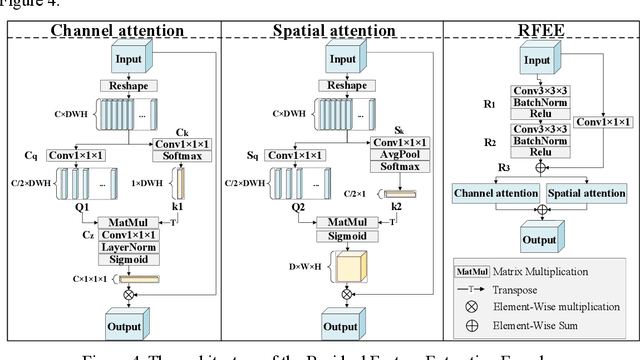
Coronary artery disease (CAD) remains a leading cause of mortality worldwide, requiring accurate segmentation and stenosis detection using Coronary Computed Tomography angiography (CCTA). Existing methods struggle with challenges such as low contrast, morphological variability and small vessel segmentation. To address these limitations, we propose the Myocardial Region-guided Feature Aggregation Net, a novel U-shaped dual-encoder architecture that integrates anatomical prior knowledge to enhance robustness in coronary artery segmentation. Our framework incorporates three key innovations: (1) a Myocardial Region-guided Module that directs attention to coronary regions via myocardial contour expansion and multi-scale feature fusion, (2) a Residual Feature Extraction Encoding Module that combines parallel spatial channel attention with residual blocks to enhance local-global feature discrimination, and (3) a Multi-scale Feature Fusion Module for adaptive aggregation of hierarchical vascular features. Additionally, Monte Carlo dropout f quantifies prediction uncertainty, supporting clinical interpretability. For stenosis detection, a morphology-based centerline extraction algorithm separates the vascular tree into anatomical branches, enabling cross-sectional area quantification and stenosis grading. The superiority of MGFA-Net was demonstrated by achieving an Dice score of 85.04%, an accuracy of 84.24%, an HD95 of 6.1294 mm, and an improvement of 5.46% in true positive rate for stenosis detection compared to3D U-Net. The integrated segmentation-to-stenosis pipeline provides automated, clinically interpretable CAD assessment, bridging deep learning with anatomical prior knowledge for precision medicine. Our code is publicly available at http://github.com/chenzhao2023/MGFA_CCTA