 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDialogue Director: Bridging the Gap in Dialogue Visualization for Multimodal Storytelling
Dec 30, 2024



Recent advances in AI-driven storytelling have enhanced video generation and story visualization. However, translating dialogue-centric scripts into coherent storyboards remains a significant challenge due to limited script detail, inadequate physical context understanding, and the complexity of integrating cinematic principles. To address these challenges, we propose Dialogue Visualization, a novel task that transforms dialogue scripts into dynamic, multi-view storyboards. We introduce Dialogue Director, a training-free multimodal framework comprising a Script Director, Cinematographer, and Storyboard Maker. This framework leverages large multimodal models and diffusion-based architectures, employing techniques such as Chain-of-Thought reasoning, Retrieval-Augmented Generation, and multi-view synthesis to improve script understanding, physical context comprehension, and cinematic knowledge integration. Experimental results demonstrate that Dialogue Director outperforms state-of-the-art methods in script interpretation, physical world understanding, and cinematic principle application, significantly advancing the quality and controllability of dialogue-based story visualization.
DNPM: A Neural Parametric Model for the Synthesis of Facial Geometric Details
May 30, 2024



Parametric 3D models have enabled a wide variety of computer vision and graphics tasks, such as modeling human faces, bodies and hands. In 3D face modeling, 3DMM is the most widely used parametric model, but can't generate fine geometric details solely from identity and expression inputs. To tackle this limitation, we propose a neural parametric model named DNPM for the facial geometric details, which utilizes deep neural network to extract latent codes from facial displacement maps encoding details and wrinkles. Built upon DNPM, a novel 3DMM named Detailed3DMM is proposed, which augments traditional 3DMMs by including the synthesis of facial details only from the identity and expression inputs. Moreover, we show that DNPM and Detailed3DMM can facilitate two downstream applications: speech-driven detailed 3D facial animation and 3D face reconstruction from a degraded image. Extensive experiments have shown the usefulness of DNPM and Detailed3DMM, and the progressiveness of two proposed applications.
Learn2Talk: 3D Talking Face Learns from 2D Talking Face
Apr 19, 2024



Speech-driven facial animation methods usually contain two main classes, 3D and 2D talking face, both of which attract considerable research attention in recent years. However, to the best of our knowledge, the research on 3D talking face does not go deeper as 2D talking face, in the aspect of lip-synchronization (lip-sync) and speech perception. To mind the gap between the two sub-fields, we propose a learning framework named Learn2Talk, which can construct a better 3D talking face network by exploiting two expertise points from the field of 2D talking face. Firstly, inspired by the audio-video sync network, a 3D sync-lip expert model is devised for the pursuit of lip-sync between audio and 3D facial motion. Secondly, a teacher model selected from 2D talking face methods is used to guide the training of the audio-to-3D motions regression network to yield more 3D vertex accuracy. Extensive experiments show the advantages of the proposed framework in terms of lip-sync, vertex accuracy and speech perception, compared with state-of-the-arts. Finally, we show two applications of the proposed framework: audio-visual speech recognition and speech-driven 3D Gaussian Splatting based avatar animation.
Modeling Spatial Nonstationarity via Deformable Convolutions for Deep Traffic Flow Prediction
Jan 08, 2021



Deep neural networks are being increasingly used for short-term traffic flow prediction. Existing convolution-based approaches typically partition an underlying territory into grid-like spatial units, and employ standard convolutions to learn spatial dependence among the units. However, standard convolutions with fixed geometric structures cannot fully model the nonstationary characteristics of local traffic flows. To overcome the deficiency, we introduce deformable convolution that augments the spatial sampling locations with additional offsets, to enhance the modeling capability of spatial nonstationarity. On this basis, we design a deep deformable convolutional residual network, namely DeFlow-Net, that can effectively model global spatial dependence, local spatial nonstationarity, and temporal periodicity of traffic flows. Furthermore, to fit better with convolutions, we suggest to first aggregate traffic flows according to pre-conceived regions of interest, then dispose to sequentially organized raster images for network input. Extensive experiments on real-world traffic flows demonstrate that DeFlow-Net outperforms existing solutions using standard convolutions, and spatial partition by pre-conceived regions further enhances the performance. Finally, we demonstrate the advantage of DeFlow-Net in maintaining spatial autocorrelation, and reveal the impacts of partition shapes and scales on deep traffic flow prediction.
Revisiting the Modifiable Areal Unit Problem in Deep Traffic Prediction with Visual Analytics
Sep 07, 2020
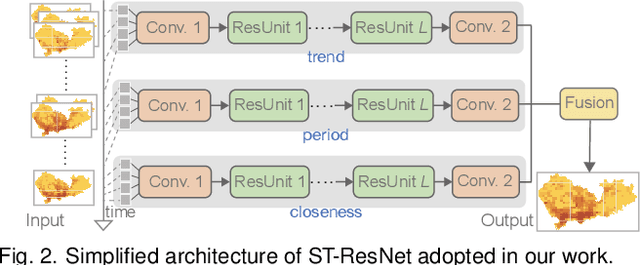
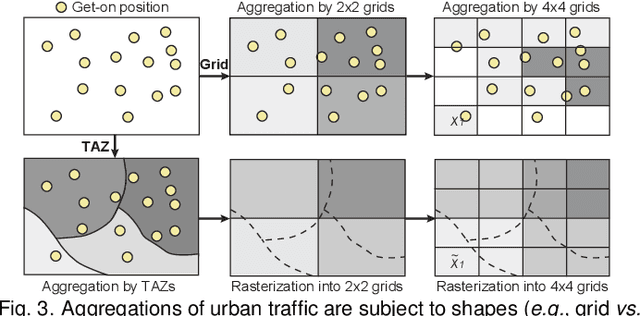
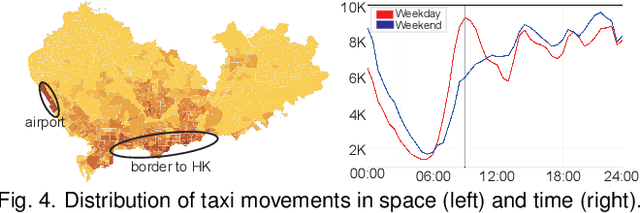
Deep learning methods are being increasingly used for urban traffic prediction where spatiotemporal traffic data is aggregated into sequentially organized matrices that are then fed into convolution-based residual neural networks. However, the widely known modifiable areal unit problem within such aggregation processes can lead to perturbations in the network inputs. This issue can significantly destabilize the feature embeddings and the predictions, rendering deep networks much less useful for the experts. This paper approaches this challenge by leveraging unit visualization techniques that enable the investigation of many-to-many relationships between dynamically varied multi-scalar aggregations of urban traffic data and neural network predictions. Through regular exchanges with a domain expert, we design and develop a visual analytics solution that integrates 1) a Bivariate Map equipped with an advanced bivariate colormap to simultaneously depict input traffic and prediction errors across space, 2) a Morans I Scatterplot that provides local indicators of spatial association analysis, and 3) a Multi-scale Attribution View that arranges non-linear dot plots in a tree layout to promote model analysis and comparison across scales. We evaluate our approach through a series of case studies involving a real-world dataset of Shenzhen taxi trips, and through interviews with domain experts. We observe that geographical scale variations have important impact on prediction performances, and interactive visual exploration of dynamically varying inputs and outputs benefit experts in the development of deep traffic prediction models.